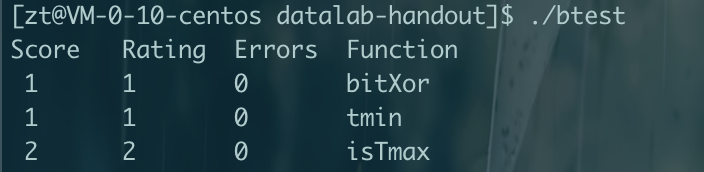
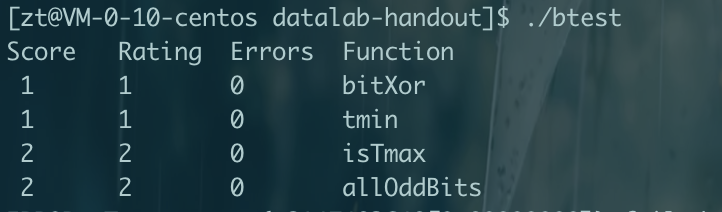
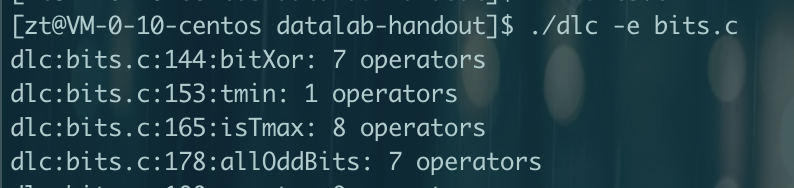
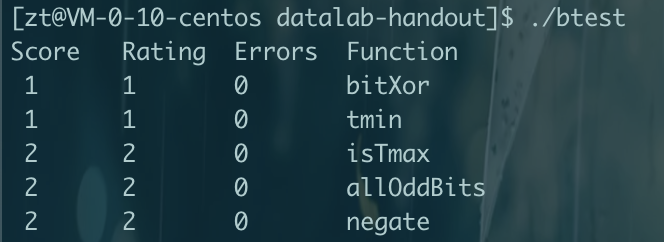
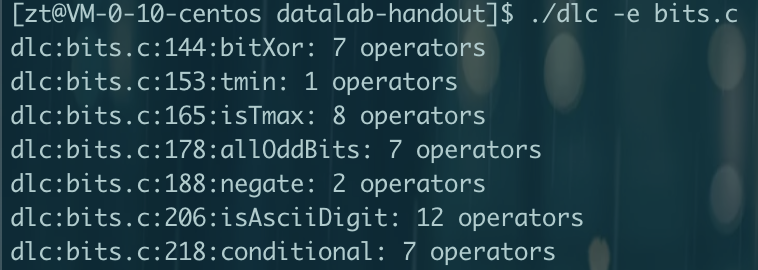
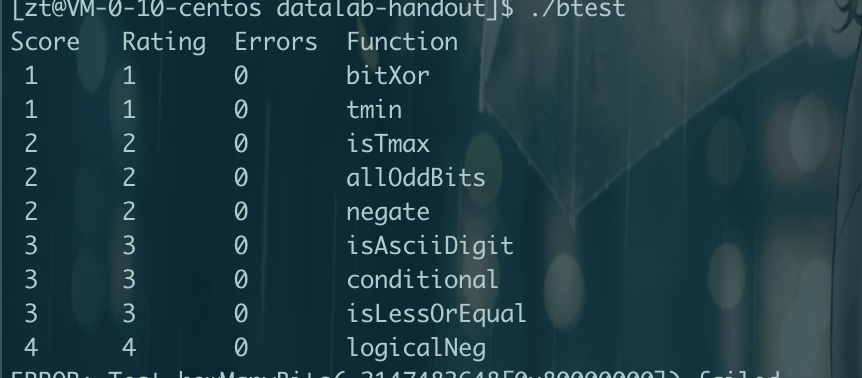
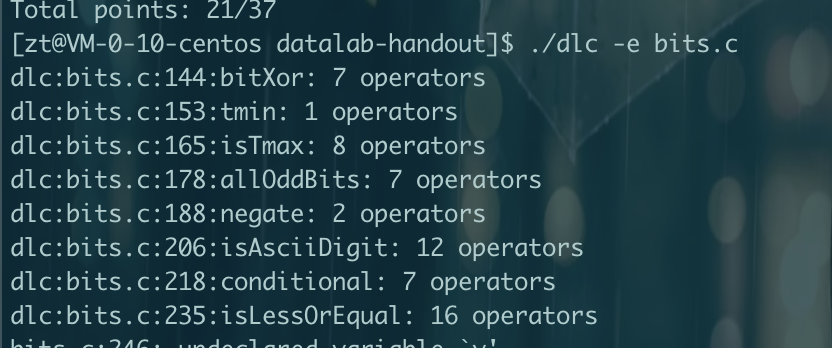
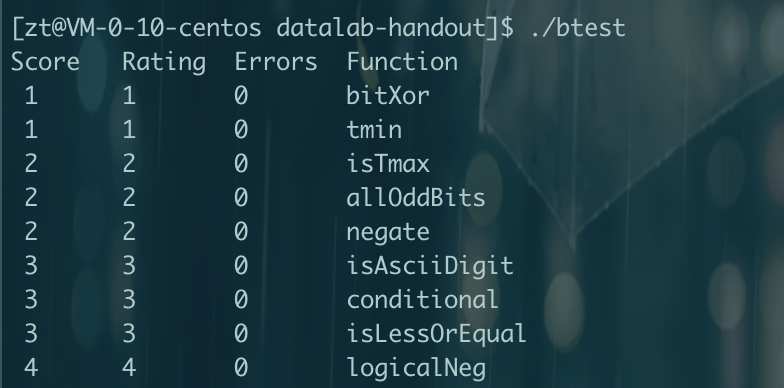
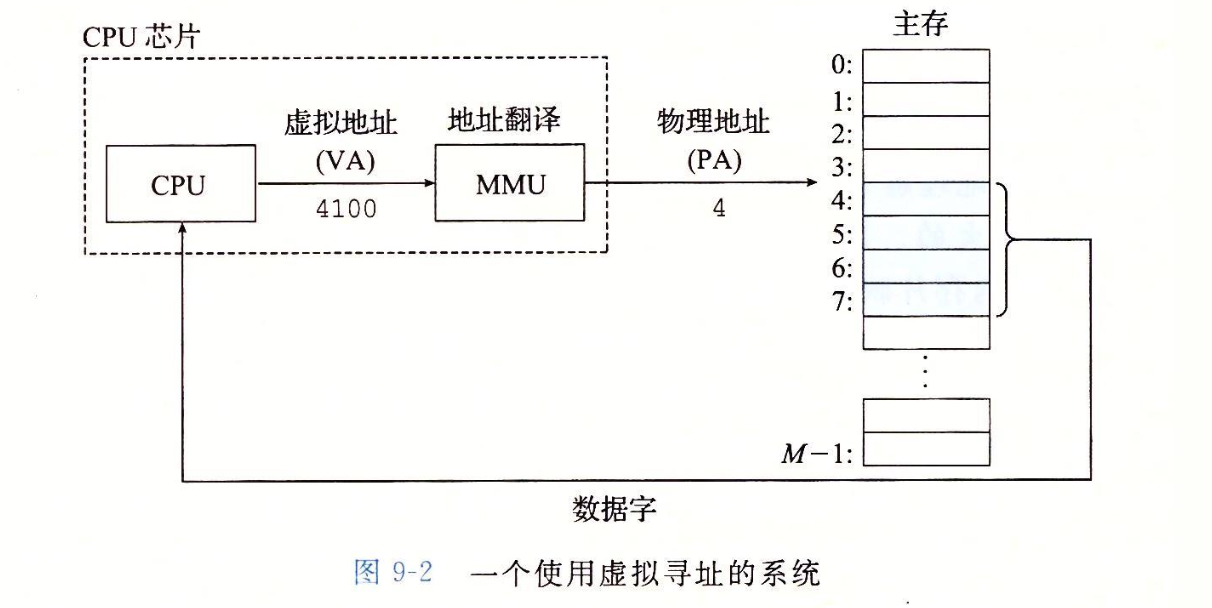
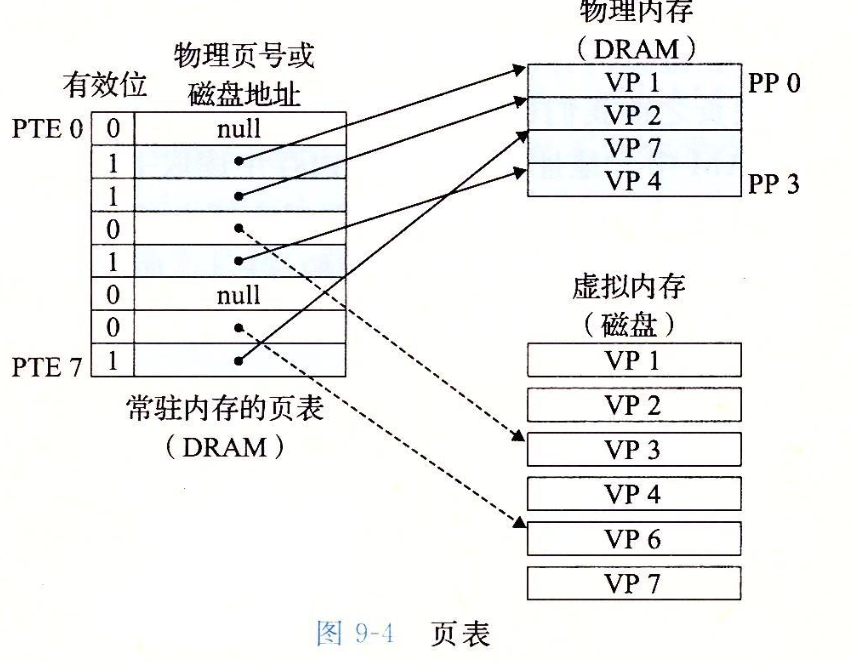
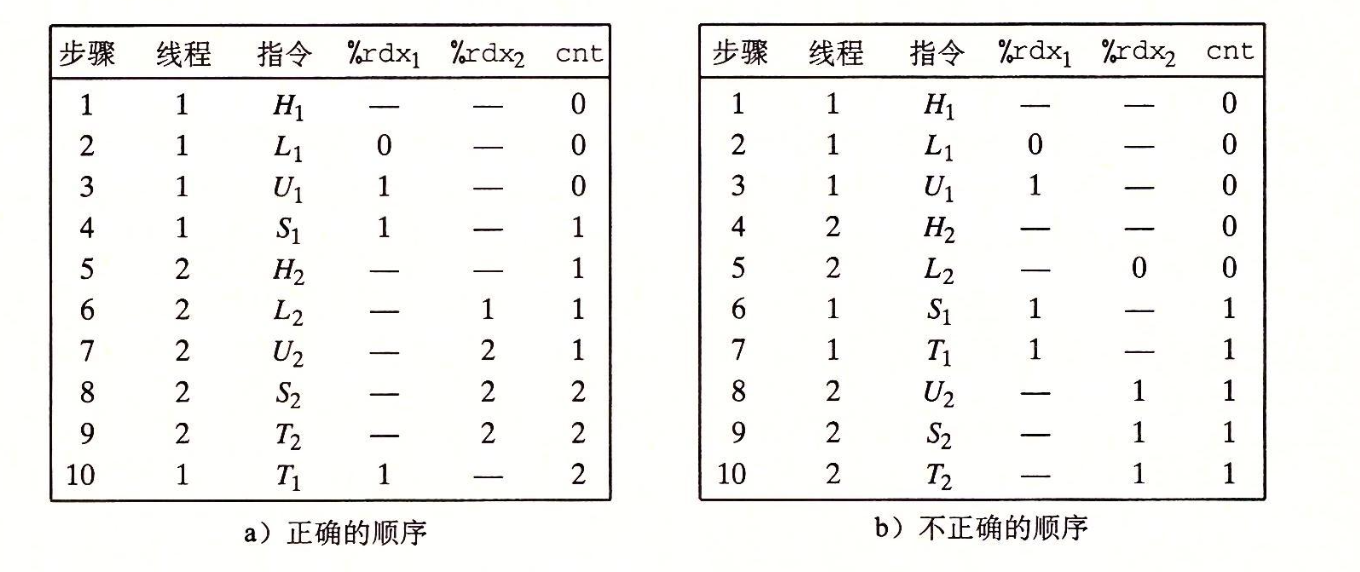
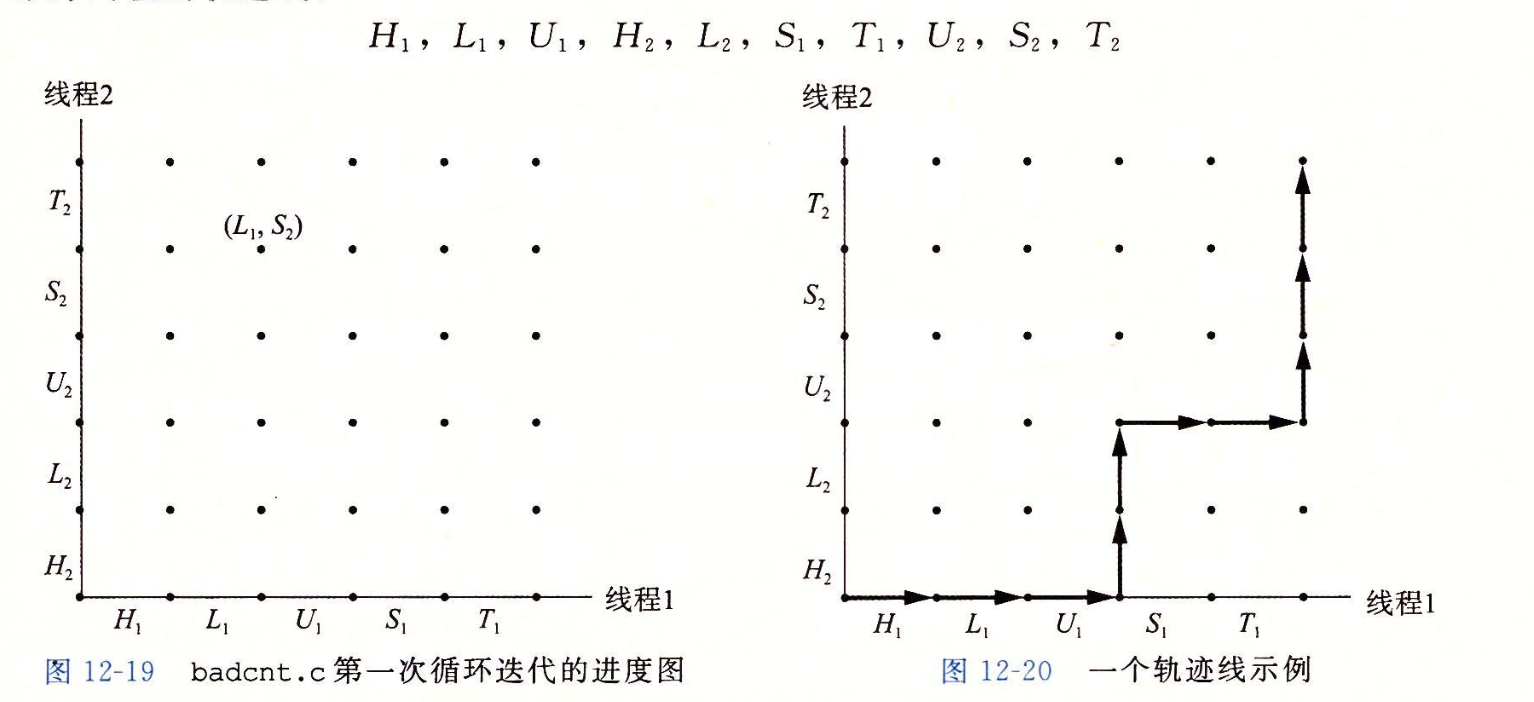
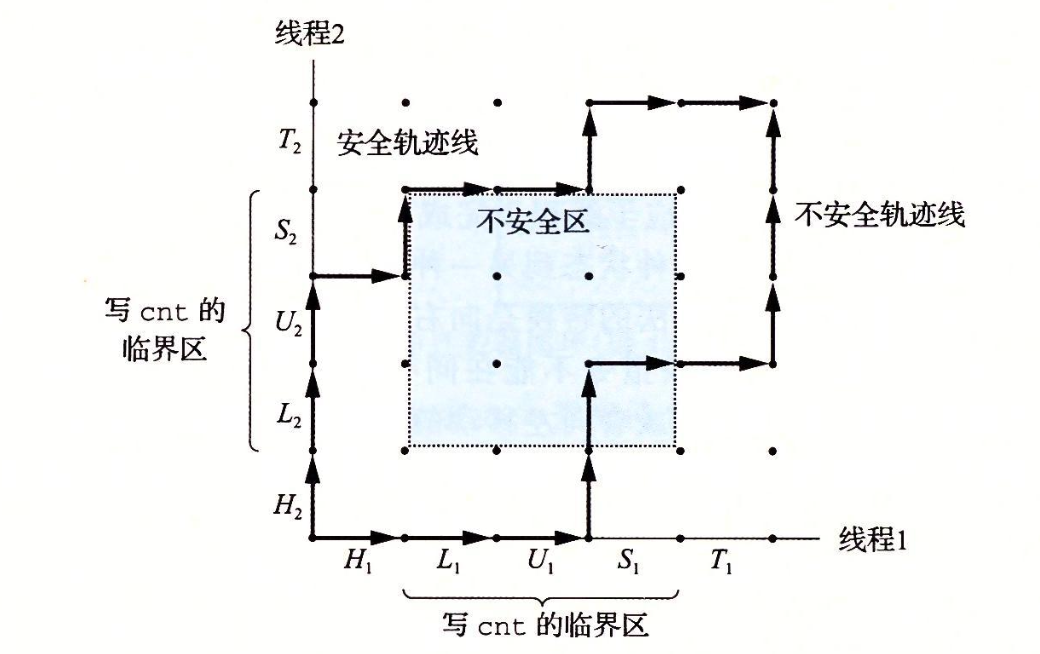
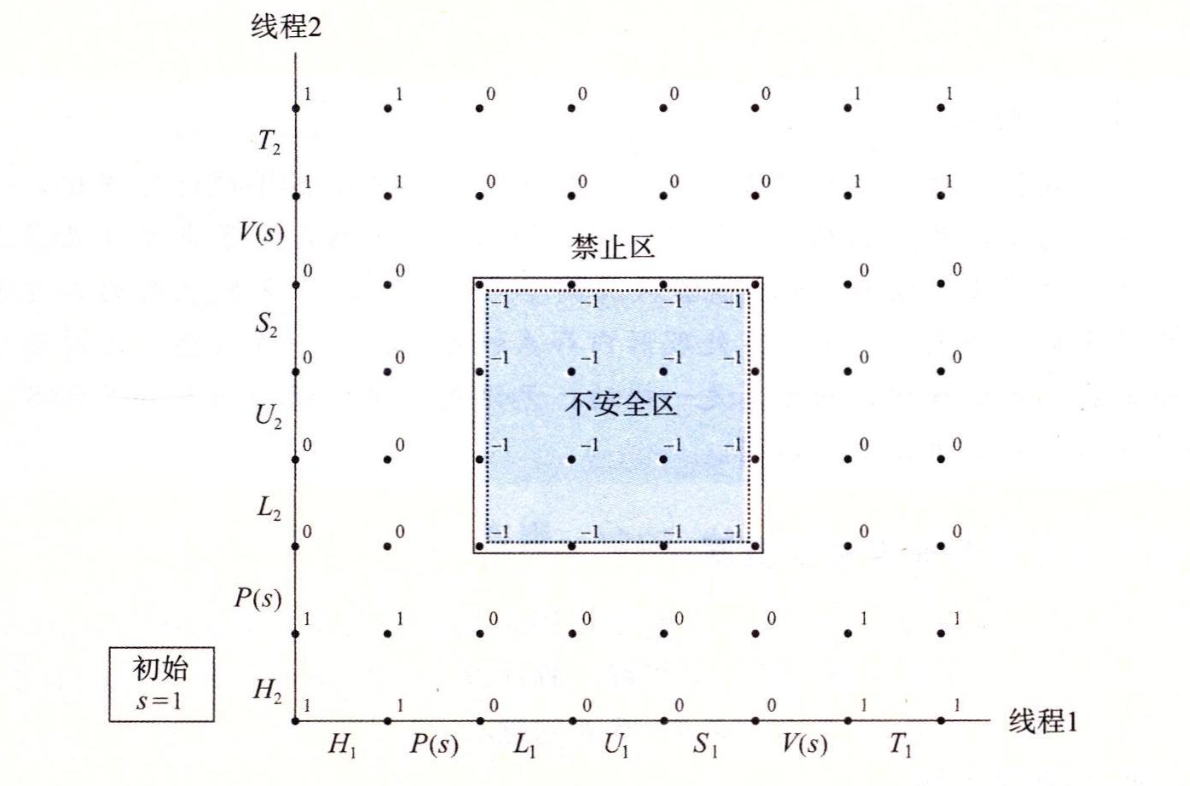
CMU15445笔记 数据库 数据库就是管理文件的一个程序。将文件管理抽象出来不同的结构,如关系数据库,文档数据库,图数据库等。方便管理,使用,并能进行复杂的操作,如事务等。更加通用使任何语言都可以使用。对于多个进程并发修改一个文件,那么数据库可以提供更好的性能和解决方案。
数据模型
关系模型:大多数数据库使用的
键值对模型:NOSql使用的,比如redis
图模型:NOSql使用的
文档模型:NOSql使用的,比如mongoDB
列存储模型
数组,向量模型:向量数据库,如Fassi
分组模型,网络模型,多值模型:已经很少使用的模型
关系模型 Ted Codd在1969年设计了关系模型。发表了A relational model of data for large shared data banks
关系模型将物理层和逻辑层分离,当数据的内部表示发生变化时,甚至当外部表示的某些方面发生变化时,用户在终端和大多数应用程序上的活动应该不受影响。
关系模型提供了一种仅用数据的自然结构来描述数据的方法,因此,它为高级数据语言提供了一个基础,这种语言将一方面在程序之间产生最大的独立性,另一方面在机器表示和数据组织之间产生最大的独立性。另一个优点是,它为处理关系的可导出性、冗余性和一致性提供了坚实的基础。
仍然需要消除的三种主要数据依赖是:顺序依赖、索引依赖和访问路径依赖。
顺序依赖:程序展示的顺序和文件内容的存储顺序并不一致,需要各自独立。
索引依赖:如果程序使用索引的时候,索引被删除那么程序将出错。
访问路径依赖:访问数据的时候依赖数据的物理结构。
关系指的是数学意义上的关系,对于给定集合S1,S2,S3…Sn,R是n个集合上的关系,如果它是n个元组的集合,每个元组的第一个元素来自S1,第二个来自S2,以此类推。我们称Sj是R上的第j个定义域。R的阶为n(degree n),阶为1的时候称为一元关系,2的时候称为二元关系,阶为n称为n元关系。
关键原则:
将数据存储在简单的数据结构(关系)中
物理存储留给DBMS实现
通过高级语言访问数据,DBMS确定最佳策略。
结构采用关系。确保数据库内容满足完整性约束。程序通过接口来访问和修改数据库内容。
关系是无序的,n元关系就是n个列的表。一个元组是一行记录。
高级SQL PostegreSQL:由伯克利大学开发,是之前开发Ingres的人开发的。
IBM的DB2支持SQL,所以SQL成为了标准。
数据库支持SQL,最低要支持SQL-92标准。
下面的sql在postgreSQL中会报错,mysql中如果sql_mode是ansi也会报错,如果sql_mode是traditional就不会报错,而是会随机选一个cid展示出来。
1 2 select avg (s.gpa), e.cid from enrolled as e,student as swhere e.sid = s.sid;
字符串处理
名称
大小写
引号
字符串拼接
SQL-92
敏感的
单引号
||
PostgreSQL
敏感的
单引号
+
mysql
不敏感的
单引号/双引号
concat / 空格
SQLite
敏感的
单引号/双引号
+
|DB2
敏感的
单引号
||
Oracle
敏感的
单引号
||
时间日期处理
名称
当前日期 NOW()
当前日期 CURRENT_TIMESTAMP()
当前日期 CURRENT_TIMESTAMP
日期差值
PostgreSQL
2023-04-26 14:27:01.790522+08
不支持
2023-04-26 14:27:32.280334+08
select DATE(‘2018-08-29’) - DATE(‘2018-01-01’); 结果240
mysql
2023-04-26 14:28:36
2023-04-26 14:28:44
2023-04-26 14:28:56
select DATEDIFF(DATE(“2018-08-29”),DATE(“2018-01-01”)); 结果240
SQLite
不支持
不支持
2023-04-26 06:30:47
select CAST((julianday(‘2018-08-29’) - julianday(‘2018-01-01’)) as INT) as days; 结果 240
复制表数据 create table会创建表,insert into需要表已经存在。
1 2 3 4 5 6 7 create table student2 ( select * from student ); insert into student2( select * from student );
获取id最大的一个学生数据 下面的是错误做法,因为不知道id最大的name是谁,会报错,如果sql_mode=tranditional,会执行成功,但是name是随机的。
1 2 select MAX (e.sid),s.name from enrolled as e,student as swhere e.sid = s.sid
下面的在postgresql和mysql都可以执行成功,并获取到id最大的name数据。
1 2 select sid, name from studentwhere sid in (select max (sid) from enrolled)
下面的SQL在postgresql中可以执行成功,结果和上面的一样,而在mysql8中报错This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
1 2 select sid, name from studentwhere sid in (select sid from enrolled order by sid desc limit 1 );
获取没有学生报名的课程 下面的sql在postgresql 和 mysql 中都可以得到正确的结果
1 2 select * from course where not exists (select * from enrolled where course.cid = enrolled.cid);
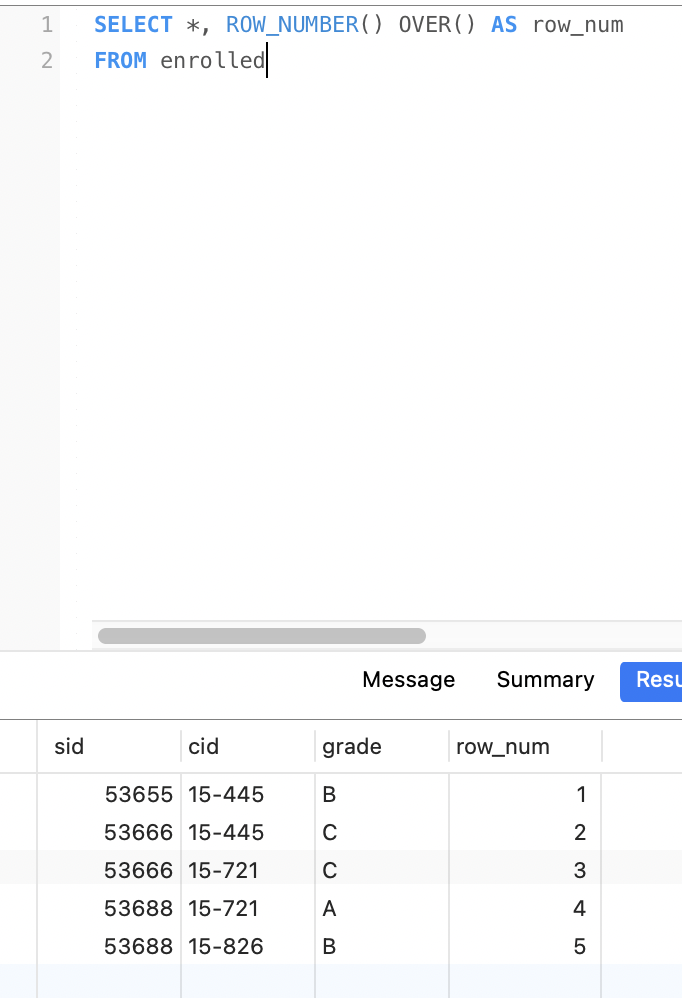
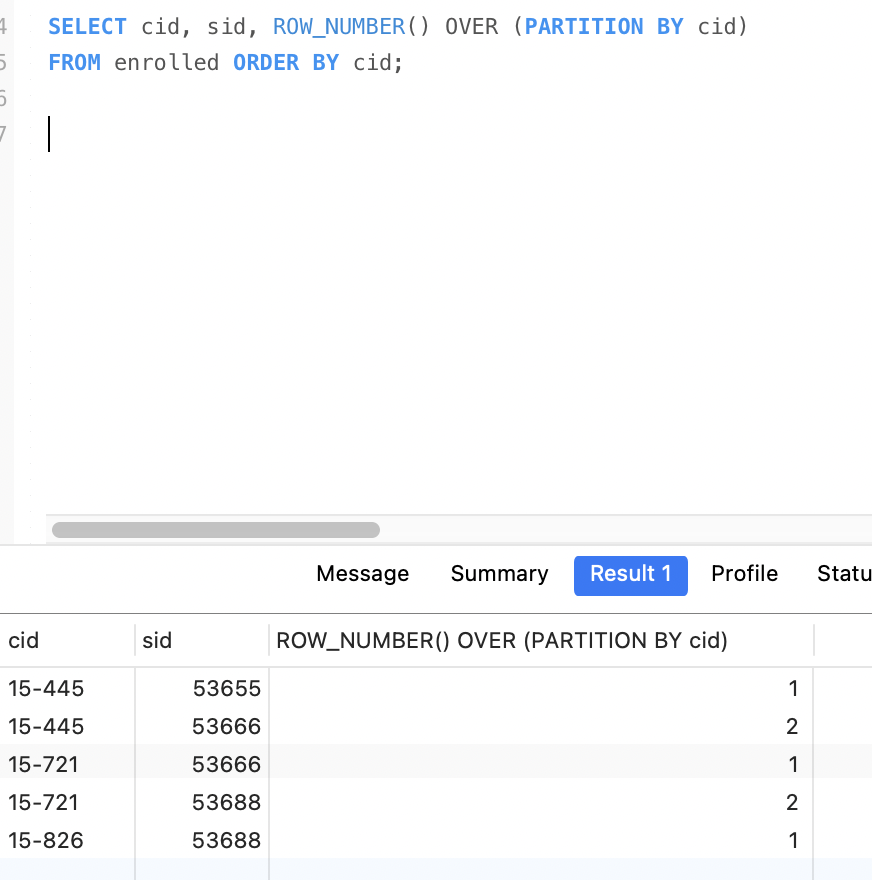
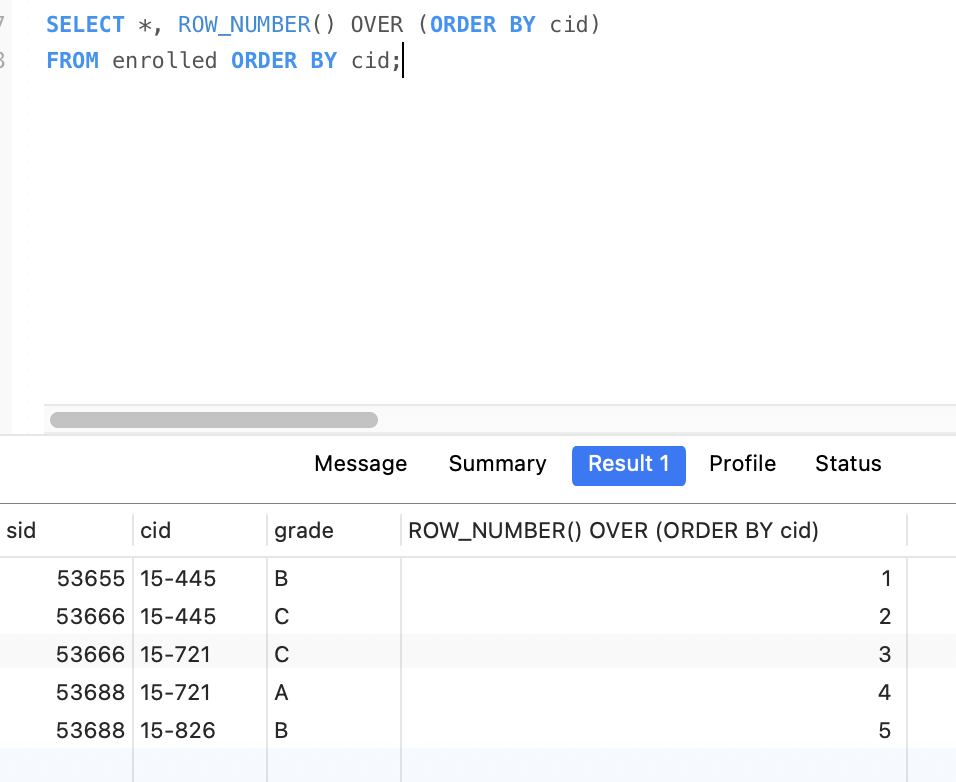
window窗口 ROW_NUMBER和RANK都需要和OVER一起使用。
ROW_NUMBER(): 显示当前行号
RANK() : 显示排序后的排名,如果没有排序,都是1
OVER()
PARTITION BY 进行分组
GROUP BY 进行分组
ORDER BY 排序
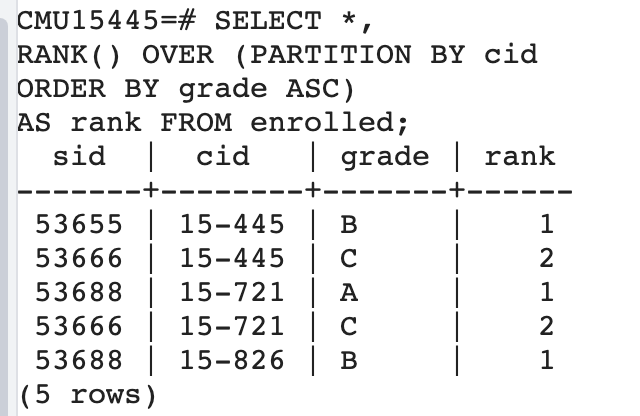
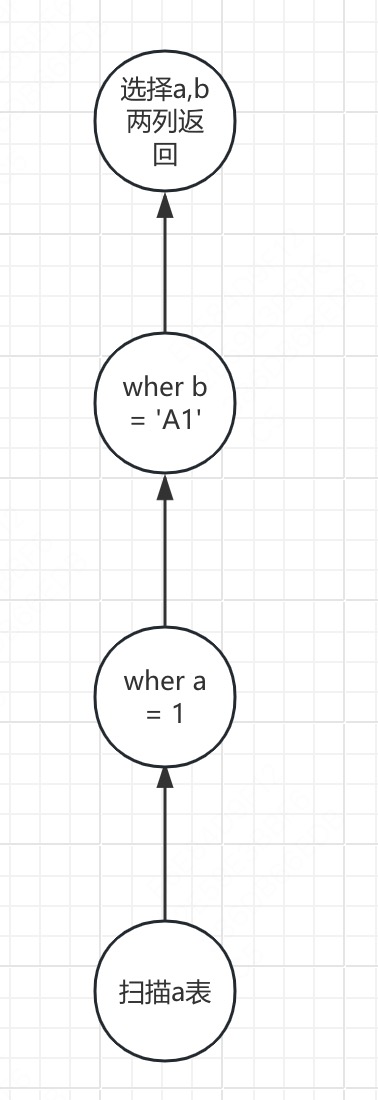
获取每个课程中分数最高的学生信息 下面的SQL,在postgresql中执行成功,mysql8执行报错。
首先查询所有课程信息,并按照课程分组,按照分数排序。
1 2 3 SELECT * ,RANK () OVER (PARTITION BY cid ORDER BY grade ASC )AS rank FROM enrolled
接着搜索上表中分数为1,也就是分数最高的学生。也就是每个课分数最高的学生信息。
1 2 3 4 5 6 SELECT * FROM ( SELECT * , RANK () OVER (PARTITION BY cid ORDER BY grade ASC ) AS rank FROM enrolled) AS ranking WHERE ranking.rank = 1
CTE(common table expressions) 使用CTE实现获取每个课程中分数最高的学生信息。
通过WITH语句来声明一个临时表。表名cteSource,表的内容就是最的sid,通过SELECT MAX(sid) FROM enrolled查询出来的结果。字段名叫maxId。
然后在查询语句里面就可以连接cteSource表,然后通过sid = cteSource.maxId 来获取到sid最大的用户信息。
1 2 3 4 5 WITH cteSource (maxId) AS ( SELECT MAX (sid) FROM enrolled ) SELECT name FROM student, cteSourceWHERE student.sid = cteSource.maxId
还有一些其他的用法,比如:
1 2 3 4 5 6 7 WITH cte1 (col1) AS (SELECT 1 ), cte2 (col2) AS ( SELECT 2 ) SELECT * FROM cte1, cte2;
lateral join mysql目前还不支持该功能,postgreSQL和Sqlserver等支持。
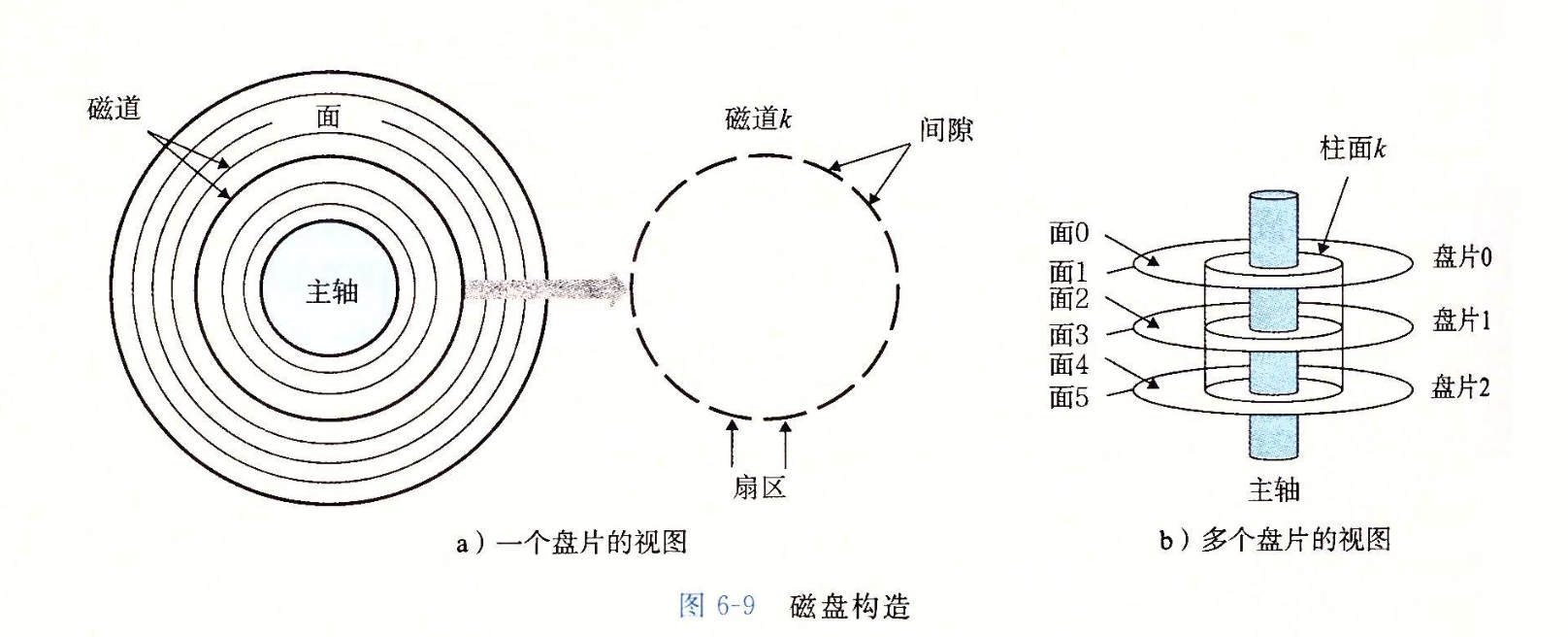
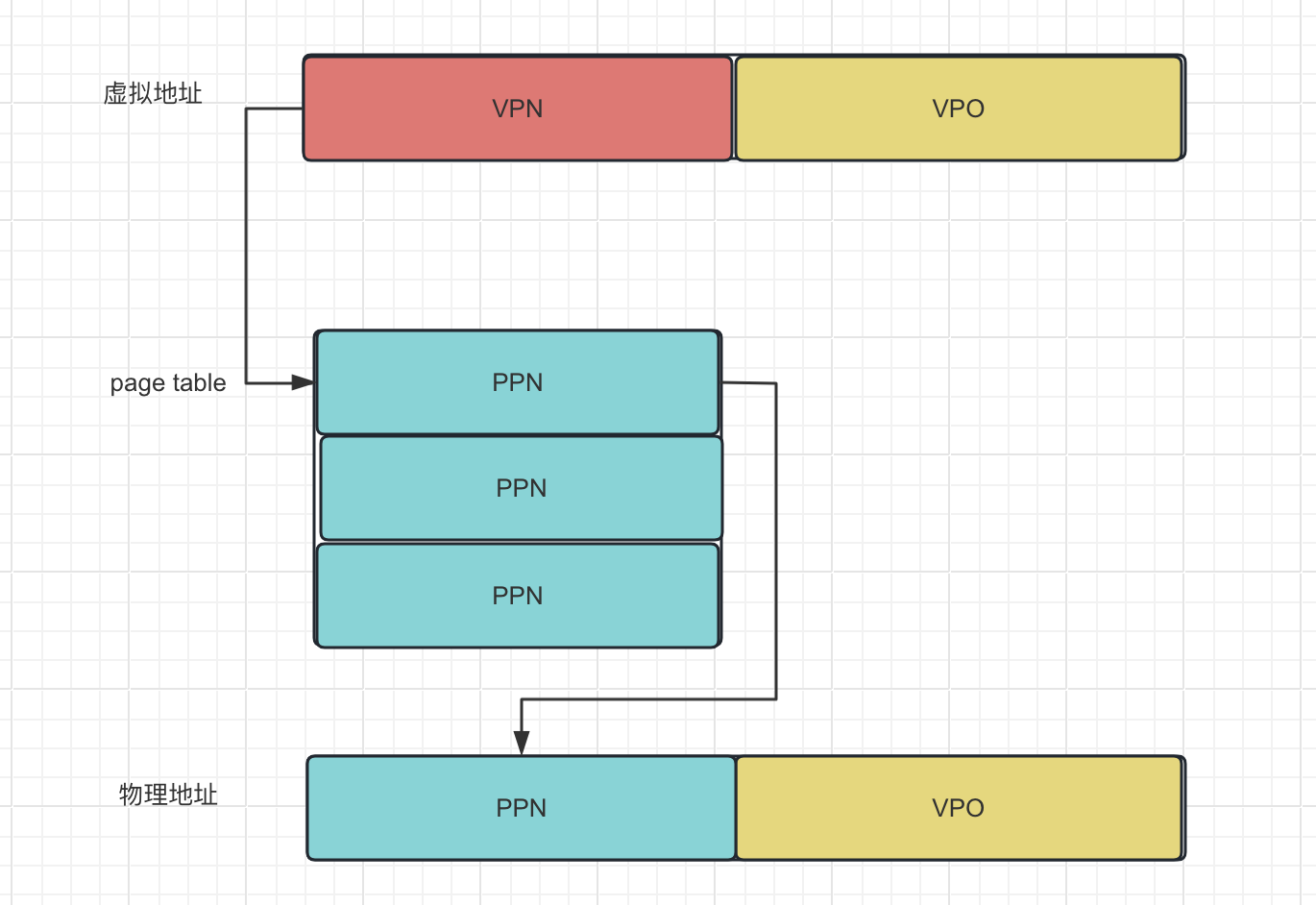
数据存储 页的三个概念
硬件上的页面(通常是4KB)
操作系统上的页面(4KB,x64 2MB/1GB)
数据库页面(512B-32KB)
磁盘和内存通信是一页一页的,如果数据都在一页里,后续的访问请求就可以走内存了,要不然还的从磁盘获取。内存中可以获取bit数据。
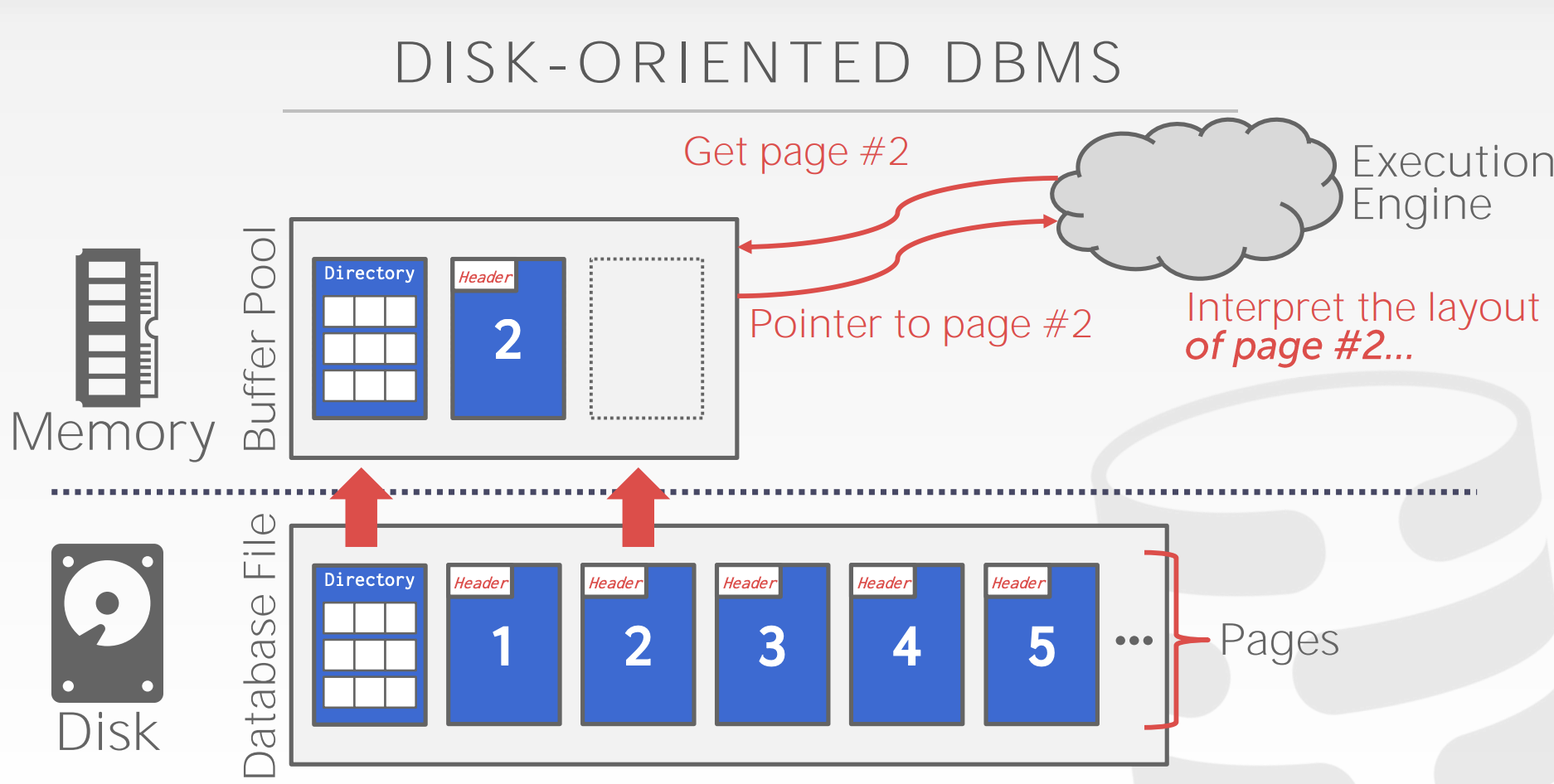
系统设计目标:给应用程序一个错觉,能提供足够的内存将整个数据库存入内存中。
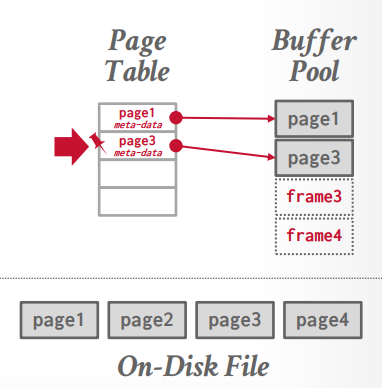
查询执行器:向内存中的buffer pool请求查询内容。
buffer pool: 如果数据所在的页已经在buffer pool中,就直接返回。如果数据所在的页不在buffer pool中,就向磁盘中的database file请求。
database file: 有页目录,还有具体的页,数据存在页中,查询页目录找到对应的页返回给buffer pool。
上面的步骤操作系统本身就可以实现,比如使用mmap,但是操作系统是统一的动作,遇到一些问题不知道该如何处理,而DBMS则可以根据不同的情况做不同的处理,进行优化。像主流的mysql,SqlServer,Oracle都没有用mmap。mongoDB早期使用的mmap,后面也是用WiredTiger替换掉了mmap。
DBMS自己实现的话,主要关心的两个问题:
如何表示磁盘上文件的数据
如何管理内存以及在硬盘间移动数据
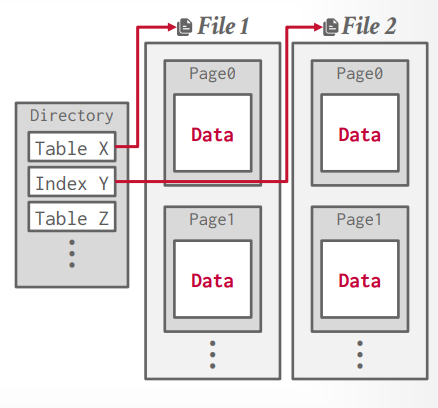
如何表示磁盘上文件的数据 数据库的数据最终以文件的形式放在磁盘中。通过文件读写将数据读写到文件中。文件有特定的格式,具体的内容有数据库进行解析然后展示在数据库中。这就是storage manager or storage engine。
storage manager负责文件的读写工作。所有的文件(不管是一个或者多个)以 page 的形式存储,管理多个 page 组成的集合。
一个page就是一个固定大小的数据块。page 可以保存任何东西,tupe, metadata, indexes, log等等。每个page有唯一的ID,是page ID。
有些page要求是独立的,自包含的(self-contained)。比如mysql的InnoDB。因为这样的话一个表的元数据和本身的数据内容在一起,如果发生问题的话,可以找回元数据和数据。如果元数据和数据在不同的page中,如果发生问题导致元数据的page丢失,那么数据则恢复不了了。
indirection layer记录page ID的相对位置,方便找到对应的偏移量。这样page目录就能找到对应的page。
不同的DBMS对于文件在磁盘上的存储方式不一样,有下面几种
堆存储
树存储
有序文件存储(ISAM)
hashing文件存储
堆存储
无序的,保存的顺序和存储的顺序无关。
需要读写page
遍历所有的page
需要元数据记录哪些是空闲的page,哪些是已经使用的page。
使用 page directory 方式来记录文件位置。
page directory
存储page ID和所在位置的关系
存储page的空闲空间信息
page header
page 大小
checksum 校验和
DBMS版本信息
事务可见性
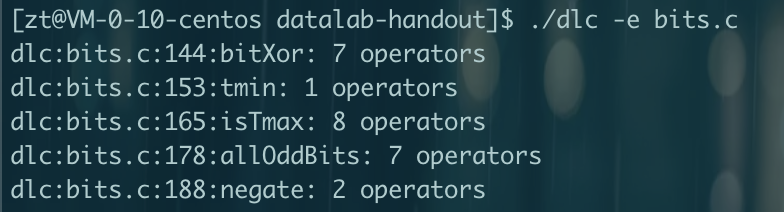
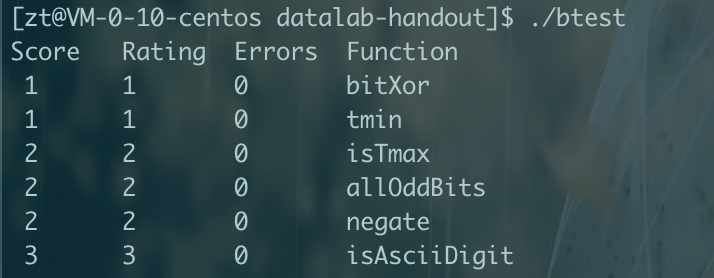
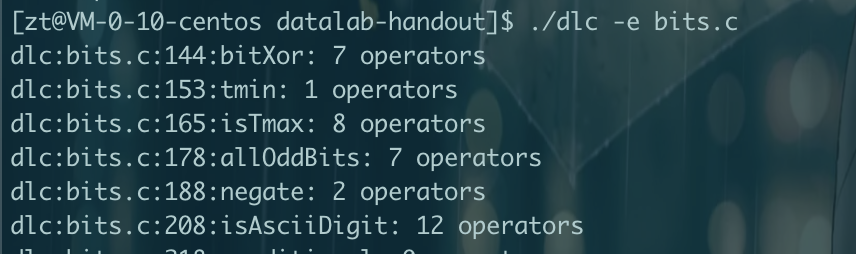
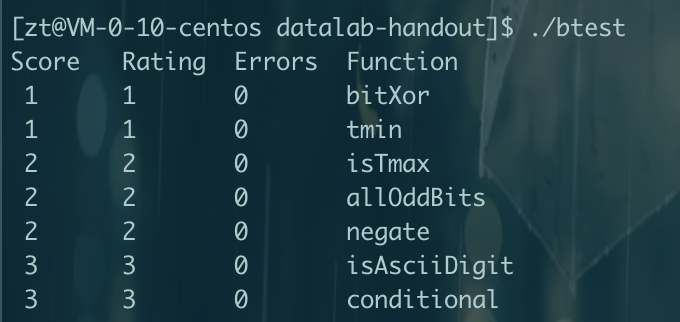
压缩信息
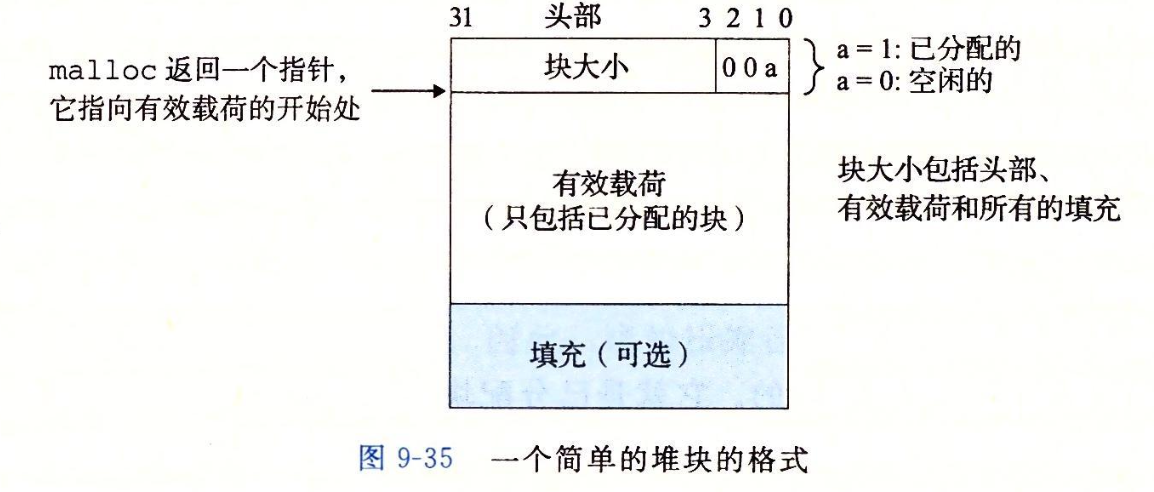
page layout tuple oriented storage 一般想法,直接存储,并在后面追加,但是对于可变数据长度很难管理。
记录page数,也就是page内部可插入的偏移量
一个一个tupe按照顺序存储
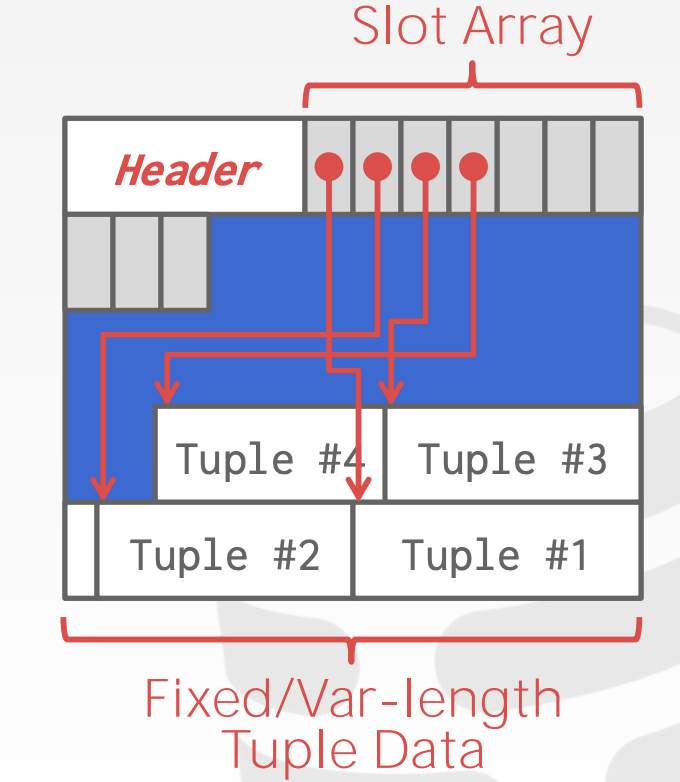
所以,page内部,通常不使用上面那种,而使用的是slotted pages
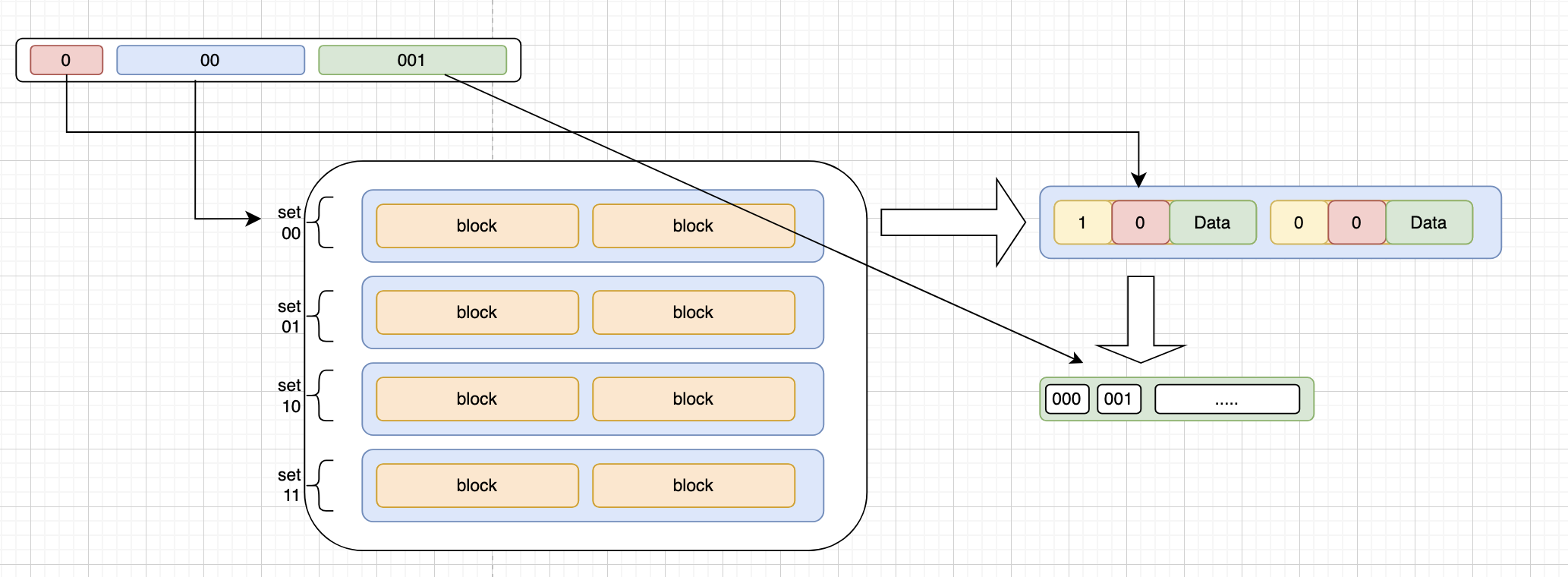
slotted pages
slot array 存储插槽信息的偏移量,通过他找到对应的tuple
支持可变长度的 tuple
但是会产生一些碎片空间,因为太小,tuple放不下。
压缩可以去除碎片空间,但是压缩的时候这个page就不能读写了。
record ID表示一个tuple的物理位置,不同的DBMS有不同的名称,来表示数据的唯一位置,比如postgresql的ctid,oracle的rowid。ctid由page id和slot number组成。
插入新的tuple的时候
检查page direactory,找到一个page里面有空的可用的slot
如果该page不在内存,就从磁盘上获取它,将它加载到内存
在page里面检查slot array,找到一个空的空间,将tuple插入
更新tuple的时候
检查page direactory,找到tuple对应的page
如果该page不在内存,就从磁盘上获取它,将它加载到内存
在page里面通过slot array获取tuple的偏移量
如果数据空间合适,那么直接覆盖该tuple,否则,将原来的tuple标记为已删除,并将新tuple插入其他page。
因此更新的时候有一些问题
page会产生碎片空间
更新的时候需要从磁盘获取整个page
更新多条数据的时候,可能多个tuple在多个page中,产生随机IO
所以有些DBMS不能更新数据,只能增加数据,比如HDFS等
Log Structured Storage 比如HBase,ClickHouse,RocksDB,LevelDB都是这个方式。
这种方式的一些问题:
Write-Amplification:在该tuple的生命周期里面可能写入无数次磁盘,并一直在那里且不被需要。
Compaction is Expensive:
Index Organized Storage tuple
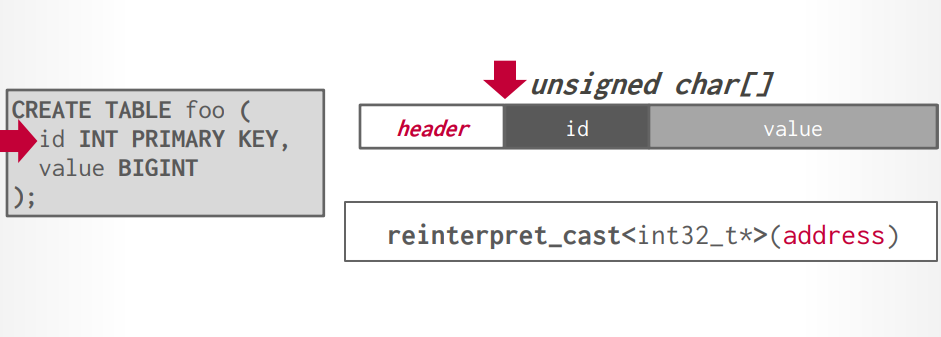
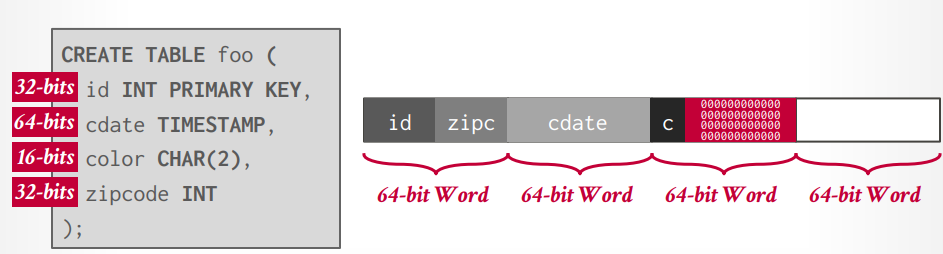
tupe layout tuple就是一堆bit,DBMS解释他们的作用。里面包含
data layout table foo
id int primary key
value bigint
数据对齐 现代CPU是64位对齐,创建表以后,DBMS会自动的将数据进行对齐存储,不过,如果在创建表的时候考虑对齐,可以优化速度和存储空间。
数据表示 可变长度的数据varchar,varbinary,text,blob,他们的长度存在header里面。
日期时间类型存储的是时间戳。
float/real/double: 是浮点数,cpu支持浮点数运算,优点是速度快,但是会精度缺失
large values,应该避免这样,因为维护overflow page很麻烦。
tuple中存储另外一个page页的指针,将具体数据存放到另外一个page页中。
postgresql中叫toast,如果数据大于2KB,就会放到toast中,tuple中只存储指针。
mysql中叫overflow page,如果数据大于1/2的page大小,就会放进去,tuple中只存储指针。
外部存储
NULL存储
行数据库通常是在Header里面增加bit map来判断是否是null
列数据库通常使用占位符来标识NULL
在每个属性前面增加bit来标识是否是NULL,这么做会破坏对齐,或增加存储空间,MySQL曾使用这个方法,后来抛弃了这个方法。
NULL == NULL 是 NULL, NULL is NULL 是 true
catalogs 用来存储数据库元信息,大多数数据库将这些信息存到一张表里面
表,字段,索引,视图等
用户,权限,安全等
内部数据统计等
infomation schemal api 通过这个来获取catalogs信息
mysql
show tables 获取所有的表
describe table_name 获取表的信息
postgresql
\d or \d+ 获取所有的表
\d table_name 获取表信息
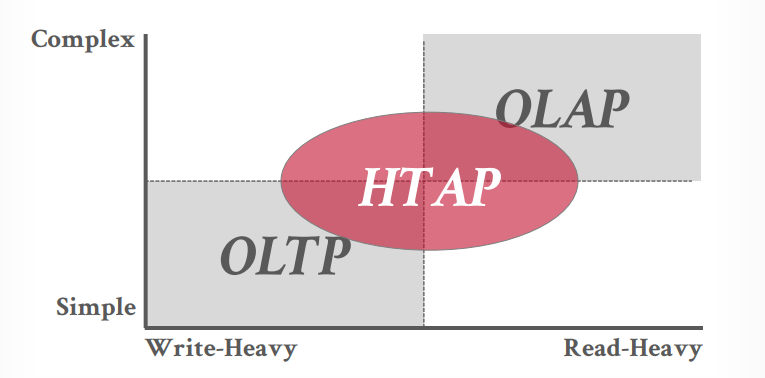
DATABASE WORKLOADS OLTP
通常是业务侧使用的传统数据库,比如oracle,postgresql,mysql
小的业务多次执行,比如多个简单的插入,更新,查询
OLAP
通常是大数据,数据分析来使用,比如Hbase等,支持复杂的数据查询
OLAP位于OLTP的后方
HTAP
N-ary 模型
行存储模型
page里面是按行存储的,每个tuple就是一行
优点
快速的insert,update,delete
查找的优势是数据都在一起
能在集群中使用 index-oriented物理存储方式
缺点
不适合扫描table中大部分and/or属性的子集
访问的内存局部性糟糕,查找数据的弊端是会加载一个page的时候会加载不需要的行数据
不适合压缩,因为一个page里面有不同的value domains
Decomposition 模型
优点
优势是查找的时候不会加载不需要的数据
更快的查询过程,因为有更好的局部性和cached data重用
更好的数据压缩
缺点
劣势是查找的数据不在一起,需要去各个page里面找。所以insert update delete也更慢。
列存储查询的时候处理where子句以后需要找到对应的其他列在其他page中的位置,有两个方法,通常使用第一个方法,第二个方法并不好
固定长度:每个page中的每个列的长度都固定,顺序也一样,这样通过where子句对应列的偏移量,就可以确定其余列的偏移量
内嵌tuple id: 每个值里面都加入对应的tuple id,根据tuple id查询其他列
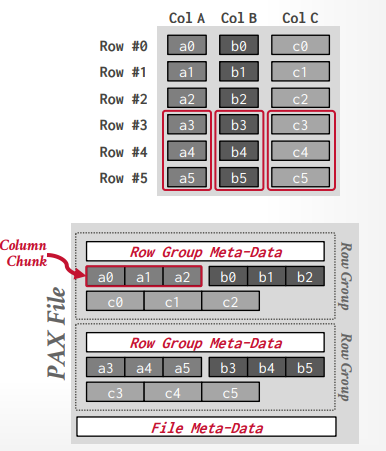
Partition Attributes Across(PAX) Storage 模型
PAX 物理数据组织
水平划分为row groups,即一些行数据的集合
在row groups里面垂直划分为column chunks,即列的集合,也就是列存储方式
每个column chunks下面可能还会有page
数据库压缩 目标1:必须产生固定长度的值
压缩粒度
Block-level: 压缩同一张表的tuple
Tuple-level: 压缩整个tuple的内容(仅限行存储)
Attribute-level:压缩同一个tuple的多个属性或单个属性
Column-level:压缩存储于多个tuple中的一个或多个属性的多个值(仅限列存储)
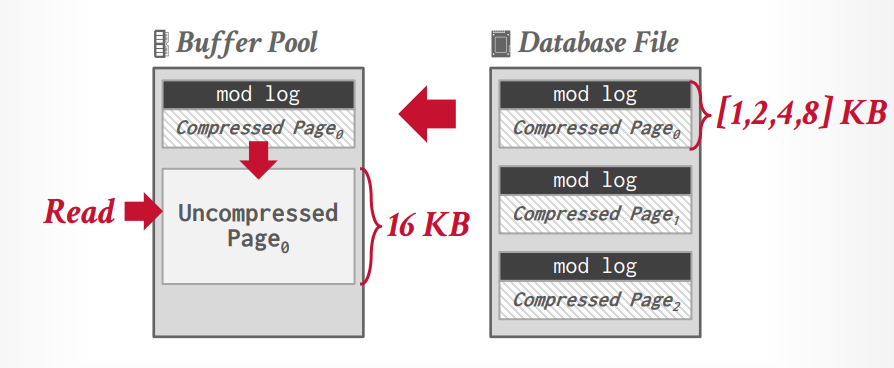
mysql innodb 压缩 innodb 在写入的时候可以不解压,但是读取的时候会先在buffer pool中解压在读取。因此Mysql innodb的压缩的好处是提升空间利用率,减少了磁盘IO,缺点是读取的时候需要解压,因此增加了这部分的时间和CPU功耗以及解压以后会占用更多的内存空间。
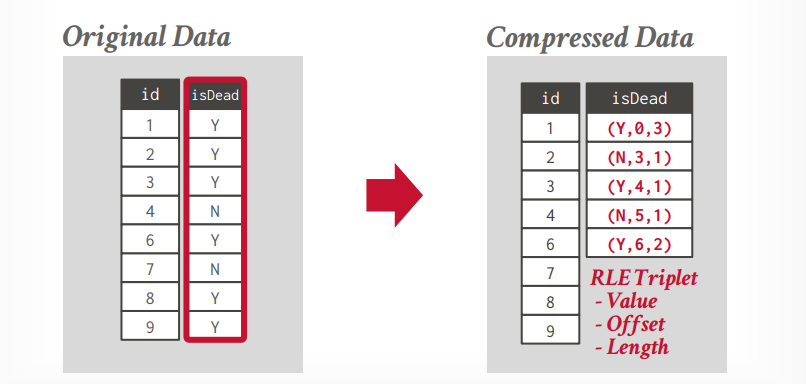
Column-level 压缩算法 run length encoding 将单个column中的相同值压缩成三元组,需要对列进行智能排序,以最大限度地提高压缩机会。
属性的值
column segment的起始位置
值的数量
比如下面的数据,将压缩成右边的数据,(Y,0,3),代表值是Y,起始位置0,值的数量有3个。后面的压缩数据是一样的。这种压缩方法可以快速计算count的数量等。
如果你的值类型很少,且有序,那么将大大减少空间占用。
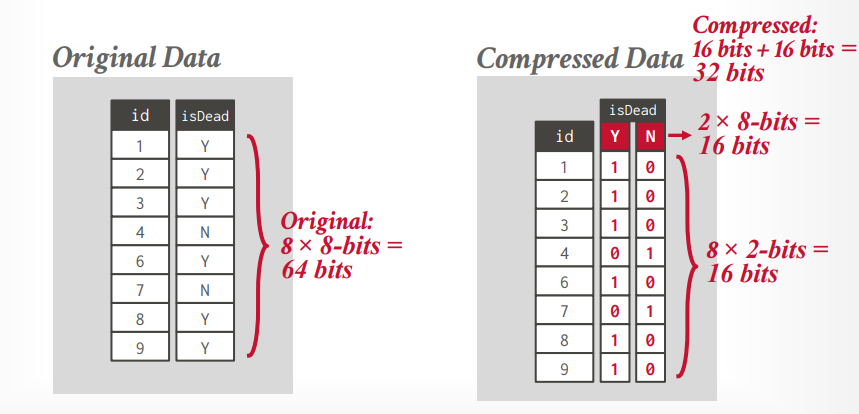
bit packing 如果字段里面的值都比较小,但是column type很大,可以忽略掉不需要的bit,比如int是32 bit,但是里面的值都很小,用不了这么多,就可以忽略他们。
bit map encoding 使用bit map来标识数据值,仅仅适用于值的类型比较少的。
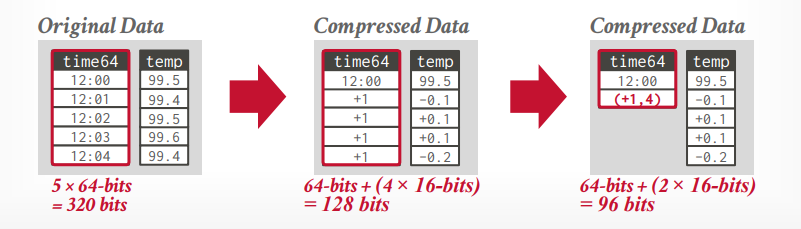
delta encoding 找到一个基本的数据,以它为基础,进行压缩,+1,-1这种。再将其按照run length encoding的方式压缩,可以再次节省空间。
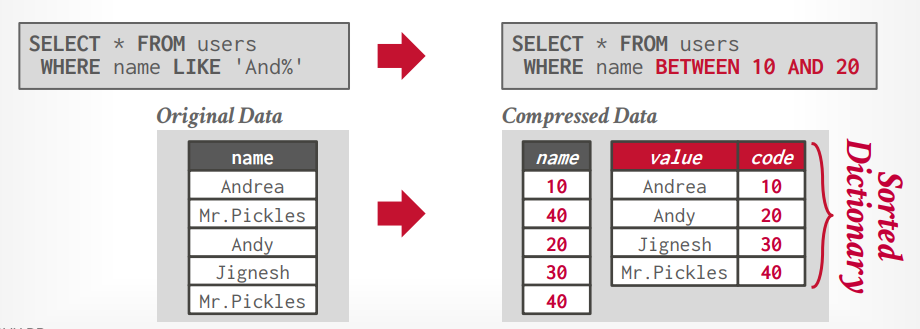
DICTIONARY COMPRESSION 按照字典将数据进行映射,并存储,这样可以节省空间,如果在字典映射的时候还能先排序,那么还可以完成将where like 'and%'转成where between 10 and 20。
buffer pool 和内存管理 时间管理
将数据写入磁盘的何处
目标是经常被一起使用的pages放在磁盘中也是一起的地方。
空间管理
何时将pages读入内存,何时将pages写入磁盘
目标是最小化的解决必须从磁盘读取数据这个事
frame
buffer pool中的一块内存区域
相当于page里面的slot
page table
记录pages在当前buffer pool中的位置,通过page table 和 page id可以知道在哪个frame中。
page 里面记录一些元数据
dirty flag: 记录是否被修改过,也就是常说的”脏数据标记”
引用计数器: 记录有多少线程在使用这个数据
访问追踪信息
lock and latch
lock在数据库中指high-level的东西,可以保护数据库,数据表,数据。保护数据库内容不受其他事务影响,在事务持续期间保持,可以回滚。
latch保护内部的东西,数据结构,内存区域。保护内部数据结构不受其他线程的影响,在操作期间保持,不需要可以回滚。
buffer pool 使用 mmap的问题:
事务安全:操作系统完全控制page的写入,刷新,有可能在一个事务没有完成的时候有些数据就已经写入磁盘了。
IO停顿:DBMS不知道哪些page在内存中,当读取不在内存中的时候触发page fault,操作系统才会从磁盘获取。
错误处理:任何访问都可能触发操作系统的中断信号SIGBUS,而整个DBMS都需要处理它。
性能问题
全局策略
局部策略
针对单个查询或者事务的策略
可以对单个优化,虽然对全局可能不好
淘汰策略 淘汰策略有几种算法
LRU
Clock:Linux使用的,把所有的page放成一个圈,每个page有一个标志位,如果为0表示没有被使用过,1被使用过,淘汰的时候淘汰0的,再把1改成0.
LRUK:记录使用的次数k,达到次数才放到缓存里面,淘汰的时候比对两次的时间间隔,间隔长的认为是最近最少使用
PRIORITY HINTS
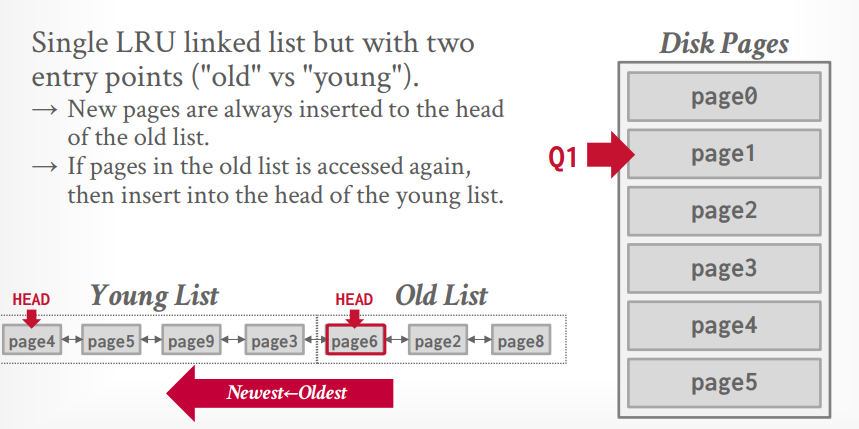
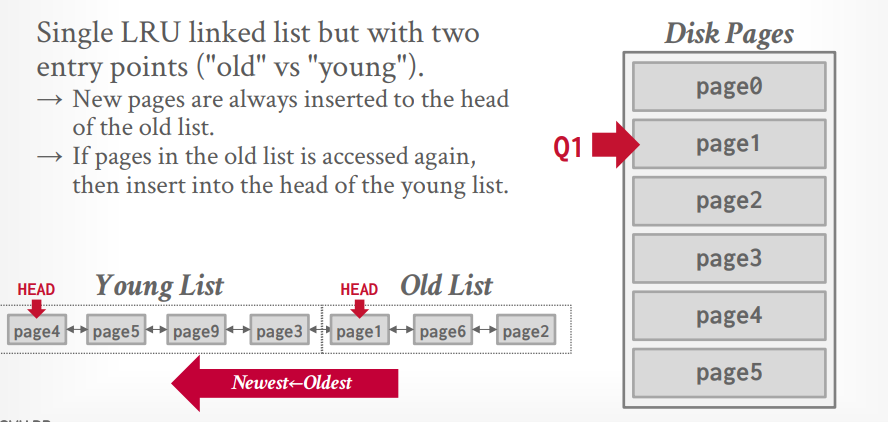
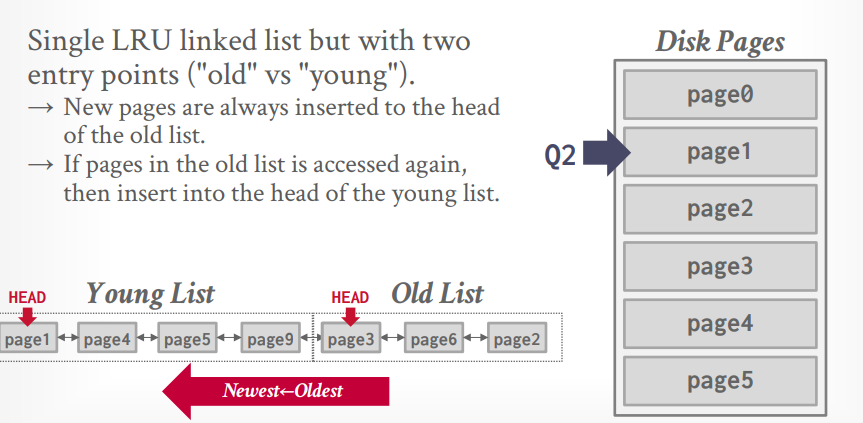
mysql 近似 LRU-k 相当于K=2。有一个LRU List,但是有两个指针,分别表示old list和young list。当数据第一次被访问的时候放到old list中,再次被访问的时候放到young list中。
当访问 page1 的时候,需要淘汰掉old list中的page8,其实也是整个LRU中的最后一个元素。然后将page1插入old list。
当再次访问 page1 的时候,将page1 插入young list。这个时候young list最后的元素也就进入了old list.
PRIORITY HINTS 比如B+树的根节点具有最高的优先级,所以一直放在内存中。
多buffer pool
通过使用多个buffer pool可以根据不同的table放入不同的buffer pool进行不同的优化。也可以通过其他的策略使用多个buffer pool
由于有多个buffer pool,减少了锁争抢和锁等待的时间。
mysql中通过hash确定数据是否在buffer pool,然后通过取余确定在哪个buffer pool
预取数据
顺序扫描的时候预先把后面的page取到buffer pool中。这一步mmap也可以实现
索引扫描的时候预先把索引中需要用到的后面的page取到buffer pool中。这一步mmap实现不了,这也是数据库自己实现buffer pool的优势。
扫描共享
共享扫描到的page内容
如果查询1需要扫描page1,page2,page3,page4的内容并且已经扫描到了page3,这个时候page1已经扫描完了被从buffer pool中丢弃了
这时候有一个查询2也需要扫描所有的pages,如果从page1开始扫描,就会把page1再次读入buffer pool,但是这样是低效率的,所以可以先共享查询1的page数据,先扫描page3,然后page4,这时候查询1执行完毕,在回头扫描page1,page2。
mysql不支持
buffer pool bypass
单独开辟一个本地内存区域来用,而不是使用buffer pool
可以避免操作page table带来的开销(latch锁住的开销)
可以避免污染buffer pool
适合数据量不大的情况
mysql5.7不支持
os page cache
操作系统的文件缓存,当使用fopen,fread,fwrite的时候会先从操作系统缓存中读取文件内容。
只有postgresql使用了这个。
通过 direct IO可以不使用这个
使用它会导致有两个缓存,buffer pool 和 os page cache。不好控制。
fsync如果失败以后再次调用也不会生效,因为它会将dirty设置为false
两种写出方案需要做权衡,取舍
如果写出dirty flag的数据然后读取新数据,就会产生2次IO。通常会有一个定时任务线程去将dirty flag的数据写入磁盘,写入之前必须要先将操作日志写入磁盘。
如果直接读取新数据就只有1次IO,但是这样有可能把下次会用到的数据丢弃。
hash table hash function
hash schema
liner probe hashing
如果要插入的位置有值了,就往下扫描,扫描到空的位置插入
删除的时候可以增加一个墓碑标记,这样就知道这里是有数据的不是空,查找的时候就会继续往下扫描而不会是没找到
删除的时候还可以把后面的数据往前移动,但是这样有的数据就不再原来的位置了,就找不到了。因为只会往下扫描不会往上扫描
robin hood hashing
记录距离数,表示插入的位置和应该插入的位置的距离。从0开始。
插入的时候判断距离数,进行劫富济贫,如果你向下扫描到距离数为3的地方插入,而在距离数为2的地方的数据x,x的距离数比你小,比如是0,1.那么你就占据这里,你插入距离数为2的地方,而将x插入你下面,x的距离数会+1.
从整体来看,这个方法牺牲了插入的效率,将数据的距离数变得更加平均
cuckoo hashing
该方法使用两个或多个hash table来记录数据,对A进行两次hash,得出两个hash table中的插入位置,随机选择一个进行插入
如果选择的插入位置已经有数据了,就选择另一个插入
如果两个都有数据了,就占据一个,然后对这个位置上之前的数据B再次hash选择其余位置。
动态hash table
chained hashing
把所有相同hash的组成一个bucket链表,然后一直往后面增加
java的hash table默认就是这样的
extendible hashing
对 chained hashing 的扩展
有一个slot array,在slot array上有一个 counter, 如果counter = 2,代表看hash以后的数字的前两个bit,slot array就有4个位置,分别是00,01,10,11
每个slot指向一个bucket
hash以后找到前两位对应的slot指向的bucket,将数据放进去,如果满了,放不下了就进行拆分
将slot array的counter扩容为3,看前3个bit,slot array变成了8个位置
只将这个满了的bucket拆分成2个,其余的不变,重新进行slot的映射
再次hash这个值,看前3个bit找到对应的slot,在找到对应的bucket,然后插入进去
linear hashing
对 extendible hashing 的扩展
去掉了 conter,因为他每次加1,都会扩容一倍
增加了split point,一开始指向0,然后每次overflow需要拆分的时候就拆分split point指向的那个bucket,然后slot array只扩容一个,这个时候出现第二个hash函数并将split point+1
查询的时候如果slot array的位置小于split point,就使用第二个hash函数,因为被拆分了
如果大于等于split point,就使用第一个hash函数
tree index
b tree(1971)
b+ tree (1973)
b* tree (1977)
b link tree (1981)
b+ tree 删除和插入的复杂度都是O(log n), b 是 balance (平衡),paper: the ubiquitous B-tree
B+ tree,保证每个节点都必须是半满的,对于存放在节点中的key数量来说,key数量至少为M/2 - 1个,M为树的高度,key的数量必须小于 M - 1,如果当删除数据以后导致key数量小于M/2 - 1个,就会进行平衡,使他满足M/2 - 1个。
M/2 - 1 ≤ key数量 ≤ M - 1
如果一个中间节点有k个key,那你就会有k+1个非空孩子节点,也就是k+1个指向下方节点的指针。每个节点的内容是一个指针和一个key
叶子节点之间有连接叶子节点的兄弟指针,这个想法来源于b link tree。每个节点的内容是一个数据和一个key,数据可以是一个record id 也可以是一个 tuple
叶子节点的内容,通常key和value是分开存储的,因为搜索的时候并不需要加载value数据
元数据
isleaf 是否是叶子节点
slots 有多少空闲的slot
prev 前一个叶子节点的指针
next 后一个叶子节点的指针
key数据
value数据
b tree 和 b+ tree 的区别
b tree的中间节点也可以存数据,所以key是不重复的
b+ tree的中间节点没有数据,所有数据都在叶子节点,所以key有可能既存在中间节点也存在叶子节点。会重复
b tree的性能在并行处理上更差,因为修改以后需要向上传播也需要向下传播修改,这个时候两边都要增加latch
b+ tree的性能更好,因为只修改叶子节点,所以只需要向上传播,只需要增加一个latch
b+ tree 插入
向下扫描,找到对应的叶子节点
如果可以插入就直接插入
如果不可以插入,那么从中间分开,变成两个叶子节点,并将中间的key传递给父节点,插入父节点。
如果父节点可以插入就直接插入并分出一个指针指向新的叶子节点
如果父节点不可以插入重复上述操作3
b+ tree 删除
向下扫描,找到对应的叶子节点,这个时候就会增加latch,因为不知道需不需要合并,操作以后才会释放
如果可以删除就直接删除
如果删除后导致key数量 < M/2 - 1,那么就会出发合并,因为不满足key数量啦
进行合并的时候删除这个key,然后先查看左右的兄弟节点,是否能直接把数据插入过来,如果可以的话就掠夺一个key过来,然后向上传播
如果不能掠夺,那么就合并到兄弟节点,然后向上传播。
b+ tree 标准填充容量大概是67% - 69%,对于一个大小是8kb的page来说,如果高度为4,大约能记录30 0000个键值对。
b+ tree的查找
对于<a,b,c>,查找a=5 and b=3也是可以走索引的,但是hash索引就不行,有些数据库还支持b=3的搜索走索引,比如oracle和sql server
b+ tree的节点大小,机械硬盘的大小最好在1M,ssd的大小在10KB
推荐书籍 Modern B-Tree Techniques
对于非唯一索引
重复存储,需要注意两个相同的key存储在不同的page中
value list,key只存储一个,然后所有的value存储成value list
节点内部的搜索
优化方法
前缀压缩
比后缀截断用的更多
存储在page中的key,如果前缀一样的可以提取出来存储一次,然后剩余的数据在存储在key里面
后缀截断
存储在中间节点的,用来寻路的key,可以只存储前面的部分,如果后面的不需要可以截断
更新的时候需要进行维护
批量插入
如果已经有数据了再建立索引,这个时候不需要从头开始一个个建立,只需要先排序
然后建立所有的叶子节点
在一层层向上建立中间节点
非常普遍的方法,主流数据库都支持
point willizeing
将节点固定在内存中
对于page来说,直接存储page指针而不是page id,就不需要请求buffer pool了
b+ tree的重复key,通常使用增加record id的方式,这种方式影响更小。
增加record id,record id是page id + offset用来确定tuple的位置。
垂直扩展叶子节点,将数据存在里面
部分索引
在创建索引的时候添加where条件,只有符合条件的才会进入索引。
查询的时候只有符合条件的才会走索引
覆盖索引
在创建索引的时候添加联合索引
查询的时候所需数据都在索引中,就不需要在找对应的tuple信息了。
函数索引
创建索引的时候添加函数信息,比如 MONTH(date), 只对月份创建索引
查询的时候 MONTH(date) 就会走索引了,而date就不会走索引了
如果创建的时候只创建 date 索引,那么查询的时候 MONTH(date) 就不会走索引
trie index(前缀树)
radix tree
trie index的升级版
对于trie index进行了横向的压缩和纵向的压缩
过滤器 Bloom filter
Counting Bloom filter
Cuckoo filter
Succinct Range Filter
索引并发控制 并发控制
逻辑正确性
获取id = 5的数据,能正确返回id = 5的数据
物理正确性
保护page指针指向正确的page数据,不会触发 segfualt
latch 模式
读模式
写模式
只有一个线程可以写模式,这个时候其他线程不能读取也不能写入
latch
blocking os mutex
std::mutex m;
m.lock();
m.unlock();
test and set spin latch
std::atomic_flag latch
while(latch.test_and_set()){} // 如果获取到锁就跳出循环
read - write latch
读锁,获取的时候线程数队列,等待队列,如果能获取就进入线程数队列,不能就进入等待队列
写锁,线程数队列,等待队列,如果能获取就进入线程队列,不能就进入等待队列
如果有一个写锁在等待队列,这个时候在获取读锁也放入等待队列,要不然一直读,写锁就获取不到了
latch crabbing/coupling
使用栈保存latchs
每个节点都需要一个latch
如果当前节点是安全的,就可以释放上层的所有latchs
安全:指操作的时候不会触发拆分和合并。通常read latch都是安全的,write latch 插入的时候如果有足够的空间就是安全的,删除的时候删除以后不会合并就是安全的
乐观锁
乐观的认为不需要合并和拆分。
所有的操作都先获取read latch,如果发现需要合并和拆分,再次从头获取write latch来一遍
优点是所有操作都是read latch,可以更好的支持并发
缺点是遇到合并和拆分会再来一遍,而且如果连续的插入都需要合并,就会退化成每个都获取write latch。
叶子节点扫描
叶子节点的扫描可能会触发死锁,比如两个线程
线程1执行读取,读取到了叶子节点1
线程2执行写入,在叶子节点2处获取了write latch
这个时候线程1在叶子节点1里面没有找到数据,所以要扫描叶子节点2,但是获取read latch的时候卡主了,需要等待
而线程2有可能也需要访问叶子节点1,同样等待,产生死锁
这个时候可以设置等待时间,超过等待时间则自杀,然后重头再来,假如线程1自杀,然后再来一遍,这个时候线程2就可以获取到latch,然后执行下去了
overflow处理
来源于b link tree的优化
当需要拆分的时候,先拆分叶子节点,这个时候不向父结点传播,因为修改父结点需要从头开始获取write latch。
这个时候标记父结点需要插入一个key
等待下一个修改操作到父结点的时候,获取write latch,然后执行这个插入操作。
排序和聚合 排序的好处
有序的数据创建索引的时候可以快速的先创建叶子节点,在创建父结点
有序的数据在order by分组的时候可以更快的分组
有序的数据在distinct去重的时候可以更快的去重
排序算法
在内存中
可以使用各种算法
但是有的数据内存放不下,就需要在磁盘上排序
需要先知道可以用内存的大小,这样就知道该内存排序还是磁盘排序
在磁盘上
快排会产生更多的随机IO,会更慢
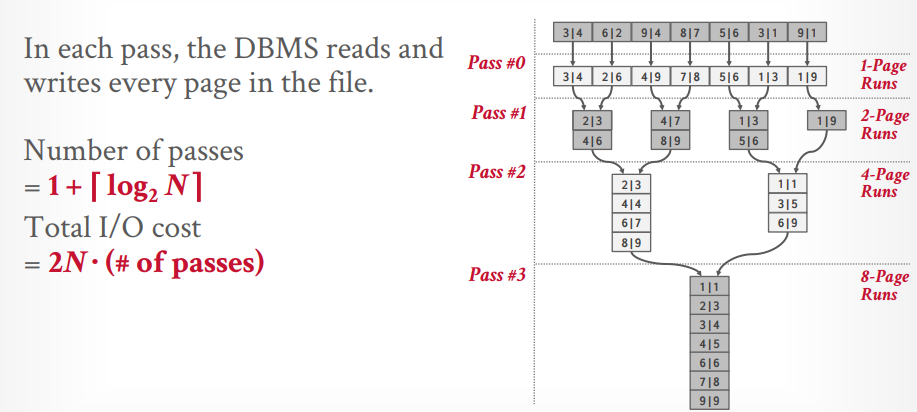
使用归并排序更好,分成多个runs,对每个run排序,然后在通过二路归并生成总的排序,这可以减少随机IO
外部归并排序,需要3个buffer pool,2个用来排序run,1个用来二路归并。
次数:1 + log(n)
总的IO数: 2N * (# of passes)
可以通过预取来优化,当对page排序的时候,另外一个线程先取出下次要排序的page。
聚簇索引
排序的字段如果建立了聚簇索引,就不需要在排序了,直接可以走聚簇索引拿到排序好的数据
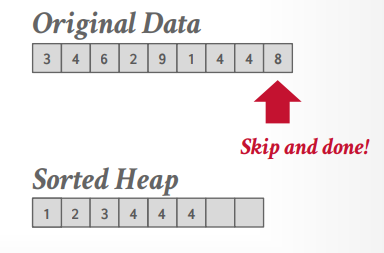
top-N heap sort 比如下面的sql
1 2 3 select * from aorder by id ASC limit 2 ;
那么首先创建一个大小为2的有序数组或优先级队列之类的。假设我们的数据是
1 {id:3, name: xxx}, {id:4, name:xxx}, {id:5, name:xxx}, {id:2, name:xxx}
这个时候优先级队列是空的
然后扫描id为3的数据,放入优先级队列,再扫描id为4的数据,放入优先级队列。这个时候队列数据是
1 {id:3, name: xxx}, {id:4, name:xxx}
接下来扫描id5的数据,放不进优先级队列,因为id大,最后扫描id2的数据,放入优先级队列,队列就排好序了
1 {id:2, name:xxx},{id:3, name: xxx}
external merge sort 当数据太大,无法放在内存中的时候,需要借助外部的文件来进行排序
先排序小块的数据,然后写入文件
在将文件的内容合并
early materialization
将数据放在排序的数据里面,排序以后可以直接返回数据,行数据库一般用这个
late materialization
排序的数据里存的是tuple id or record id, 排序以后再根据id查询数据返回
优化方法
增加buffer pool在排序中可用的内存,当一个输出page进行写入IO的时候,CPU处理另一个输出page。
多线程,一个线程进行page排序,另外一个线程进行二路归并。
聚合 两个实现方法
group by 和 distinct 本身执行的时候也是需要排序的
hash
分区
可以顺序扫描每个page
对于每个page的key进行hash,然后分区,hash相同的说明key相同,分到一个区里面
这个时候不管distinct还是group by都可以方便的执行了
重新哈希
对于分区以后的数据再次进行hash
再次hash的数据放入一个临时的hash table
处理完一个临时的hash table就把结果写入结果集
排序的聚合实现,以distinct为例:
先执行where条件筛选出符合的tuple
再次根据列筛选出符合的列
对于需要排序的列进行排序
顺序扫描排序结果,实现去重,并生成最终结果
哈希的聚合实现,以distinct为例:
先执行where条件筛选出符合的tuple
再次根据列筛选出符合的列
对于需要排序的列进行hash,先分区,再重新哈希。
重新哈希的时候生成最终结果。
重新哈希的时候
avg的话,需要再临时hash table里面存储key的数量和要求平均数的总数。在生成最终结果的时候进行计算平均数
min的话,临时hash table里面存入最小数,生成最终结果直接取
max同上
sum同上
count同上
join算法 join输出:数据
在join的时候把两张表的数据全部输出给下一个处理器,这包括了表的所有字段
好处是,接下来的处理不需要再拿其他字段了,所有字段都有了
坏处是,Join的时候数据量很大,因为有所有字段
可以进行优化,在join的时候只获取需要的字段
join输出:record id
在join的时候,只获取on的字段和record id,然后需要其他字段的时候在通过 record id去获取,这个很适合列存储数据库
第一个使用的是vertica列存储数据库,不过现在已经不用了
如何判断两个join算法的好坏?
通过IO来计算
假设左表R有M个page,m个tuple
右表S有N个page,n个tuple
join算法
Nested Loop Join
simple/stupid
block
index
Sort-Merge Join
Hash Join
simple
GRACE(Externally partitioned)
Hybird
Simple Nested Loop Join
通过两层for循环,然后符合条件的进行输出
IO计算:因为外层循环要读取 M 个 page,循环的tuple 是 m,内存循环要读取N个page,所以内层循环的IO数是 m * N,总的IO:M + (m * N)
假设 M = 1000, m = 10 0000, N = 500, n = 40000, 总的IO = 1000 + (10 0000 * 500) = 5000 1000
假设 SSD 执行速度 0.1ms 一次IO,大概需要1.3个小时
如果N是左表,那么总IO = 500 + (4000 * 1000) = 400 0500,大概需要1.1个小时
所以如果左表是小表,性能更好
1 2 3 4 5 6 7 for (Tuple r: R) { for (Tuple s: S) { if (s.id == r.id) { } } }
Block Nested Loop Join
对simple的优化,不在循环tuple,而是循环page,将page打包成block,然后循环block
这样的话对于内层循环来说IO就是 M * N,总的IO就是 M + (M * N)
假设 M = 1000, m = 10 0000, N = 500, n = 40000, 总的IO = 1000 + (1000 * 500) = 50 1000
假设 SSD 执行速度 0.1ms 一次IO,大概需要50s
1 2 3 4 5 6 7 8 9 10 11 12 for (Block br: R) { for (Block bs: S) { for (Tuple r: br) { for (Tuple s: bs) { if (s.id == r.id) { } } } } }
Block Nested Loop Join优化
假设buffer pool容量是B,可以先获取B - 2个左表的Block,剩下2个位置,一个是获取右表的 Block 的,一个是输出的。
这样的话总的IO次数:M + ([M/(B-2)] * N), M/(B - 2)向上取整
最好的情况是 B > M + 2,代表一次性能获取所有的左表的Block
这样总的IO就变成 M + N
假设 M = 1000, m = 10 0000, N = 500, n = 40000, 总的IO = 1000 + 500 = 1500
假设 SSD 执行速度 0.1ms 一次IO,大概需要0.15s
Index Nested Loop Join 假设s.id有索引,那么就可以根据索引进行匹配,加快速度.
总的成本将是M + (m * C) C是索引需要的时间
1 2 3 4 5 6 7 for (Tuple r: R) { for (Tuple s: Index(r = s)) { if (s.id == r.id) { } } }
Sort Merge Join
Sort:先对要join的字段进行排序
Merge: 用两个指针进行匹配,如果数据匹配就输出,因为数据已经排序好了,所以只需要扫描一次就行了
这样的话总IO就是 sort io + merge io, merge io = M + N, sort io看具体的排序算法
最好的情况是要join的key本身已经是有序的了,那么只需要merge io = M + N,比如有索引,比如查询的时候使用了order by
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 sort R,S on join keys cursorR = RSorted, cursorS = Ssorted;while (cursorR && cursorS) { if (cursorR > cursorS) { cursorS++; } if (cursorR < cursorS) { cursorR++; } if (cursorR == cursorS) { cursorS++; } }
Hash Join
Build: 先对左表要join的key进行hash,构建一个hash table
probe: 在对右表要join的key进行hash, hash相同的会放入同一个 bucket,也就完成了匹配
1 2 3 4 5 6 for (Tuple r: R) { insert hash (r) into hash table ht } for (Tuple s: S) { insert hash (s) into hash tbale ht }
Hash Join优化
可以添加 布隆过滤器 来优化,这样的话在probe阶段,对右表的key, hash以后先查询布隆过滤器,如果false,就不需要在放入hash table去匹配了
如果true在去hash table里面匹配数据完成输出
Grace Hash Join
在 hash join中,只构建一个hash table来存储左表数据,右表的hash完成直接匹配
Grace hash join中,构建两个hash table,然后进行 nested loop join
总的IO: 3(M + N),大约0.45s
hash 几乎总是好的。
non-uniform数据,排序更好
对于需要排序的数据,比如order by,排序更好
query exec processing Method
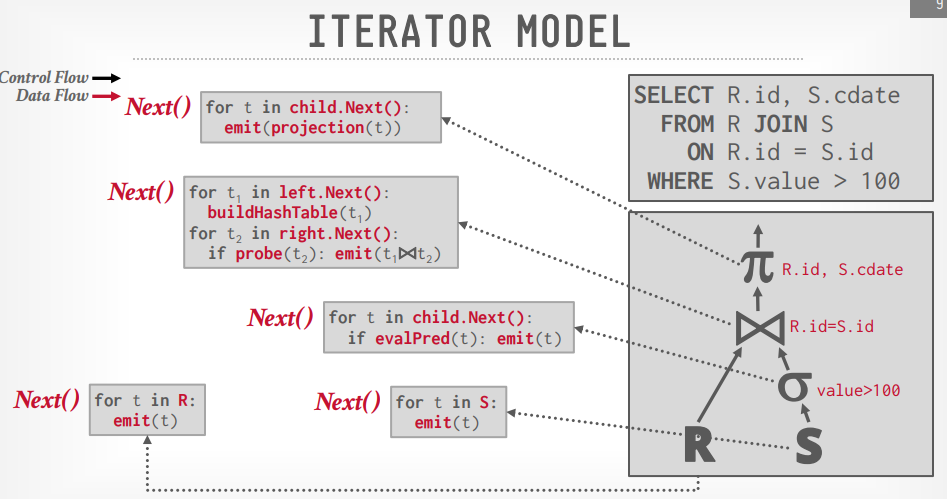
Iterator Model: 大多数数据库使用的
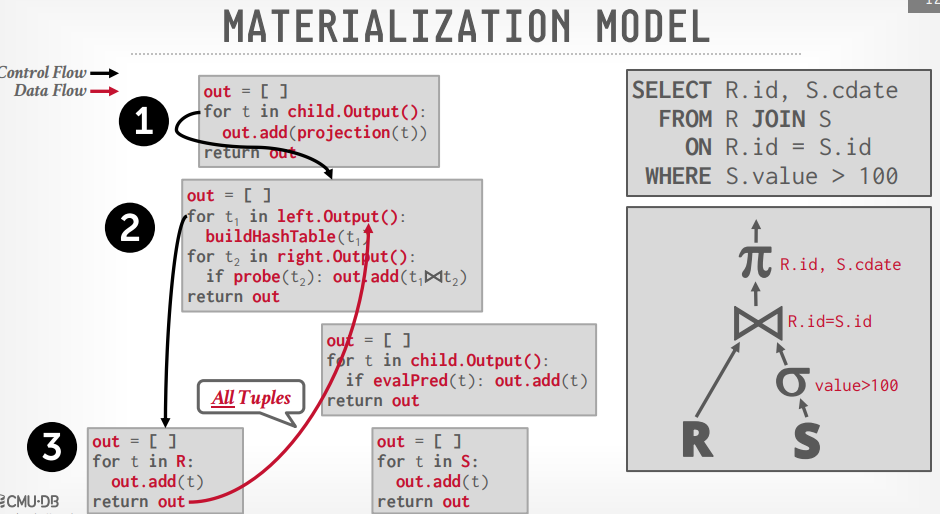
Materialization Model:Iterator Model的一个特定版本,用在内存型数据库
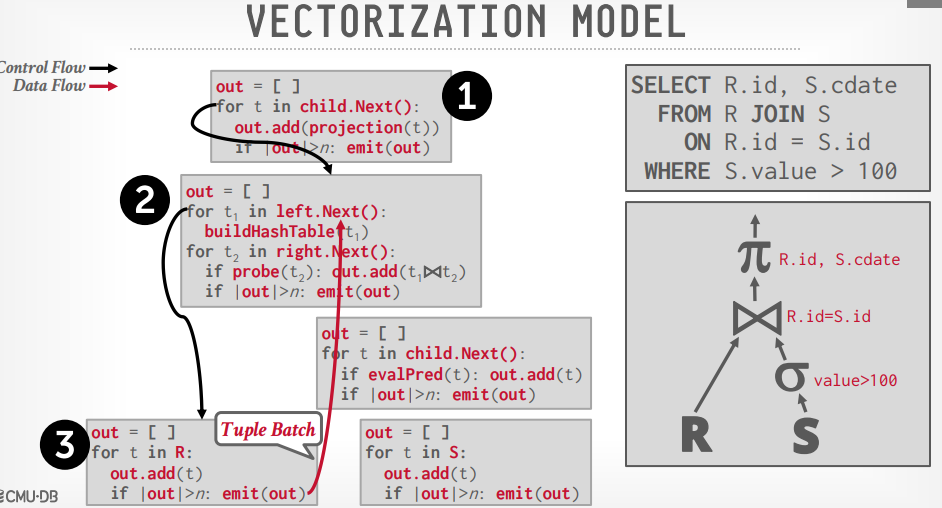
Vectorized/ Batch Model:Iterator Model差不多,要传入一大堆东西, 分析型用的多
Iterator Model
像java的stream, 流的方式执行
先构建执行树,上层的通过next方法调用下层的方法并接收返回值
Materalization Model
去掉了next方法,使用了output方法,一次输出所有数据给上层
Vectorized Model
使用next方法,但是一次性返回一堆 tuples, 数量取决于 Buffer pool 大小
使用OLAP,大多数的数仓使用这个
Access Method
顺序扫描的优化
多索引扫描
Zone Maps
通过在page上面增加一个元数据,存储min,max,avg,count,sum信息
当查询的时候比如where val > 600,先查询 Zone Maps,如果发现max < 600,那么就不用在扫描这个page了
缺点是插入,更新,删除的时候还需要更新Zone Maps信息,所以适用于 OLAP数据库
late materialization
Expression Evaulate
先建立where条件的 Expression tree,中间节点是操作符,比如=,>,<,and,or等。子节点是两边的值
对于每个tuple执行这个表达式
好的数据库会对表达式进行优化,比如优化成常量,像where 1 = 1优化成 trues
Process Models
Process per DBMS Worker
Process Model
Thread per DBMS Worker
Embedded DBMS
Process per DBMS Worker
每个进程是一个worker,负责执行任务
通过共享内存进行buffer pool的通信,要不然每个进程都会有一个buffer pool。
老得数据库大部分使用的这个,因为当时没有统一的线程API,像DB2,oracle,postgraSQL
Process Model
和 Process per DBMS Worker一样
但是增加了 worker pool,有多个worker进行调度处理
像DB2,postgraSQL(2015)
Thread per DBMS Worker
一个进程,多个线程执行,由数据库自己控制线程。
现在的数据库几乎都使用这种,像DB2, MSSQL, MySQL, Oracle(2014)
scheduling
将查询分解为多少个任务?
它使用多少个CPU核心?
哪个CPU执行哪个任务?
任务输出到哪里?
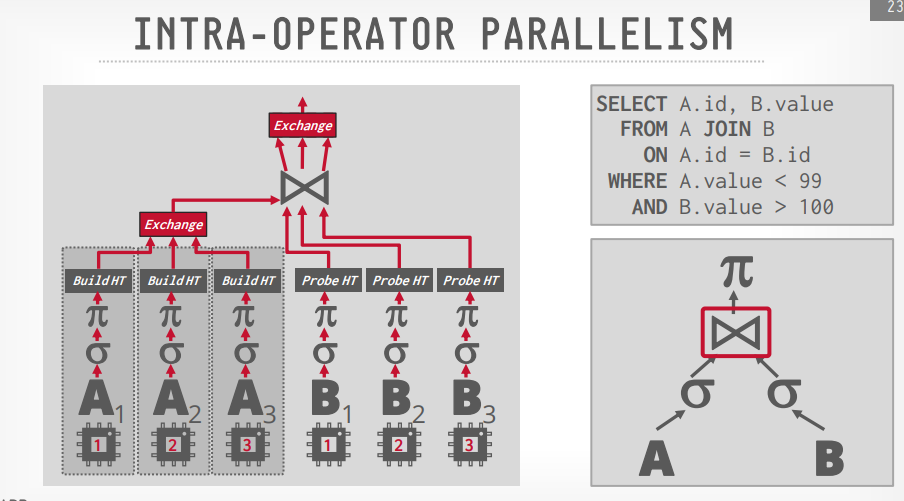
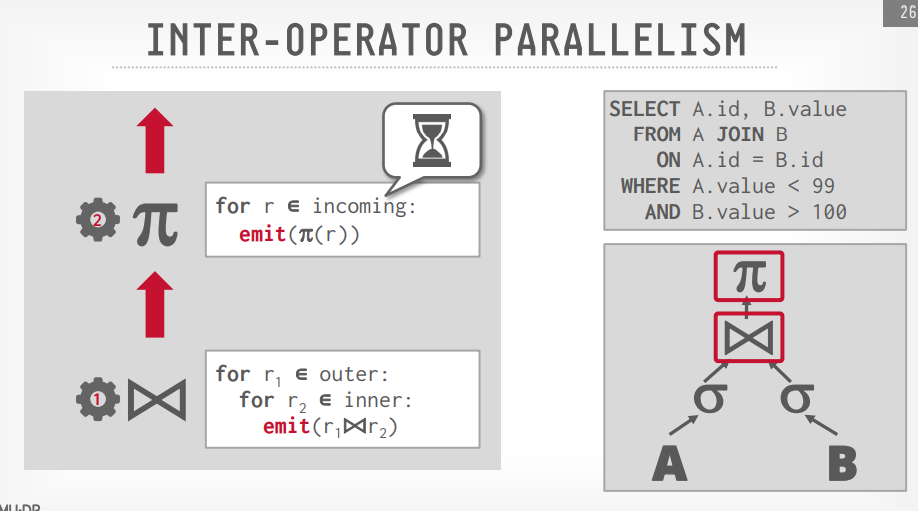
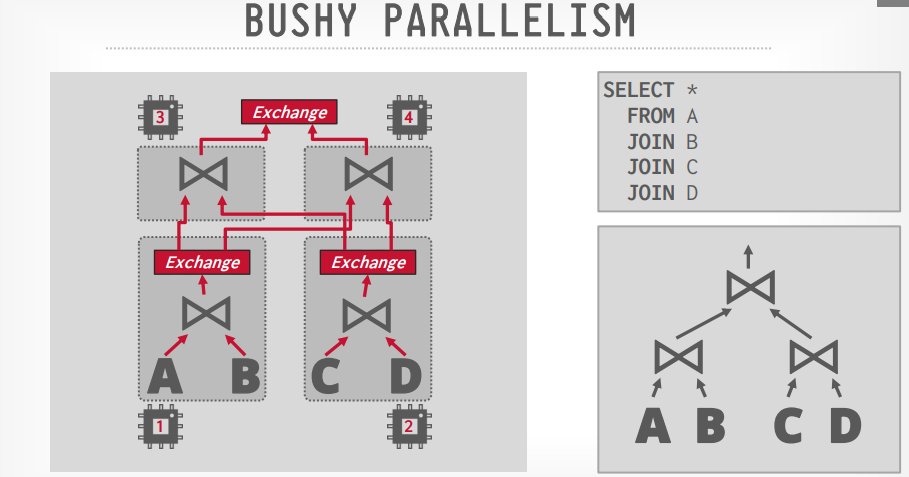
Intra query parallelism
Intra operator(水平)
Inter operator(垂直)
Bushy(上面两种的组合)
Intra operator(水平)
通过水平拆分数据,由多个线程执行,比如3个线程,一个线程处理一个page,以此类推
处理完成以后通过exchange operator来进行合并,拆分也是通过它。
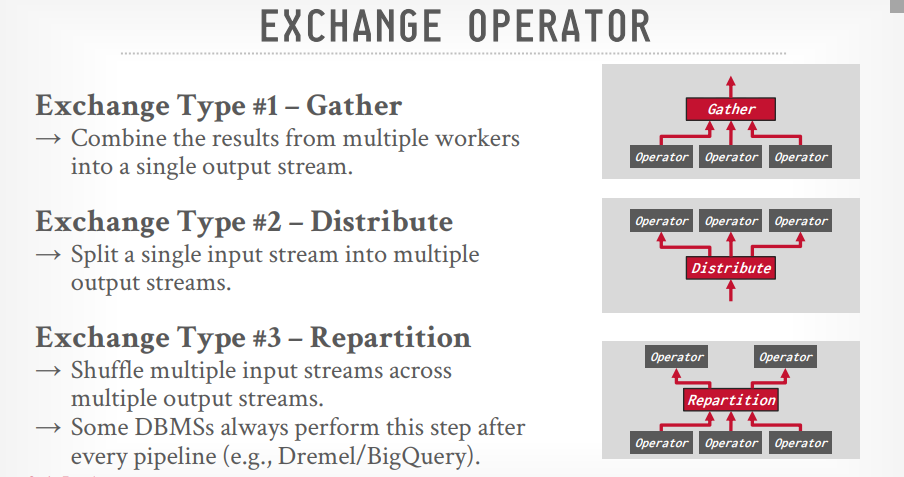
Exchange operator
Gather:从多个线程的结果合并成一个输出流,PostgreSQL用这个
Repartition: 重新组织多个输入流到多个输出流的数据,像group by,BigQuery用这个
Distribute: 拆分一个输入流到多个输出流
Inter operator(垂直)
重叠的操作从一个阶段到下一个阶段的pipeline数据,没有具体化
workers同时执行多个operators从一个查询计划的不同部分
也需要用到exchange operator
Spark,Kafka常用这个
Bushy
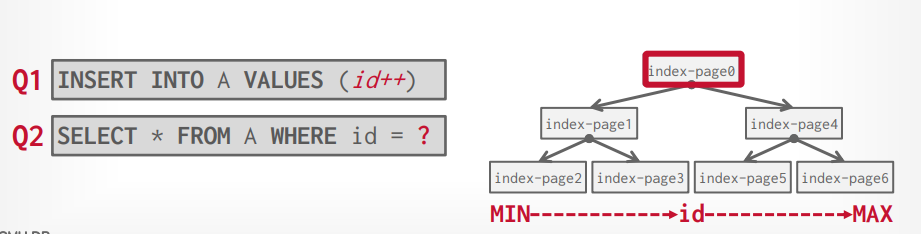
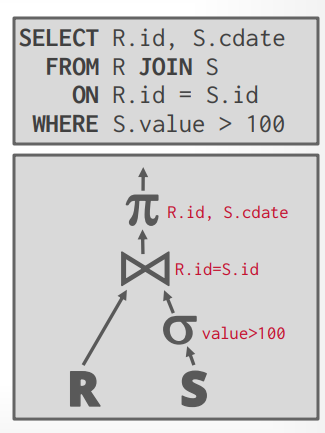
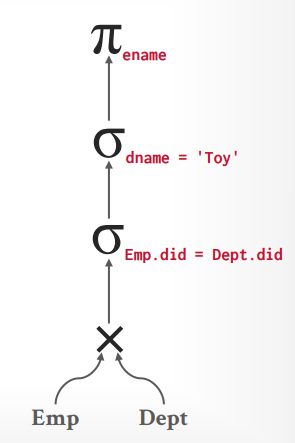
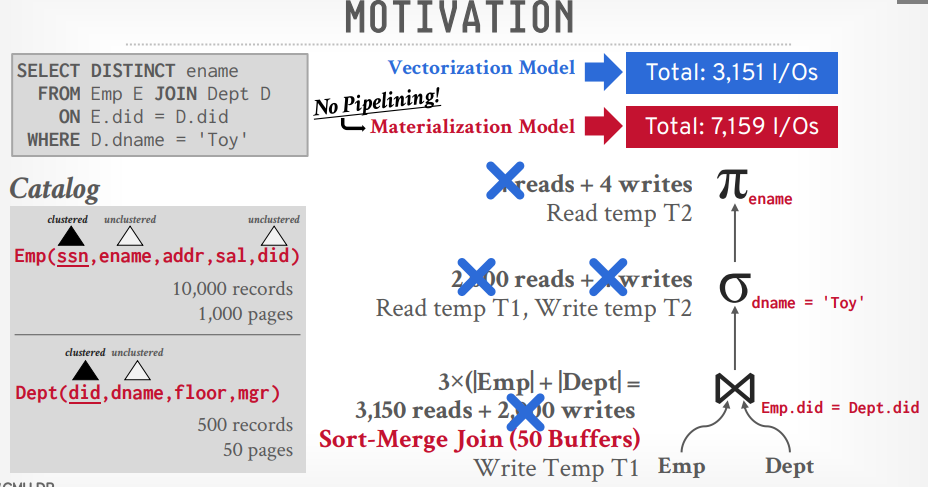
查询计划 假设有以下sql,其中Emp表有10000个records, 1000个pages, Dept表有500个records, 50个pages
1 select distinct ename from Emp E join Dept D on E.did = D.did where D.dname = 'Toy'
数据库将构建以下关系代数的树
按照这个关系代数的树来执行的话,总共需要 2M的IO
接下来将笛卡尔积的代数换成join的代数,就算使用Nested Loop Join,也能获得54K的IO
如果将Join算法替换成Sort-Merge Join,则可以将IO降低到7159
这个算法是基于Materialization Model的,所以每次还要写入文件,再读取。如果优化成Veectorization Model,减少重复的写入和读取,可以达到3151的IO
wraning:
这非常难!
Andy对这部分知道的是最少得
如果搞好了,很挣钱
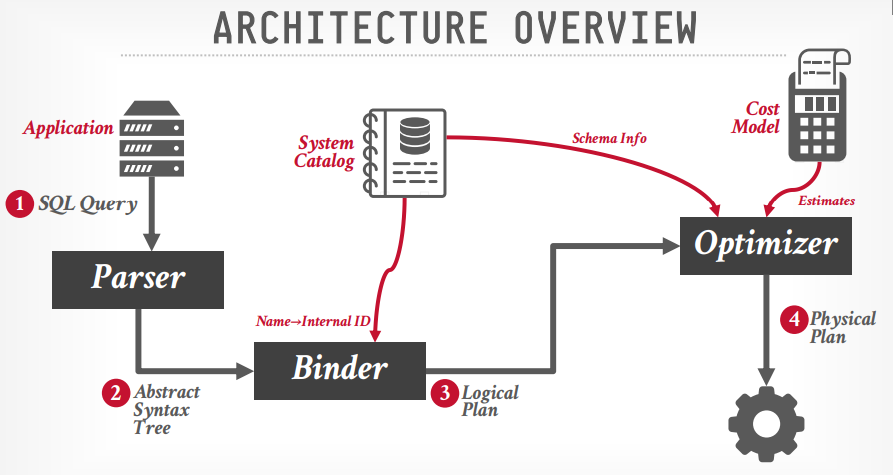
查询结构
SQL rewrite (可选):重写sql语句,对sql语句进行优化
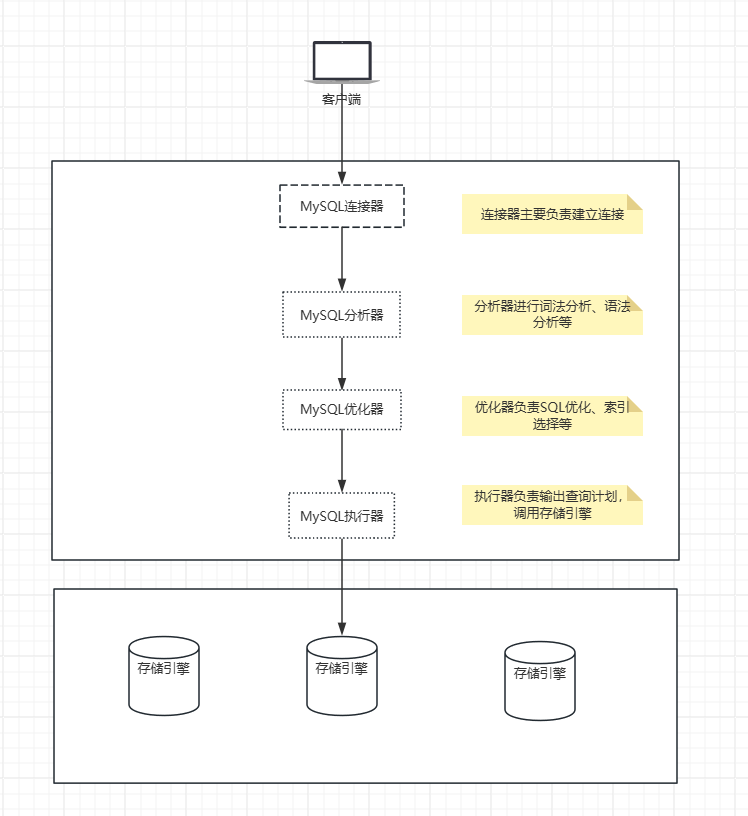
Parser: 解析SQL查询,构建语法树
Binder: 查询catalog信息,并将表名等信息替换成内部标识,生成逻辑查询计划
Tree rewrite (可选):重写树结构,包括关系代数等
Optimizer: 调用成本模型,预估成本,选择合适的执行计划,生成物理执行计划
生成物理执行计划的时候,可能有多个执行路径,在短时间内可能无法从全部的路径中选出最佳的。
查询优化
查询优化是很难的,有些数据库的查询优化做的很差,DB2曾引入机器学习做查询优化,效果并不好,被吐糟安装DB2要做的第一件事就是关掉这个功能
查询优化
静态规则/条件触发
根据静态的规则,或者触发了某一个条件来重写查询,移除低效率的东西
需要检查catalog查看信息,而不需要去检查数据
成本原则
使用模型预估查询成本
估计出多个查询计划,选择其中成本最低的一个
静态规则/条件触发 关系代数等价
一个查询语句可以用多个关系代数来表示
可以选择其中代价更小的那个关系代数
这个被叫做 query rewriting 属于上面的 Tree rewrite阶段
比如用join代替笛卡尔积
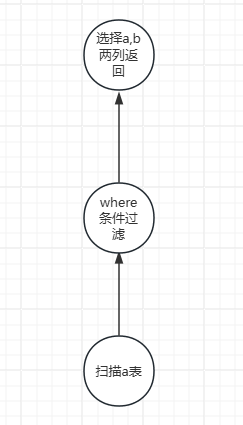
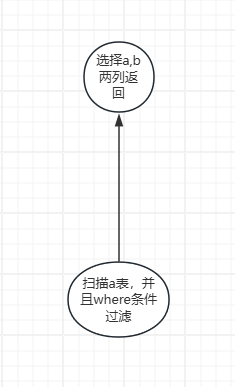
predicate pushdown
比如select a.name,b.code from a join b where a.name = ‘abc’
可以先join在where,也可以先where 再 join
显然先where更好,把where放到join的下层执行
还有可以再where之后只获取需要的列,其余不需要的列就不再往上层传递了
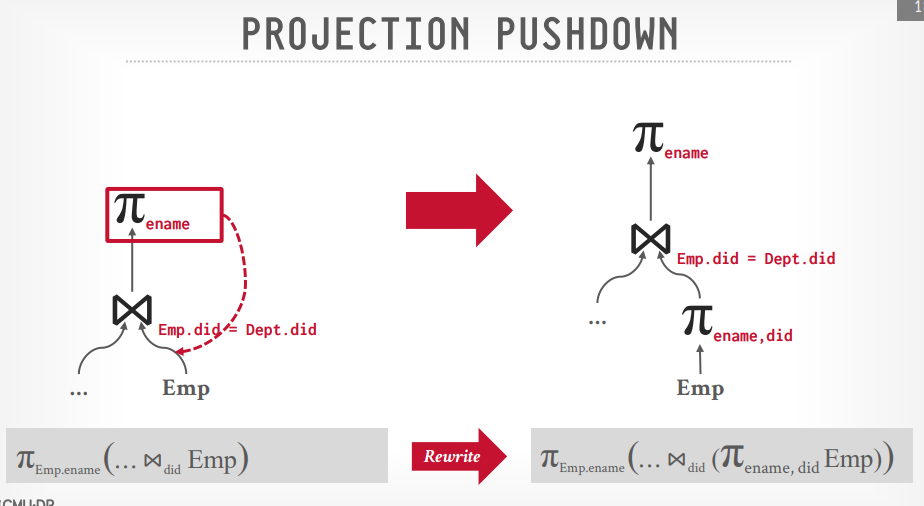
projection pushdown
比如select a.name,b.code from a join b on a.id = b.aid
可以在扫描a表的时候进行投影,获取id和name传到join节点处理,而不是全部字段传过去,b表同样
语句重写
比如select * from a where 1 = 0; 那么不会返回任何数据。
select * from a where 1 = 1 会返回所有数据,重写成select * from a
成本原则
mongoDB没有使用成本预测模型,而是执行所有的查询计划,哪个最先返回就用哪个
最初是IBM提出的。枚举不同的查询计划,并估算他们的成本,在检查完所有的计划或者超时后,选择其中成本最低的一个。
single relation
multiple relation
nested sub-queries
single relation
单表是比较简单的,比如根据后面的statistics决定走哪个索引更好
可以顺序扫描
可以二分搜索
可以走索引
对于单表查询来说,一般会使用启发式规则,他来判断哪些where条件能筛掉更多的数据,就先进行哪个where。
sargable (search argument able):他会比较不同的索引,比如这个索引合适,那么就会使用它,比如id=1的,那么就会使用主键索引
multiple relation
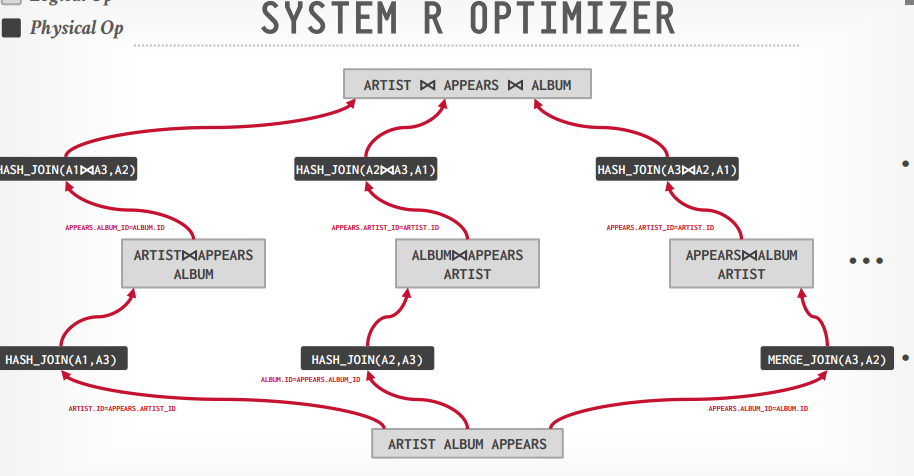
system R 优化
这是一个自底向上的multiple relation
将查询分成block并为每个block生成逻辑运算
为每个逻辑运算生成物理运算并实现它
组合所有的join算法和访问路径
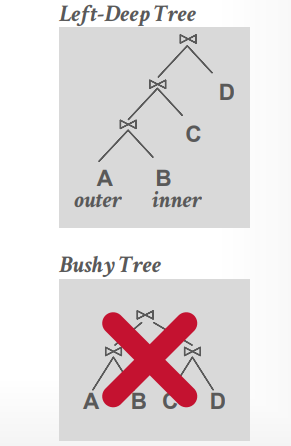
生成一个left deep的树
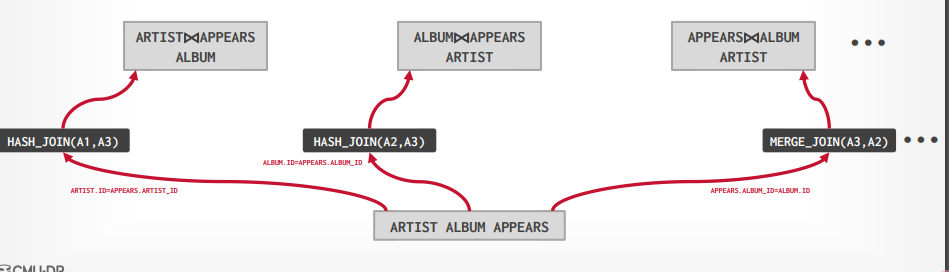
比如有下面的SQL,ALBUM.NAME 字段有索引
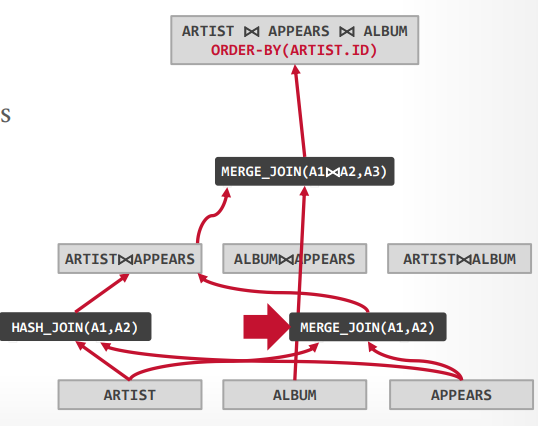
1 2 3 4 5 6 SELECT ARTIST.NAME FROM ARTIST, APPEARS, ALBUM WHERE ARTIST.ID= APPEARS.ARTIST_ID AND APPEARS.ALBUM_ID= ALBUM.ID AND ALBUM.NAME= "Andy's OG Remix" ORDER BY ARTIST.ID
进行第一步,可以得到三个表的扫描方法
ARTIST:顺序扫描
APPEARS:顺序扫描
ALBUM:索引扫描
接下来组合不同的join算法,我们可以先连接ARTIST和APPEARS表,也可以先连接APPEARS和ALBUM表,或者ALBUM和ARTIST表,并且可以使用hash join 或者 merge join
最终为每个可能选择成本最低的join
接下来为每个可能去join其他表,来完成最终的三个表join,这个时候还是有hash join和merge join,选择最适合的join方法,就会产生三个路径
在从这三个中选择出成本最低的一个路径作为最终的路径
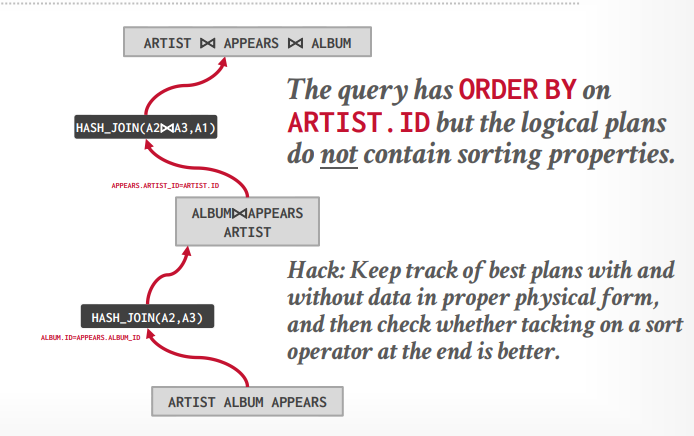
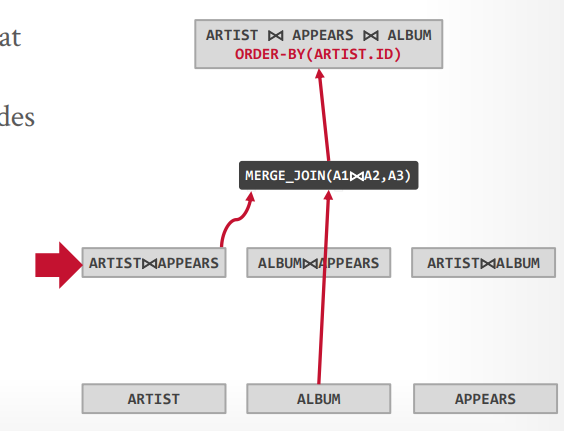
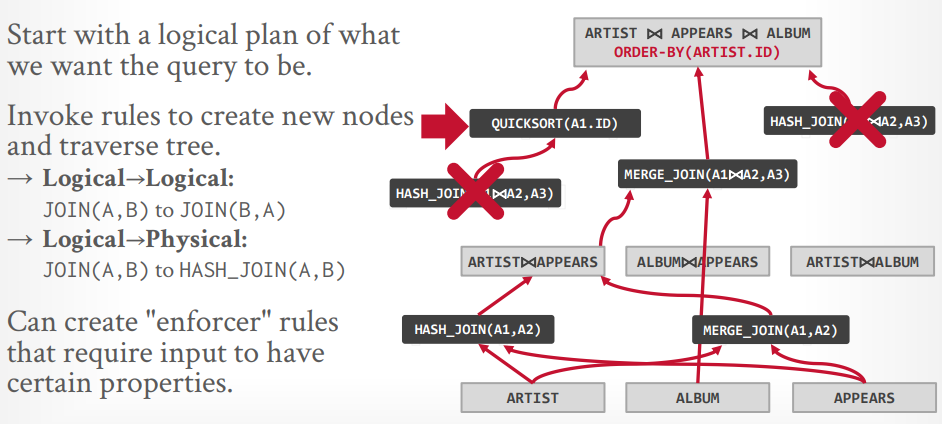
自顶向下优化 首先生成逻辑节点,最底下是三个表,最上面是三个表join并且order by,中间是两个表join
接下来先生成三个表的一个物理操作,因为需要order by,所以可以认为merge join更好。
接下来两个表的物理操作,可以选择hash join或这merge join,因为要排序,可以认为merge join更好
最后在探测其他的路径,比如最上层还可能有hash join,或者先hash join,在排序,但是这些都没有merge join的成本低,所以在探测到以后就可以Pass掉了
子查询优化
比如以下SQL
1 2 3 4 5 6 SELECT name FROM sailors AS SWHERE EXISTS ( SELECT * FROM reserves AS R WHERE S.sid = R.sid AND R.day = '2022-10-25' )
可以被重写为
1 2 3 4 SELECT name FROM sailors AS S, reserves AS R WHERE S.sid = R.sid AND R.day = '2022-10-25'
分解子查询并将结果存储在临时表中,比如使用CTE,避免每个tuple都需要执行子查询
比如下面的SQL
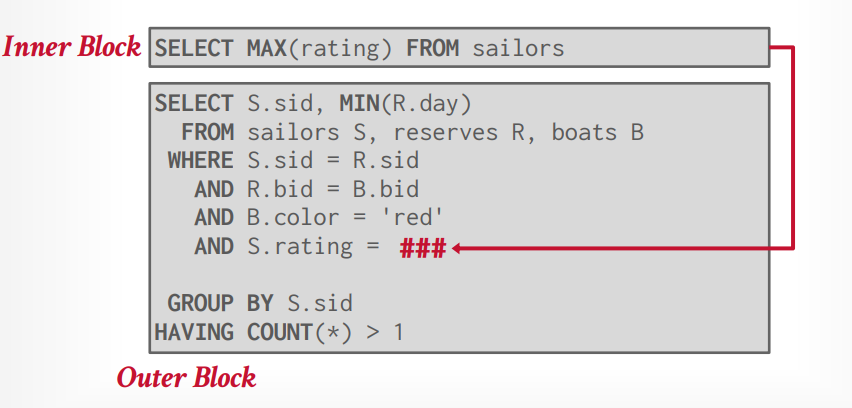
1 2 3 4 5 6 7 8 9 SELECT S.sid, MIN (R.day) FROM sailors S, reserves R, boats B WHERE S.sid = R.sid AND R.bid = B.bid AND B.color = 'red' AND S.rating = (SELECT MAX (S2.rating) FROM sailors S2) GROUP BY S.sidHAVING COUNT (* ) > 1
可以将子查询提取出来变成
catalog会记录一些成本信息,不同的DBMS有不同的更新策略,也可以手动更新,这被叫做statistics
PostgreSQL/SQLite : ANALYZE
Oracle/ Mysql: ANALYZE TABLE
SQL server: UPDATE STATISTICS
DB2: RUNSTATS
statistics: 维护着下面的信息
counter: 表中的tuple数量
V(A,R): R表中的A字段的去重数量
SC(A,R): 选择基数SC 是 counter / V(A,R) 的值
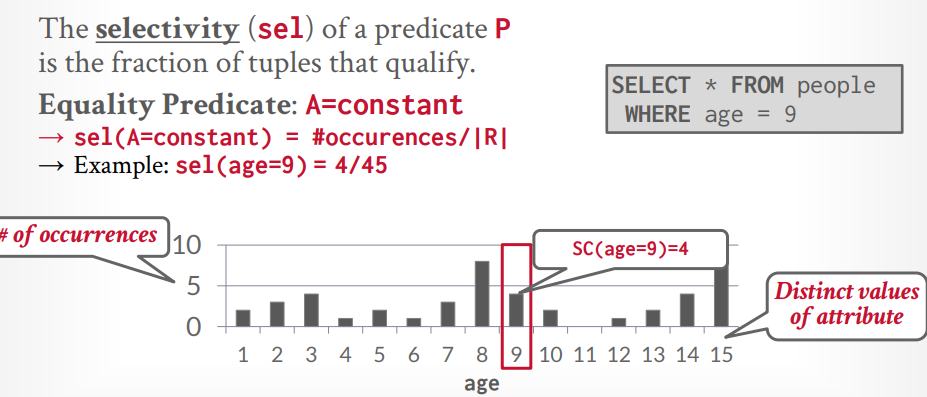
选择率:有了上面的数据,就可以计算出要查询的数据的分布比例了。这里就是求概率。
比如查询主键 id = 1的数据,当前有数据5条,那么counter = 5,V(A,R) = 5, SC(A,R) = 1, 选择率 = 1/5
比如范围查询 id > 2的数据,当前有数据5条,那么counter = 5, V(A,R) = 5, SC(A,R) = 1, 选择率 = (Max - A) / (Max - Min) = 5-2/5-1 = 3/4,显然这事错误的预测,但是数据库就是这样
比如not查询 id <> 1的数据,当前有数据5条,那么选择率 = 1 - (id = 1的选择率) = 1 - 1/5 = 4/5
比如多个条件 and, 那么取交集,也就是 两个选择率 相乘 = sel(AB),这种计算同样不太准确,比如有一个汽车表,有make字段代表生产商,model代表型号,我们知道model = “帕萨特”,make 一定是 大众。按照我们的算法 假设make 有10个,选择率就是1/10, model 100个,选择率就是 1/100,总的选择率就是 1/1000,但是帕萨特一定是大众的,所以真实选择率其实是1/100。有些数据库可以设置字段关联来解决这个问题,比如oracle等,mysql和postgresql不行。
比如多个条件 or, 那么取并集,也就是两个选择率相加 = sel(A) + sel(B) - sel(AB)
直方图的存储,由于存储所有信息的直方图可能很占空间,可以选择稀疏存储,合并一些数据,这样会牺牲一些准确率,但是节省空间。
除了直方图以外,有些数据库还会使用抽样检查,花费一些时间进行抽样,然后根据样本来进行预测选择率。
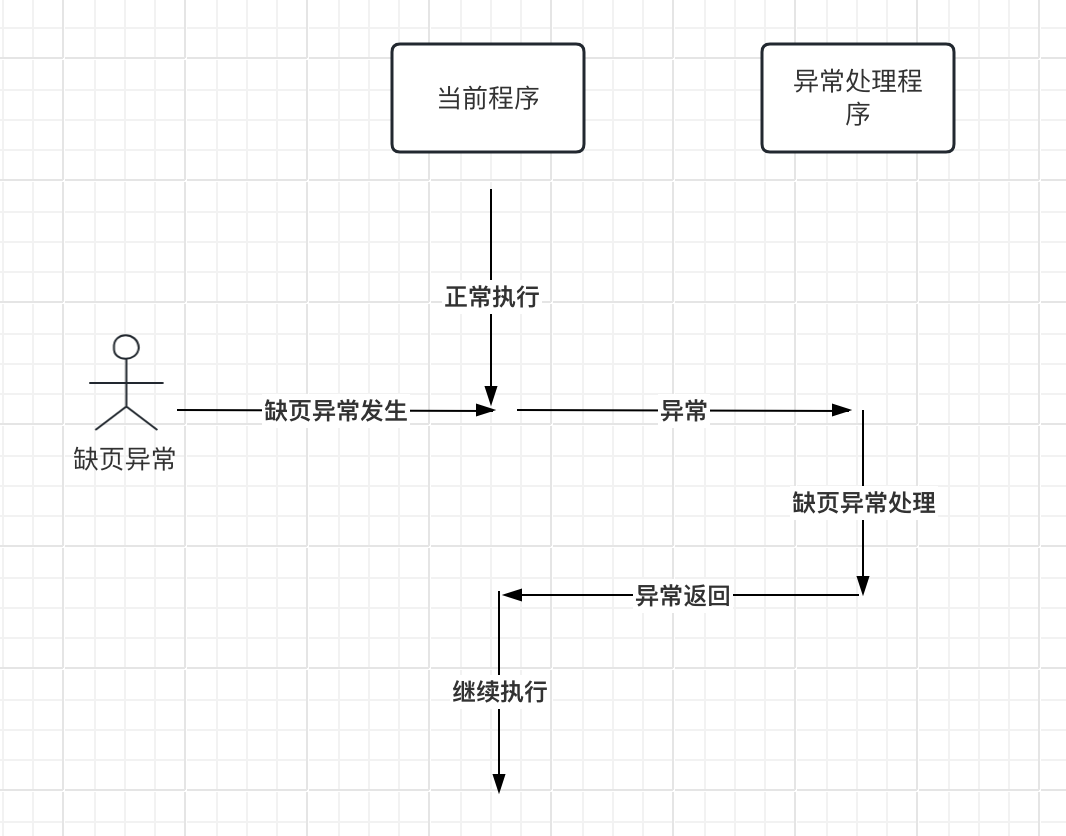
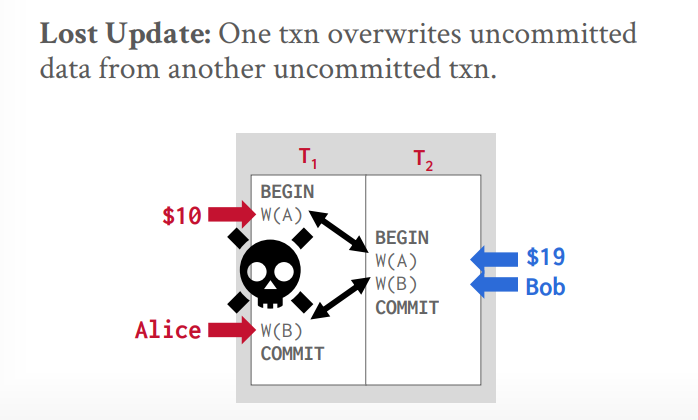
并发控制原理 原子性:事务的每个操作都是原子的,要么全成功,要么全失败,通过undo redo log实现并发控制协议来保证交错执行,通过latch保证正确性。通过并发控制实现
当转账的时候,事务被突然的中止,或者断电,该怎么做?
Logging
记录所有的操作,使得事务中止或者故障后可以undo 操作。
在磁盘和内存中维护 undo records
就像飞机上的黑盒子一样
shadow paging
将数据复制到一个副本中进行事务更新,如果成功了,将副本作为新的数据库,如果没成功也不影响当前的数据库
起源于System R
CouchDB和LMDB使用这个方法
并发控制协议:
顺序执行:
交错执行:
如果能达到顺序执行的结果,那么就是正确的执行 schedle
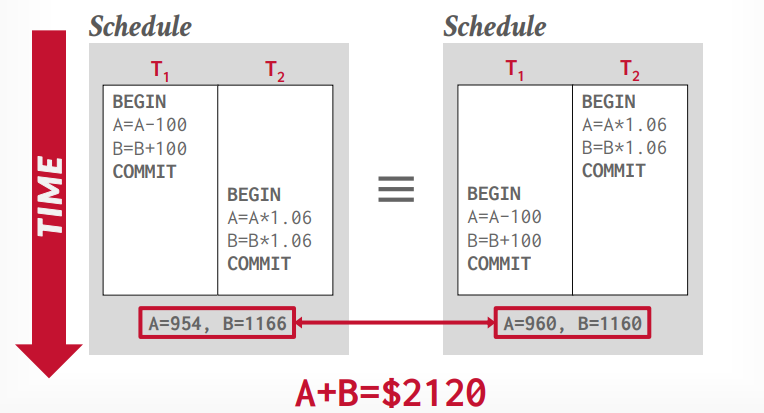
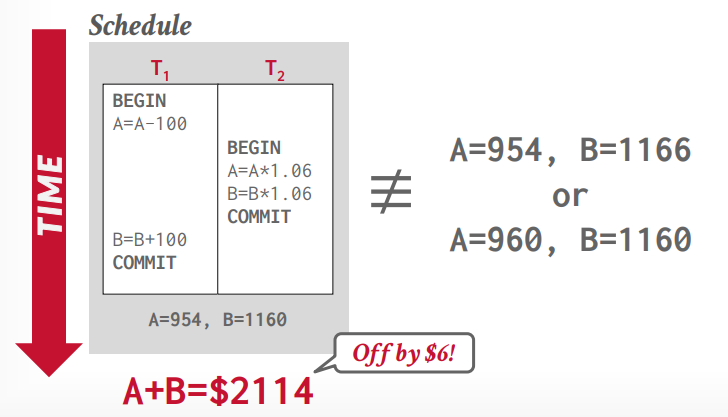
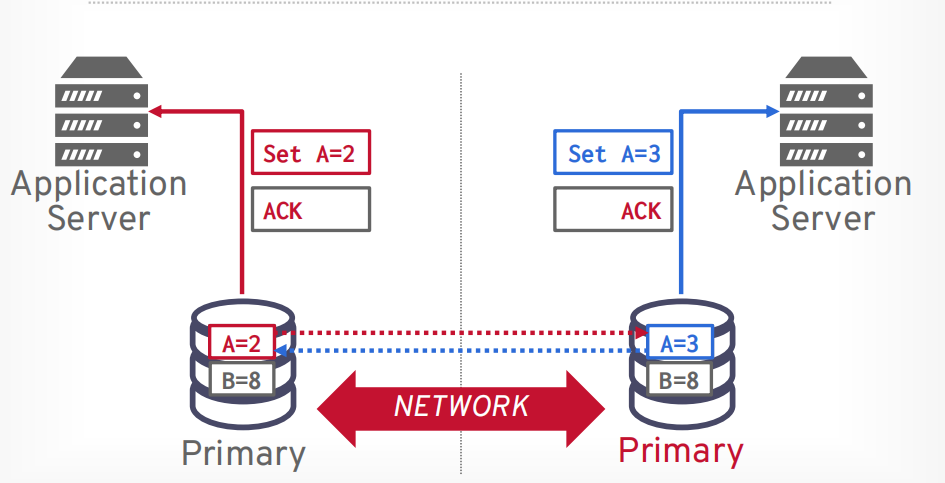
假设a,b账户都有1000,那么经过t1事务和t2事务执行以后,总的结果应该不变,对于数据库来说,哪个事务先执行都可以,如果想控制事务执行顺序,应该由应用层控制。
如果交错执行的结果和顺序执行的结果不一样,就是错误的
总共会出现三种冲突
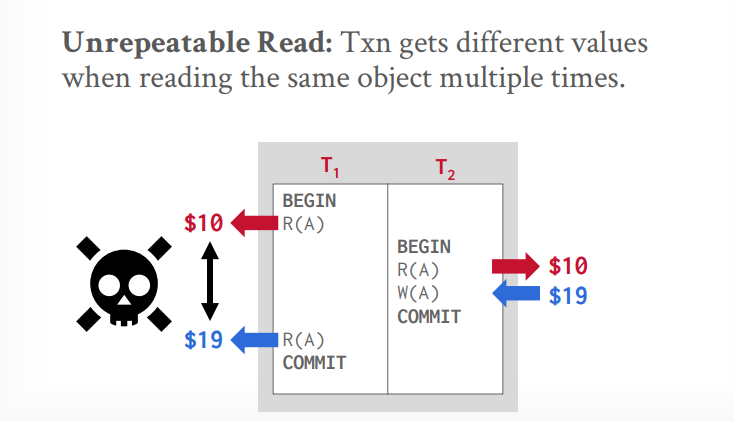
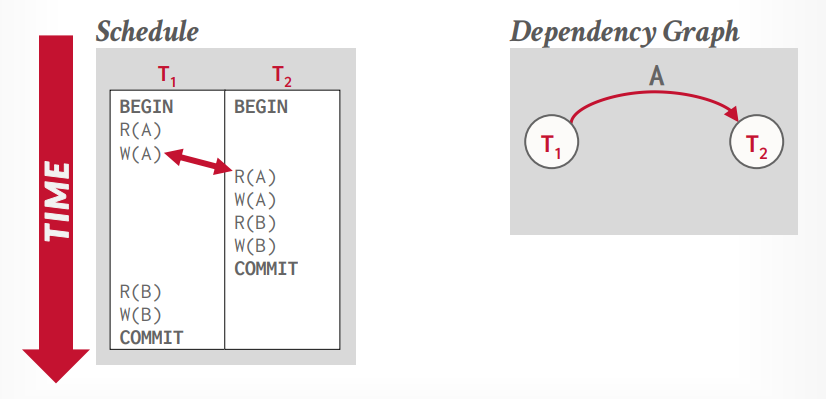
读写冲突(不可重复读):当读第一次的时候,值被其他事务改变了,再次读的时候,值就和第一次读的时候不一样了
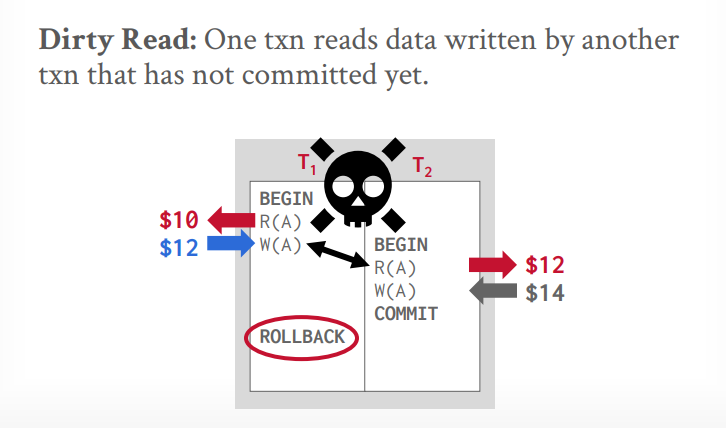
写读冲突(读未提交或脏读):A事务读取后,修改了值,B事务读取了修改的值,然后又修改了值,B事务提交后,A事务中止,回滚。
写写冲突(覆盖数据):两个事务同时写入一个值,有一个值会被覆盖掉。
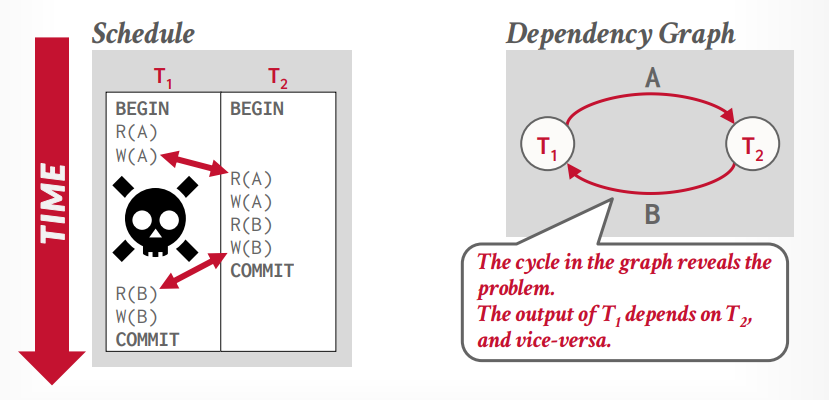
冲突可串行化,大多数数据库使用的,还有个视图可串行化,没数据库实现
通过比较两个操作是否冲突,来修改顺序
使用依赖图(优先图)来判断依赖是否出现环
假设事务t1写入了A数据,事务t2同时读取A数据,那么事务t2就依赖了事务t1
假设事务t2又写入了B,事务t1要读取B,那么事务t1就依赖了事务t2,这个时候就产生了循环依赖,就跟死锁一样,所以这个时候需要回滚一个事务
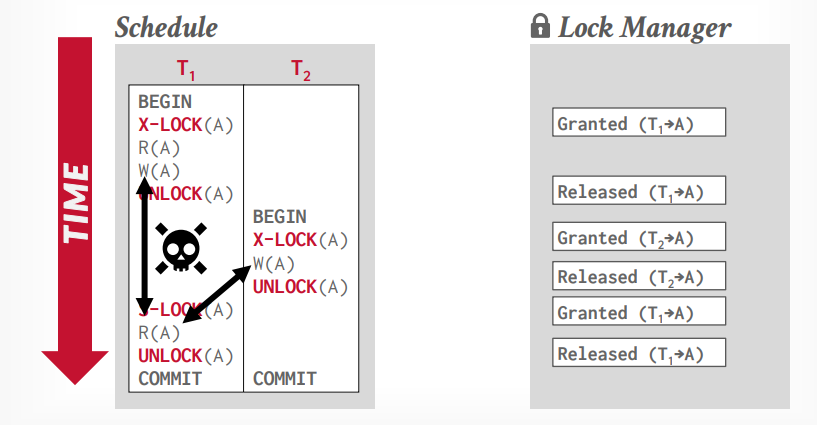
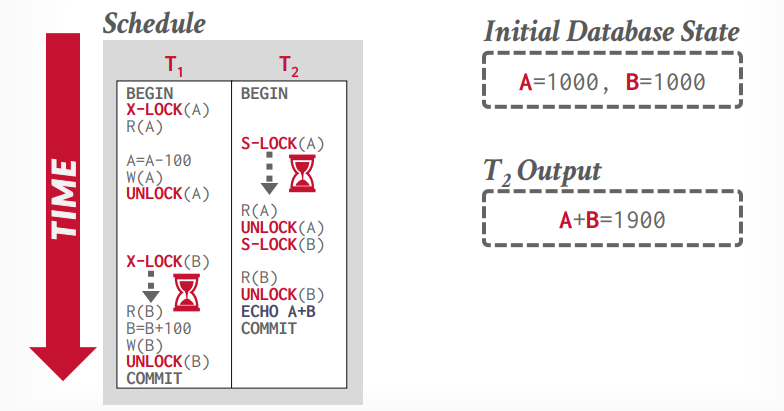
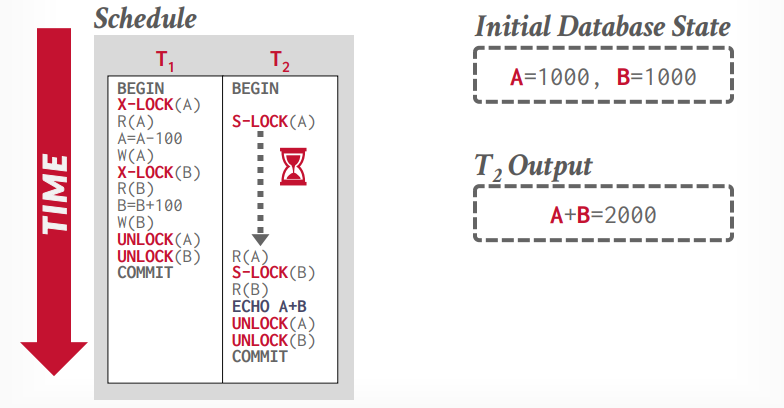
两阶段锁 事务A先获取锁,事务B等待锁,事务A执行完成以后,释放锁,事务B才能拿到锁。
共享锁,读锁,S-LOCK
如上图所示,这样还是会出现不可重复读的问题,两阶段锁可以解决这个问题,两阶段锁是第一个正确的并发控制协议
两阶段锁,遵循这个方法,使得事务是冲突可串行化的,但是会有级联事务中止(cascading aborts),可以通过强严格两阶段锁解决这个问题。
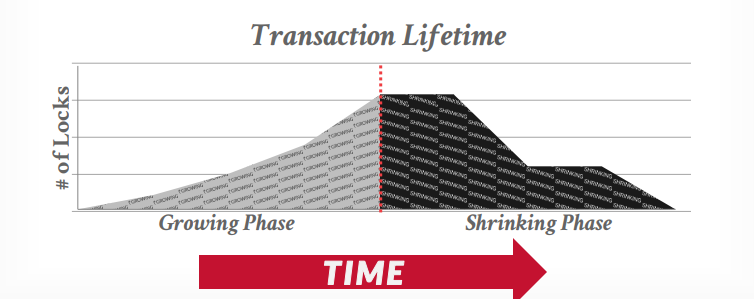
第一阶段Growing:每个事务从lock manager获取锁,事务释放锁以后进入第二阶段shrinking
第二阶段Shrinking:事务释放锁以后不能获取新锁,只能释放锁或者提交事务释放持有的所有锁
从生命周期来看,第一阶段是上升,第二阶段只会下降,不会再次上升,下图是正确的生命周期
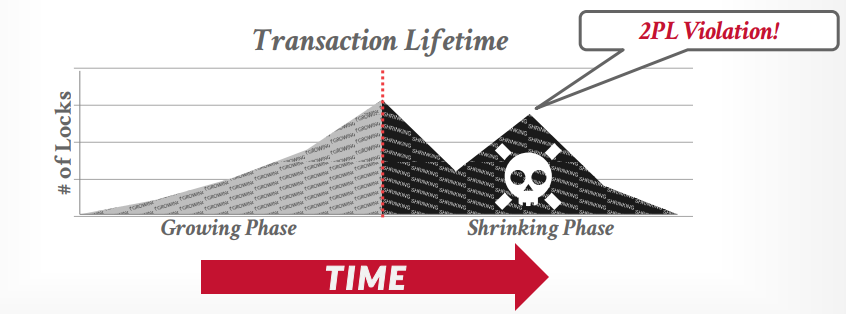
下图是错误的生命周期
cascading aborts,如果事务t1中止回滚了,那么事务t2就发生了脏读,所以也需要回滚重来
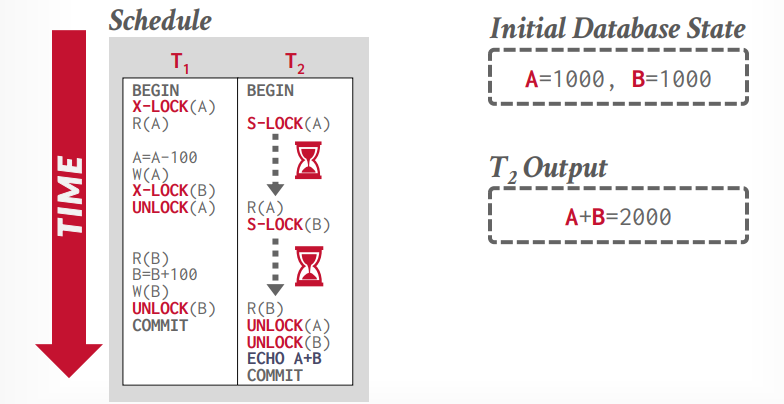
严格两阶段锁 在提交事务的时候才释放锁。可以解决脏读的问题。
非两阶段锁执行如下:
两阶段锁执行如下:
严格两阶段锁执行如下:
死锁 死锁检测:通过使用wait-for图来检测依赖关系,如果有环就是死锁
检测的频率可以通过参数调整,这个需要权衡
victim选择,选择出回滚哪个事务,这也是企业级系统和开源系统的区别
可以根据时间戳,选择年龄小的那个,认为刚加入的回滚成本小
根据持有锁的数量,选择持有锁少的那个回滚
根据已完成的工作量,选择查询数量少的那个回滚,可以认为回滚一个查询的成本比几十个查询的成本小
根据剩余的工作量
根据回滚的次数,这个事务老回滚,可能同情它不让它回滚,以避免“饥饿”
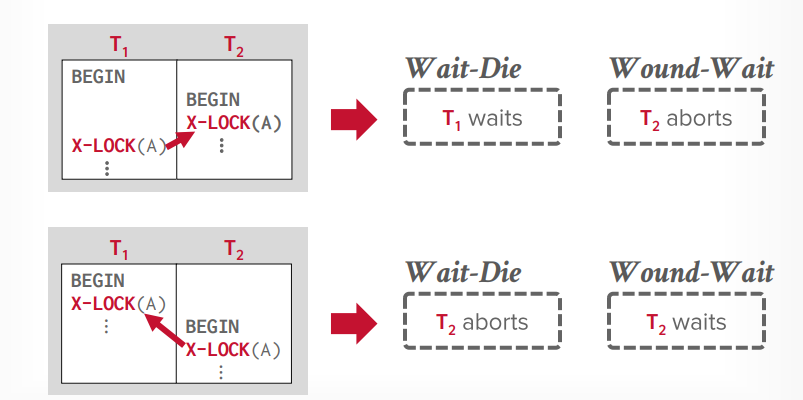
死锁预防 根据时间戳来选择
wait die: 老的等待新的,如果事务t1先开始,事务t2后开始,t2先获取了锁a, 然后t1要获取锁a,那么就等待,因为老的要等待新的,因为t1是老的,如果t1先获取锁a,t2新的后获取那么t2abort
wound die: 新的等待老的,如果事务t1先开始,事务t2后开始,t2先获取了锁a,然后t1要获取锁a,那么t2就abort,给老的让路,因为老的优先级高,如果t1先获取锁a,t2新的后获取锁a,那么就等待,因为新的等待老的
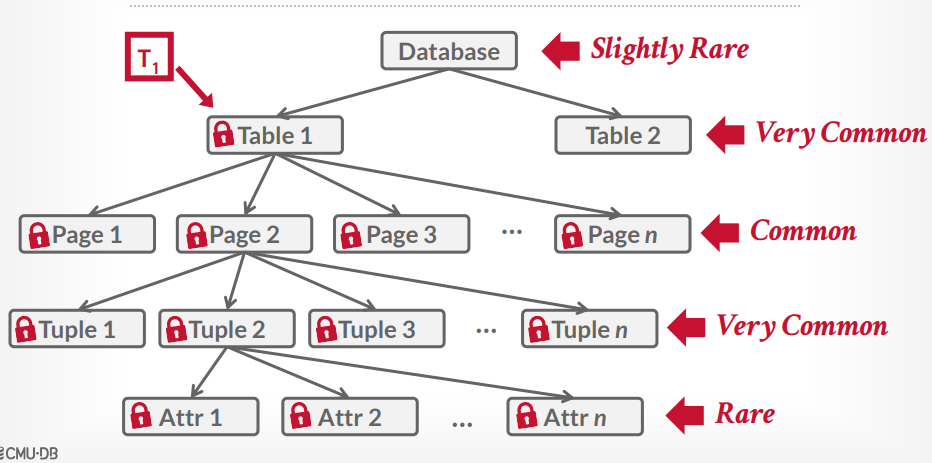
数据库锁层次
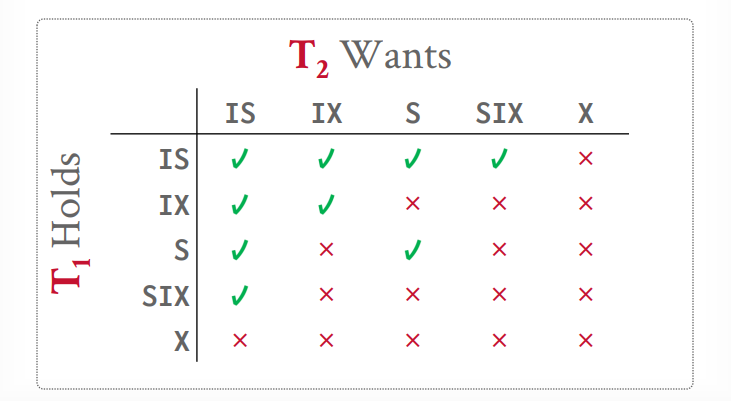
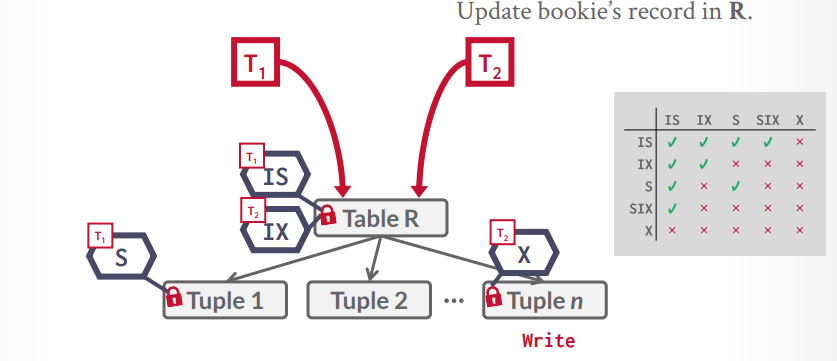
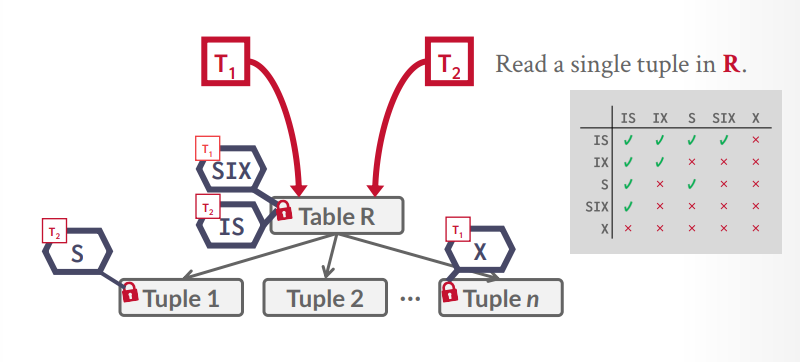
意向锁 意向共享锁IS
意向排它锁IX
共享意向排它锁
假设t1事务要查询一个tuple,那么可以在table上一个IS锁,然后在具体的tuple上一个S锁,接下来t2事务要更新一个tuple,发现表上是IS锁,那么根据规则,可以在table上在加一个IX锁,然后在要更新的tuple上一个X锁,如果恰好是同一个tuple,那么就等待S锁释放,如果不是同一个,那么就并发执行成功
假设t1事务要扫描所有tuple来找到一个tuple去更新,那么table上一个SIX锁,然后扫描到一个tuple,就给一个tuple上X锁,扫描完就释放X锁,接下来t2事务要读取一个tuple,发现表上是SIX锁,那么根据规则,可以在table上一个IS锁,然后在要查询的tuple上S锁,如果刚巧tuple上有X锁,那么就等待t1事务释放。
时间戳并发控制 两阶段锁是一种悲观的协议,所有人都会上锁,会争抢,时间戳是一种不依赖锁的乐观的协议。
Ti代表事务i得一个时间戳,Tj是j的,如果Ti < Tj,那么i得事务会在j之前提交。
时间戳的两个特性
唯一性,每个时间戳必须是唯一的
单调递增性,时间戳必须是增加的
基本时间戳协议 每个tuple需要维护两个时间戳,一个读时间戳,一个写时间戳。
读 在读取的时候要保证,当前时间戳 > 写时间戳,也就是读取的是最新的值,未来不会被改变的值。读时间戳,使用自己的时间戳和原来的时间戳中大的那个去更新。
写 写入的时候要保证,当前时间戳 > 读时间戳 并且 > 写时间戳
托马斯写入优化 在写入的时候,如果当前时间戳 < 写入时间戳,本来应该中止的事务,可以继续执行,但是写入操作不写入数据库,因为数据库的数据是更新的,而是写入本地副本,方便这个事务后面使用。
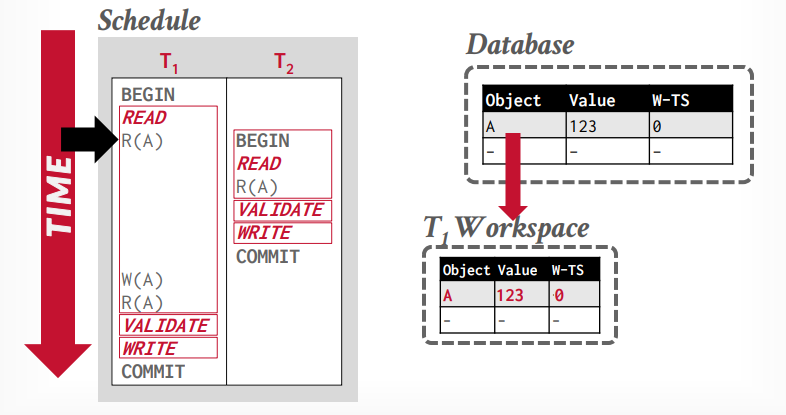
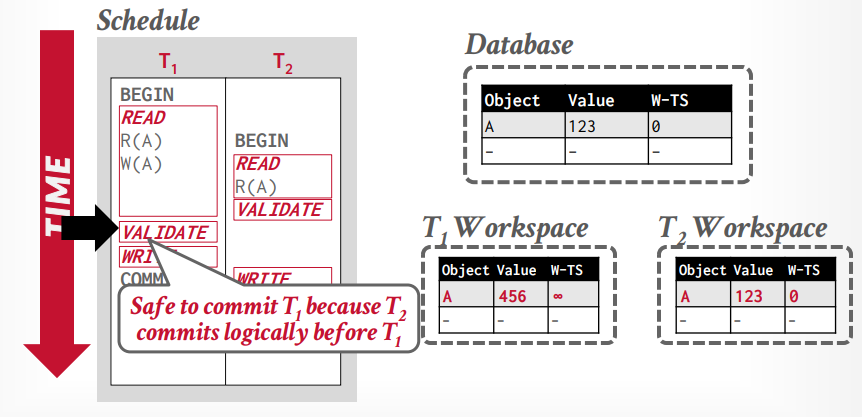
乐观并发控制 另外一个是乐观并发控制。为每一个事务创建一个私有空间,他的所有操作都是先对私有空间的副本操作,最后执行到数据库里面的时候需要对比一下,是否能执行。如果不冲突,就可以执行。
三个阶段
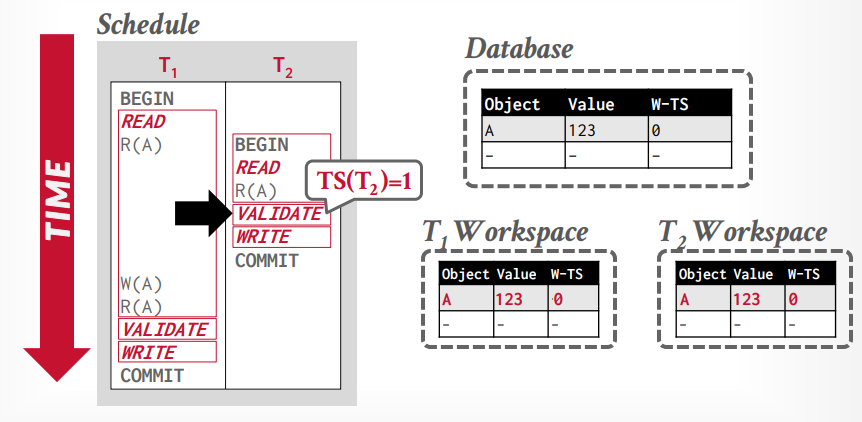
read phase(work phase): 执行事务的操作,操作都在私有空间执行。
validation phase: 提交事务的时候验证事务的有效性,是否冲突等,确实是否可以提交。在这个阶段才会分配时间戳。如果在之前需要写入时间戳,先暂时写入无穷大。并检测是否和其他事务的时间戳冲突,其他事务包括以前的所有事务和正在执行的事务
write phase: 如果校验成功,将时间戳写入W-TS列,将修改写入全局工作区,否则abort事务,这是原子的。
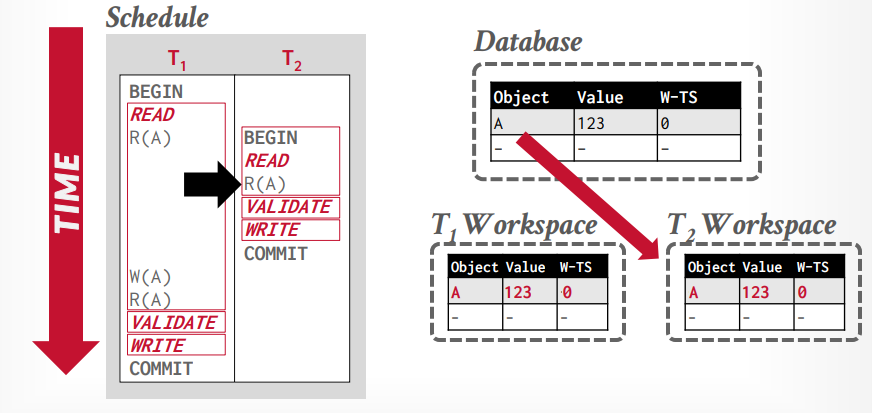
假设事务t1读取tuple A,将从全局工作区复制A到私有工作区
接下来事务t2读取tuple A,也将从全局工作区复制A到私有工作区
接下来事务t2进入validation阶段,然后分配时间戳为1,接下来进入写入阶段,什么也不做
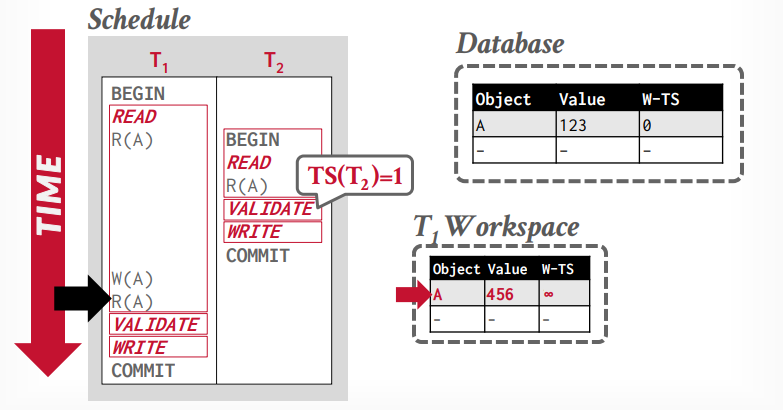
事务t1修改tuple A,然后再次读取tuple A,可以重复读取,因为读取私有工作区的tuple A
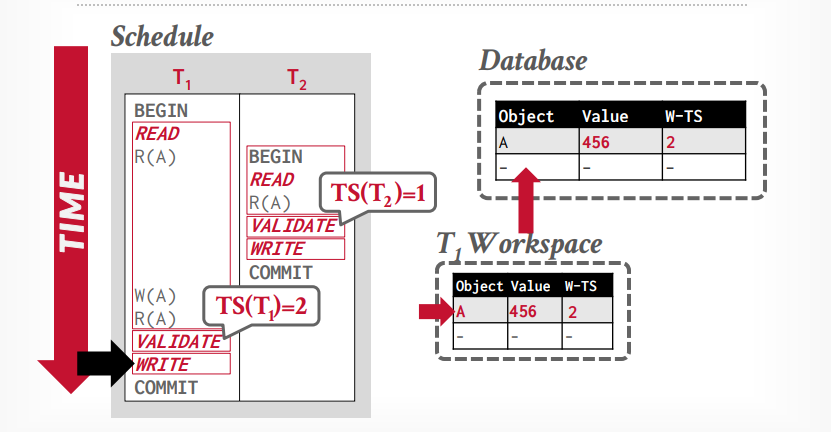
事务t1进入validation阶段,分配时间戳为2,因为1已经分配给t2事务了,写入阶段将私有工作区的tuple A,更新到全局工作区
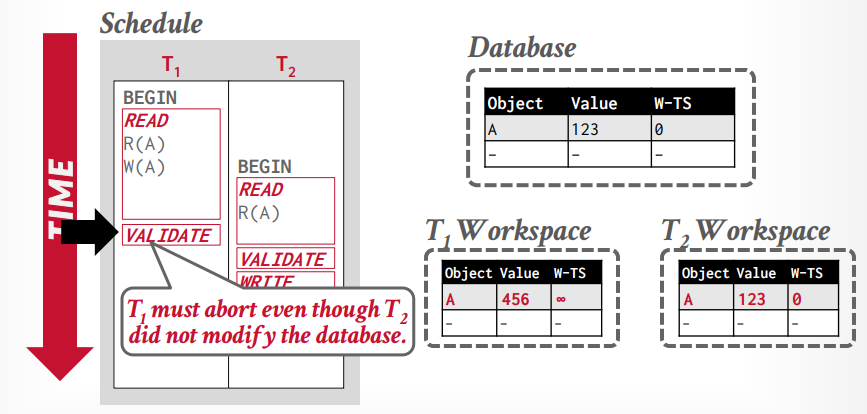
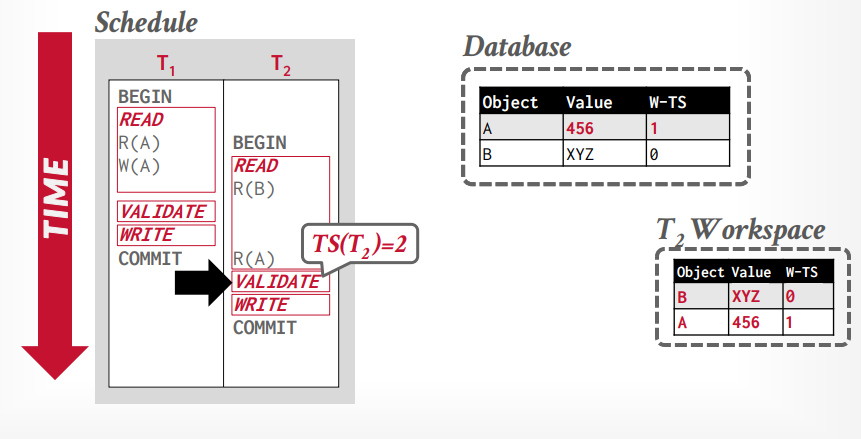
数据库拥有全局视野,在validation phase阶段,是单线程比较事务是否可以执行,会有一个大的latch上锁
backward validation: 和并发执行中更早已经提交的事务进行比较
forward validation: 和并发执行中后面没有提交的事务进行比较
forward validation 如果事务t1 < t2,t1的写阶段在t2的读阶段之前,则没有任何冲突发生。
如果事务t1 < t2,但是t1的valition阶段在t2的validation阶段之前,则冲突,因为t1已经更改了tuple A ,而t2读取的是W-TS=0的tuple A,如果t1事务的W-TS是1,t2是2,那么t2读取的应该是W-TS=1的tuple A才对
如果t2的validation阶段在前就没问题,因为t2分配W-TS=1,t1是2
如果事务t1 < t2 ,t1的validation阶段在t2的前面,但是t1已经写入全局工作区以后,t2在读取这个tuple,就没有问题
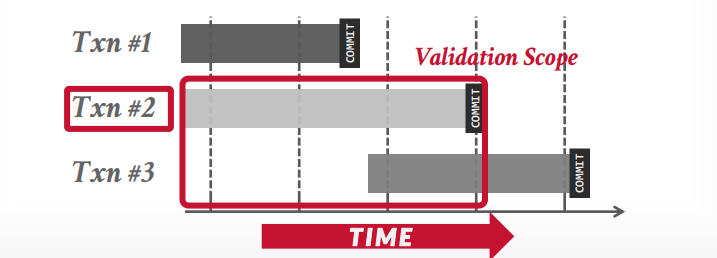
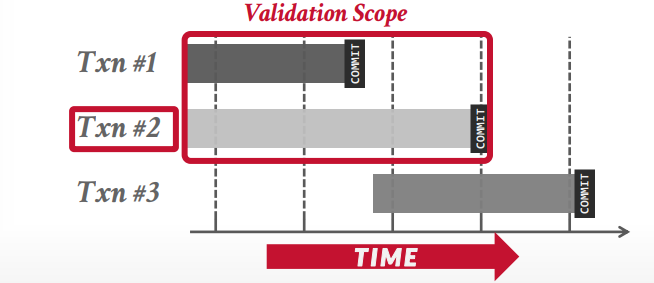
forward validation和没有提交的事务进行比较
backward 和已经提交的事务比较
partition based 时间戳协议 按照时间戳水平分区,在同一个区里面,按照时间戳顺序执行,就不需要latch了。速度会很快。
在不同区执行的话,就很复杂了。
每个分区都是单线程执行的。这样不需要获取latch。
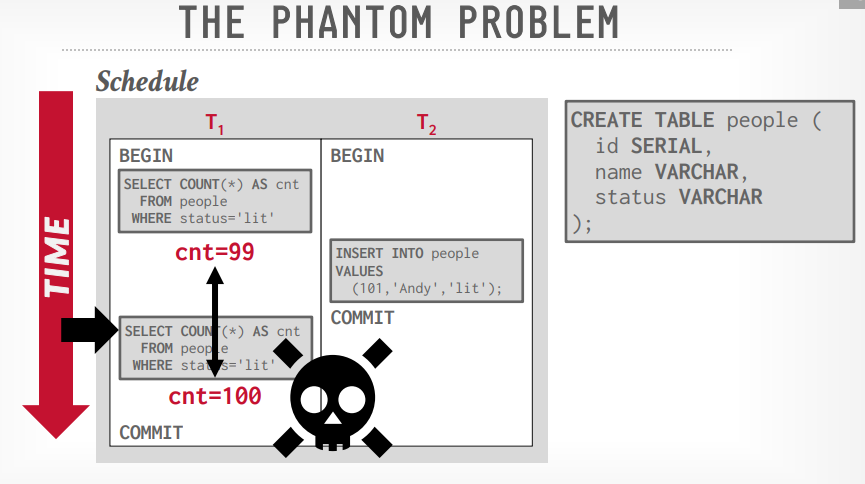
幻读问题 假设事务t1读取了table a的count()是99,事务t2插入了一条数据,事务t1再次读取count( )就变成了100,因为t1只能lock已经存在的数据,要插入的数据没办法lock
解决幻读的三个方法
重新执行扫描:提交后重新执行扫描看结果是否一致,不一致就发生了幻读,少见
predicate locking:System R提出的方案,锁定where语句,进行比较,很难实现,非常少见,duckDB,Hyper等实现了
Index Locking: 索引锁定,常见
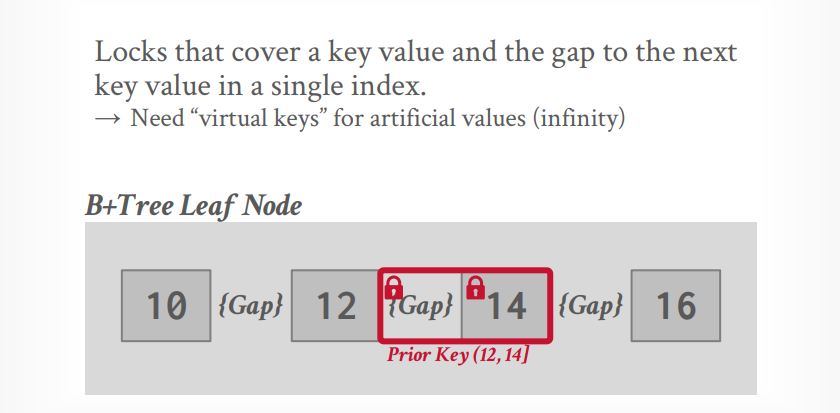
Index Locking
key-value locks
Gap locks (间隙锁)
Key-Range locks
Hierarchical locks
key-value locks只能锁定键值,需要一个virtual key来锁定不存在的key
间隙锁,锁定键值和下一个键值之间的间隙
key-Range locks,锁定键值以及和下一个键值之间的间隙
Hierarchical locks使用IX,IS等意向锁
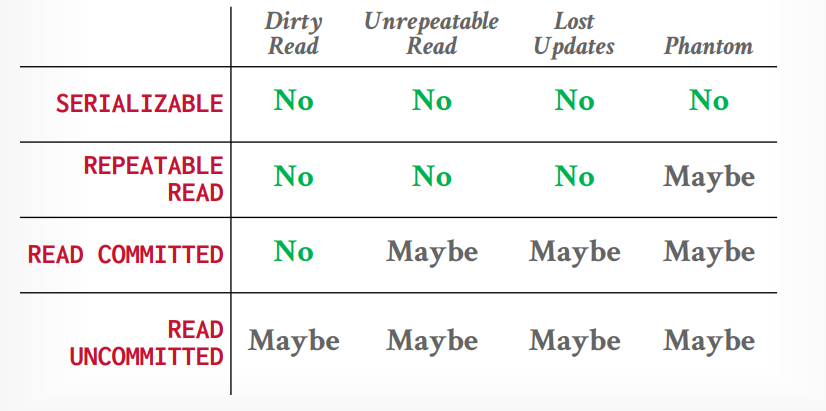
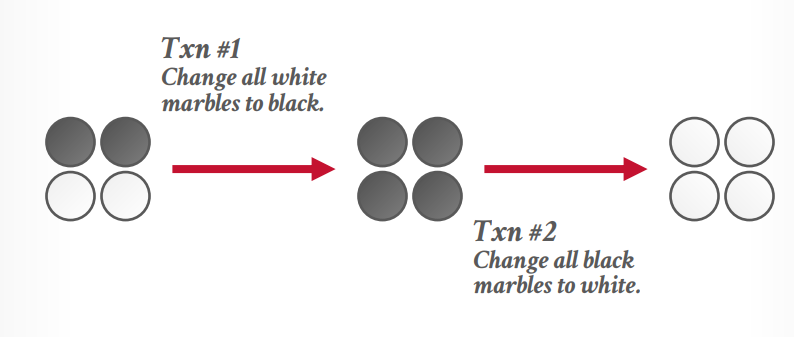
不同隔离级别对应的问题,最受欢迎的隔离级别是读已提交,mysql默认是可重复读
多版本并发控制(MVCC) MVCC(Multiple Version Concurrency Contronl)最早在1978年由一位MIT的Phd学生提出。在1980年被数据库实现。
firefox 最开始叫 phoenix, 但是因为和其他的重名了需要改名字,然后改成了firebird, firebird是个最早开源的数据库,它使用了MVCC,所以火狐还要改名,就成了firefox。
Writers don’t block readers
Readers don’t block wirters
只读事务读取快照,不需要锁。MVCC天然支持快照隔离,如果没有gc,支持time travel query,就是可以查询很久以前的更改
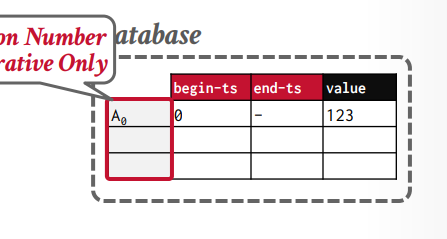
版本维护有3个元数据
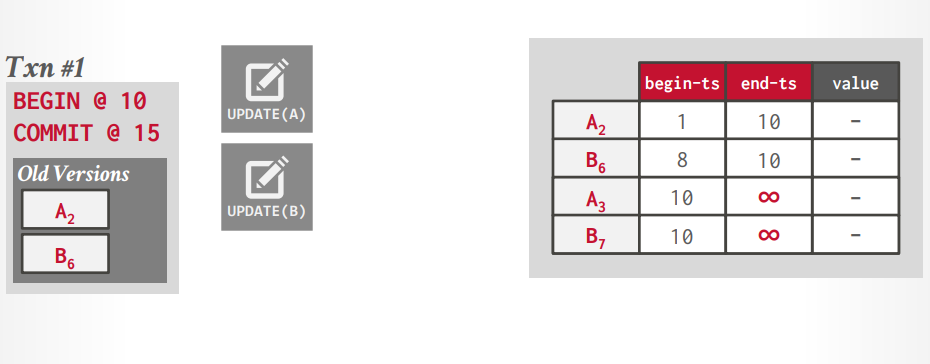
version 版本号 从0开始,递增
begin 开始的时间戳
end 结束的时间戳,默认是无穷大,当写入以后要更新上一个版本的end
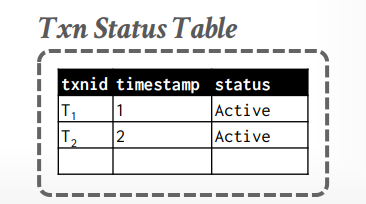
还要维护一个事务状态表
txnid: 比如事务t1,t2标识
timestamp: 时间戳,如OCC那样
status: 活动中,已提交等
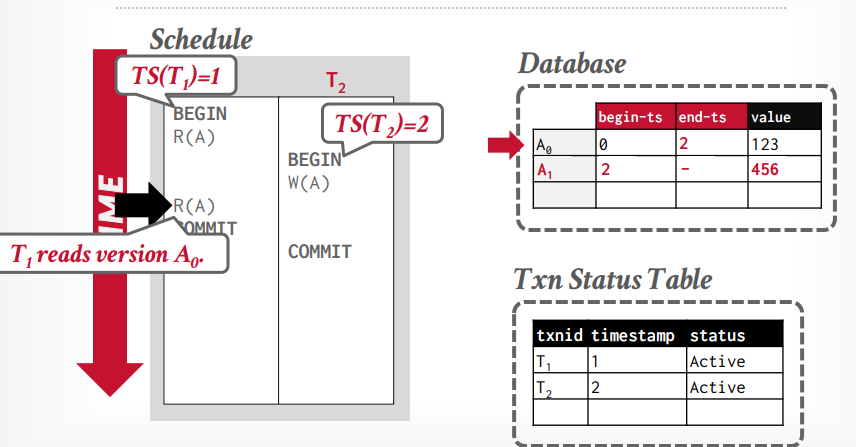
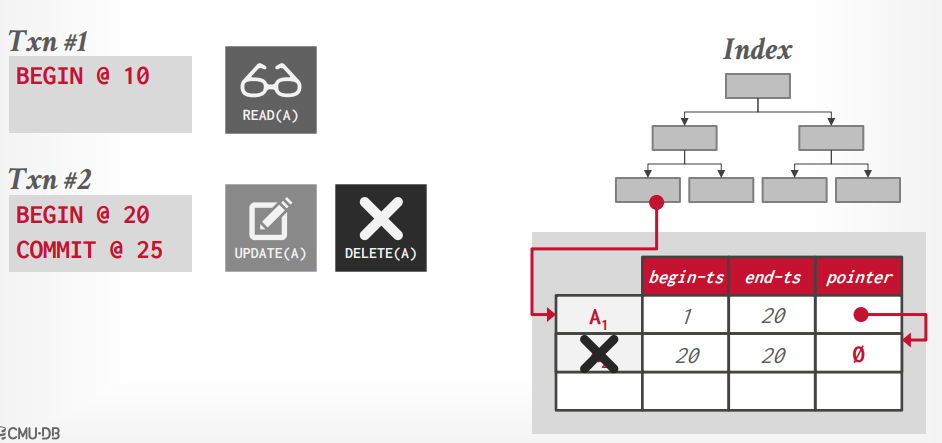
假设事务t1读取A0的数据,然后事务t2写入A1数据,然后更新A0的end-ts=2,事务t1再次读取的时候还能看到A0
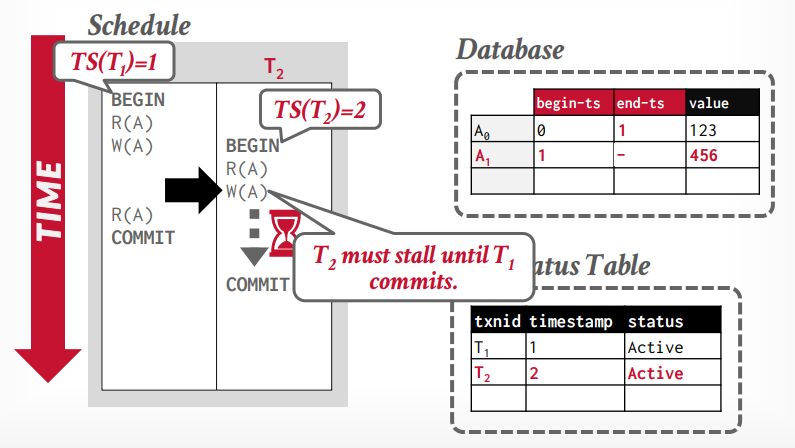
假设事务t1读取A0的数据,然后写入A1的数据,事务t2读取A0的数据,写入A2的数据,这个时候t2会阻塞,因为t1持有A的锁,当t1事务commit后,释放锁,事务t2才能继续写入A2的数据
当事务启动的时候,会看到启动时数据库里的一致的快照
没有来自未提交的事务的撕裂写入
如果两个事务更新同一个tuple,第一个写入将获胜
快照隔离收到写入偏差异常(Write Skew Anomaly)的影响。
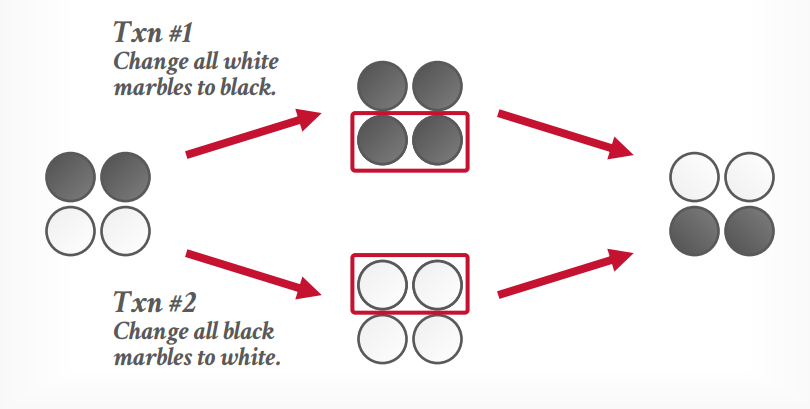
写入偏差异常,假设当前有2个黑球,2个白球,事务t1要将白球更新成黑球,事务t2要将黑球更新成白球,这个时候事务t1读取到2个白球,只将这个两个白球更新成黑球了,而事务t2读取了2个黑球,只把这2个黑球更新成白球了,最终结果还是2黑2白
但是顺序执行的话结果应该是全白或全黑。
并发控制协议
timestamp ordering:分配一个确定顺序的时间戳
OCC:乐观并发控制
两阶段锁
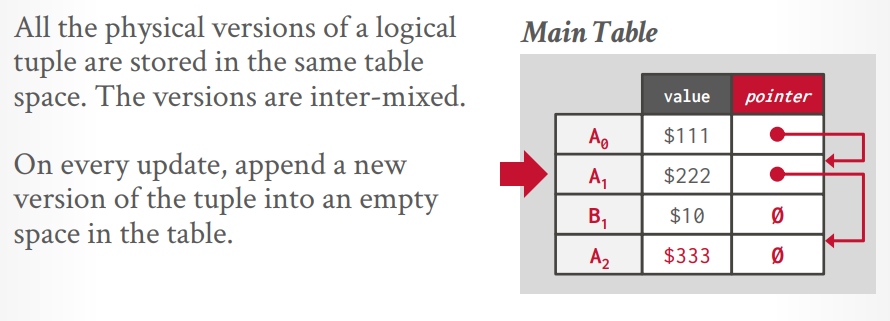
版本存储 版本存储:为每个逻辑tuple创建一个链表,每个事务通过指针遍历链表获取对应的版本。索引指针指向链表的头节点。
append only storage: 复制一个tuple,更新数据,放到后面的节点作为tuple的新版本。
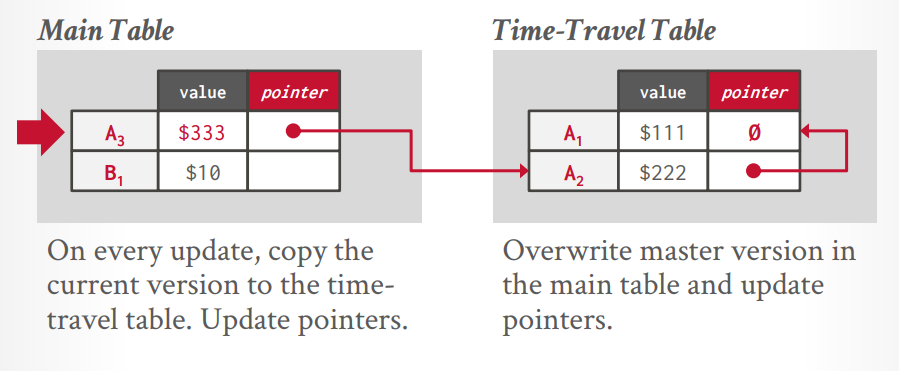
time travel storage: master version表中放最新版本的数据,老版本的数据放在 time travel 表中。master version表维护指向time travel表数据的指针。
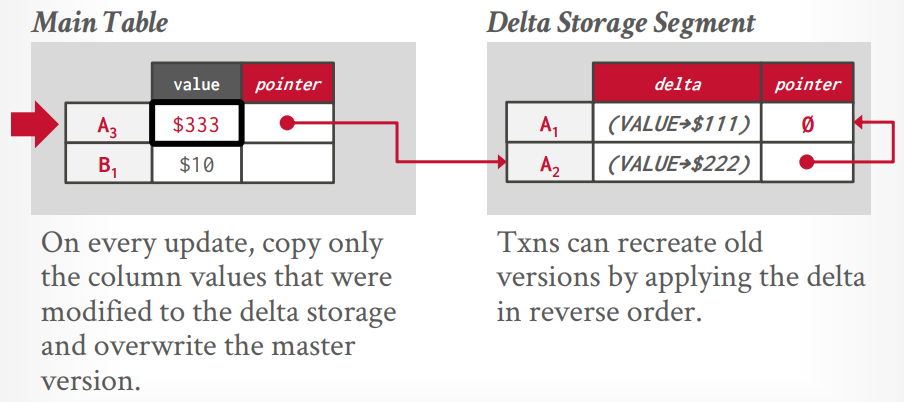
Delta Storage: 最佳方案,只维护对前一个版本数据的修改,不直接维护所有副本。
append only storage 要么最新到最旧的连接,要么最旧到最新的连接,全都放在一个工作空间中,然后用指针连一起
time travel storage 这个是两个空间来存储,一个main table存储最新的,一个time travel table存储所有旧的,像Sql server这种最初没有设计MVCC的数据库,为了兼容使用了这种方法。
Delta storage 也是两个空间存储,不同的是旧空间只存储修改的列的值
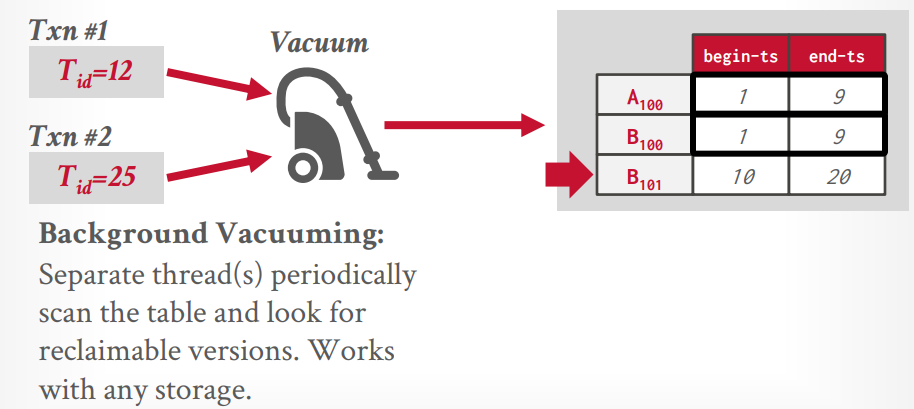
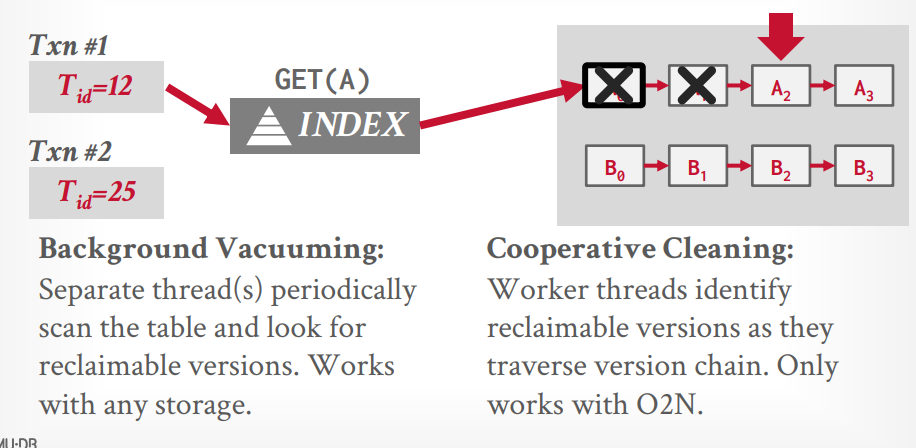
garbage collection garbage collection(垃圾回收)
tuple level:通过比较时间戳来确定哪些版本已经不用了,可以进行回收了。
transaction level:在事务提交的时候进行对比旧版本的数据是否可以删除
tuple level gc vacuum 后台线程的方式运行,每隔一段时间去扫描,还可以通过bit map来提升速度
假设现在正在运行的事务有两个,最低时间戳是12,那么所有end-ts低于12的都可以被gc,数据库基本都用的这个
cooperative cleaning 当查询某个tuple的时候,进行扫描这个tuple的旧版本,从而gc,缺点是如果这个tuple一直不被访问,那么就一直不gc,很罕见
transaction level gc 在事务提交的时候进行对比旧版本的数据是否可以删除
索引管理 索引管理
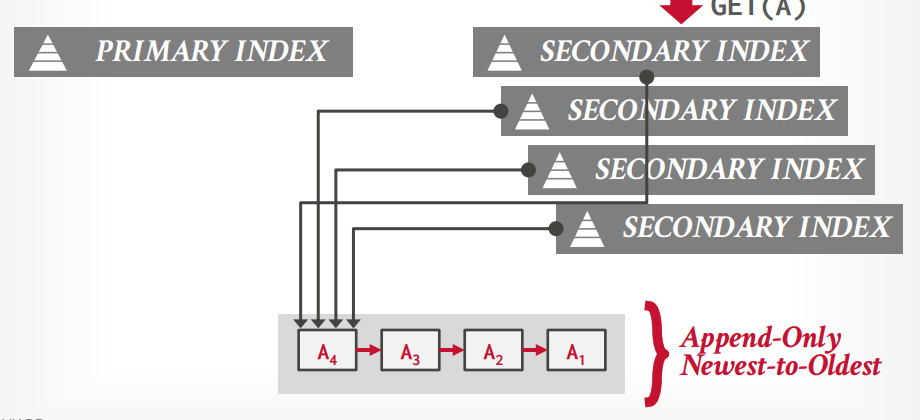
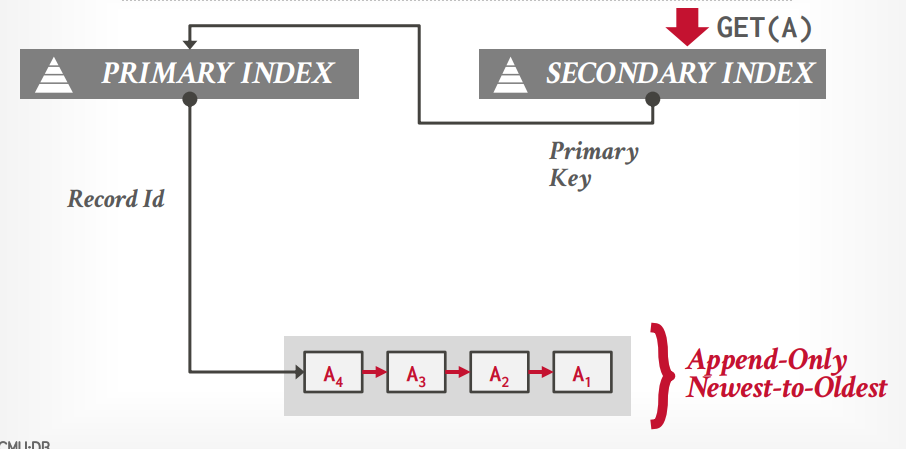
逻辑指针:通过中间表转化指针和物理地址,二级索引指向主键索引。
物理指针:直接记录指针
物理指针 所有的索引都记录指针,缺点是更新的时候所有索引的指针都要更新
逻辑指针 二级索引都记录主键,只有主键索引记录指针,mysql就这样的,这种方式更好
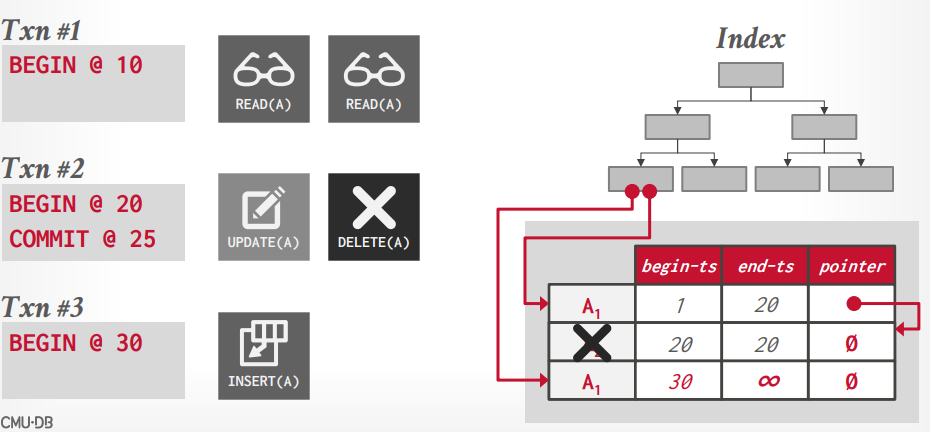
重复key问题 如果索引不是唯一索引,可以有多个key的话,假设事务t1读取A1,没问题
假设事务t2更新了A1,又删除了A1,那么数据如图所示A1老版本指向新版本,但是新版本是被删除的
假设事务t3插入了一条A1数据,那么索引就指向两个A1数据
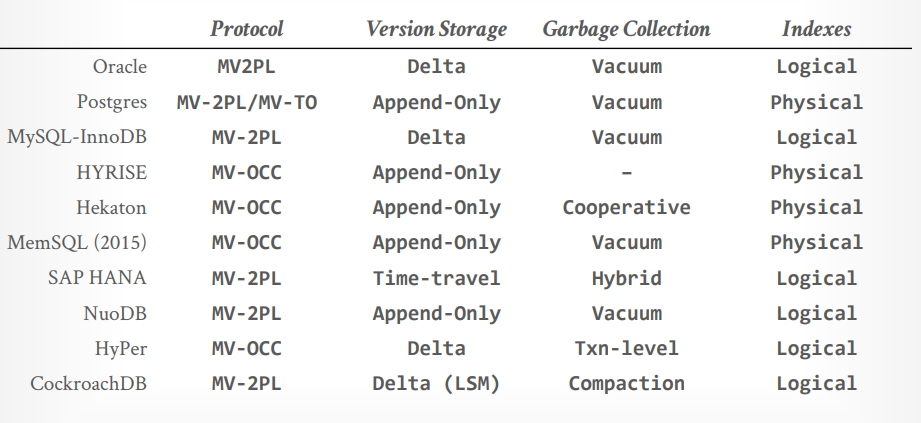
MySQL使用两阶段锁,版本存储使用Delta Storage,垃圾回收是tuple level Vacuum,索引管理是逻辑指针。Mysql更快。
MVCC实现
Logging Schemes 在数据库运行时,还没有把数据写入磁盘的时候发生故障,这个时候需要恢复数据。
故障恢复 主要是两件事
故障类型
UNDO(撤销) and REDO(重做) Undo:维护一些信息,可以恢复事务对数据库中某个对象所做的任何修改。
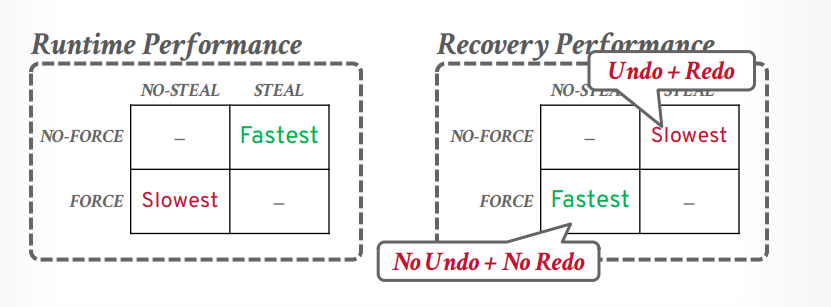
buffer pool 策略 两个策略
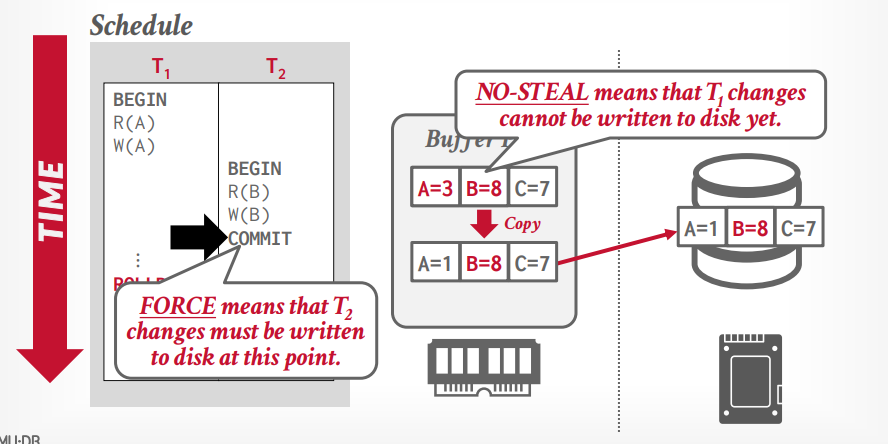
steal:是否允许一个已提交事务写入磁盘的时候把这个page里面的未提交事务的修改也写入磁盘。
force:提交事务的时候,是否允许事务的所有更新写入磁盘
not steal + force
优点:不需要恢复,因为只写入磁盘提交的事务更新的内容。磁盘就是已提交内容
缺点:多个事务提交需要写入多次磁盘,写入磁盘麻烦点,因为要复制一个副本出来,副本中是这个事务修改的内容,把这个副本写入磁盘。
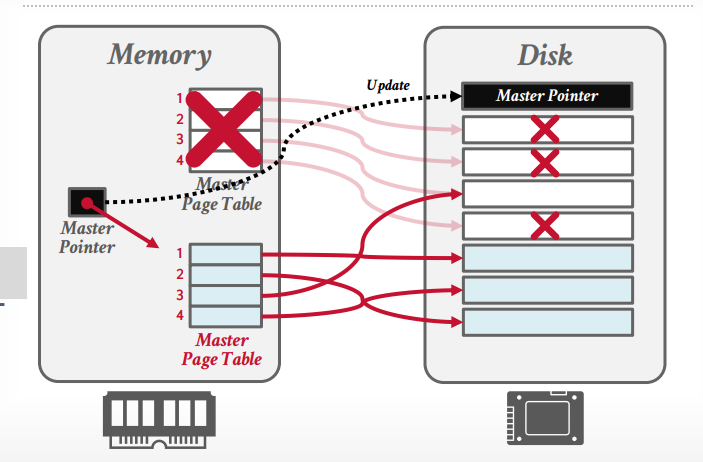
shadow paging:
有一个db root,记录当前使用的hash table
hash table有一个master table是当前使用的,每个事务会有一个shadow page table,提交以后更新db root指向这个shadow page table,然后回收之前的master table和对应的page文件
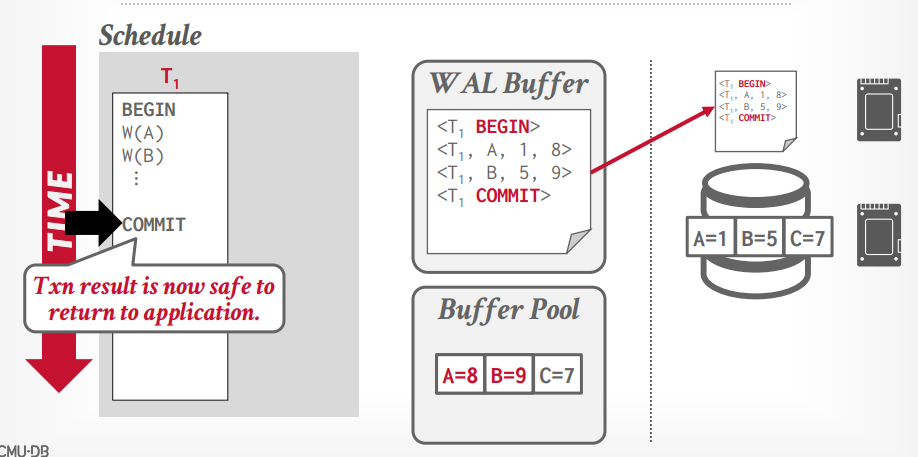
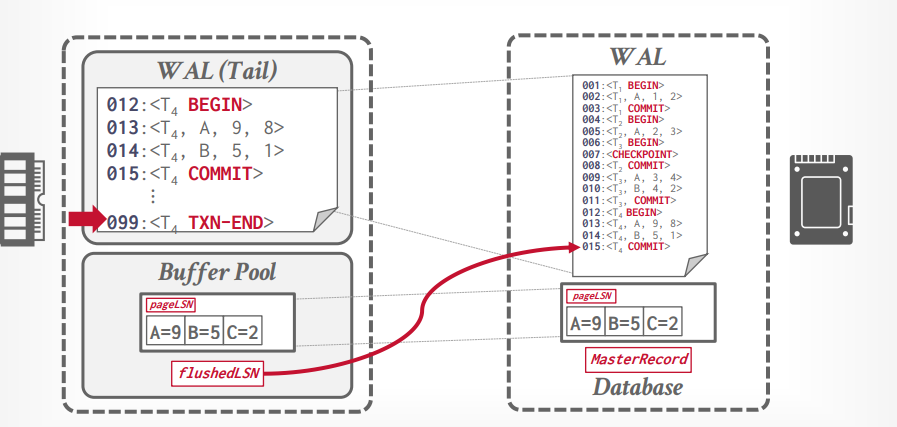
wirte ahead log
先写入日志,在写入磁盘
日志中包含的信息可以用来undo and redo。
使用的策略是 steal + not force,所以不需要把事务的所有更新都写入磁盘。
日志内容
事务id
对象id
时间戳
before value(undo)
after value(redo)
写入更快,但是恢复速度慢
当事务执行的时候,写入日志到内存中,比如事务t1,将A从1修改到8,当事务提交的时候,先把日志写入磁盘,然后告诉客户端事务成功,如果这个时候发生断电等,可以读取日志来恢复事务,如果写入日志之前断电,那么无需恢复,因为没有告诉客户端成功,事务没有成功如何办是客户端要考虑的。
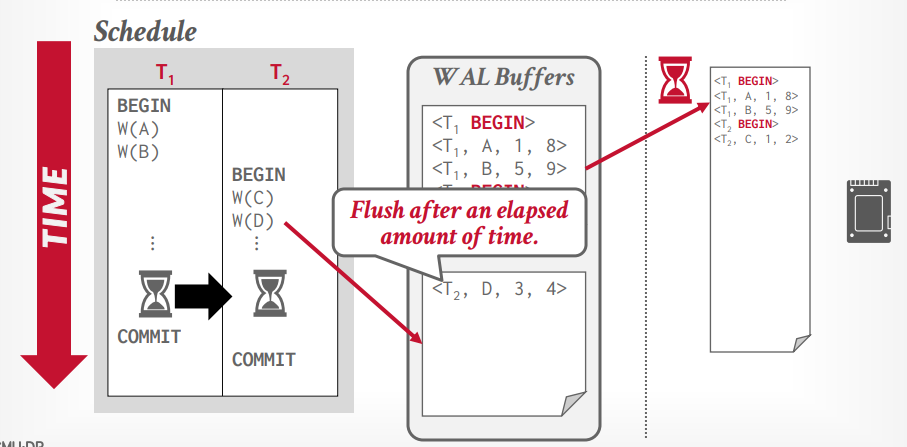
group commit
有两个log buffer,写满一个以后,写另一个,将满的log buffer写入磁盘
除了满的时候写入磁盘,还有定时,如果知道写入磁盘的时间,可以定时成这个时间,没满的话时间到了也会写入磁盘。
满了的写入磁盘可以异步写入,增加速度
shadow paging 和 WAL 就是一种权衡,是看重运行时速度还是恢复速度,几乎所有的数据库都是用WAL,比如mysql的bin log, WAL运行时速度更快
logging schemes
物理日志:记录底层字节的修改,就像git diff一样能看见,但是修改1万条tuple,就会记录1万条tuple的修改。
逻辑日志:记录高层的事务操作,像update,delete,insert等。比物理日志省空间,但是恢复的时候不知道哪些tuple已经写入了磁盘,所以恢复的时候还会在写入一遍。
混合日志:记录相对底层的修改,但是不像git diff一样那么详细。
check point WAL的缺点是无限增长,如果崩溃后,则需要重现所有的WAL,增加检查点以后,可以只重现检查点以后的日志。
日志中写入check point,check point之前的都是已经写入磁盘的,所以恢复的时候就不用管了。
假设事务t1在检查点前commit了,则不需要恢复,因为已经提交了,事务t2在检查点后commit,在检查点前开始,则需要redo恢复事务t2,事务t3在检查点前开始,但是还没有commit,所以不需要恢复,直接撤销即可。
aries recovery 三步
预写式日志
Repeating history during redo: 重启并恢复事务到之前的状态
logging changes during undo:再次写入预写式日志
日志序列号(LSN)
每个日志都要有一个序列号,在一个事务中,可能不是连续的,但是递增的。
flushedLSN:在内存中,记录上一个刷到磁盘中的log的LSN
pageLSN: 在page中,记录page最新的序列号
recLSN: 在page中,记录最老的序列号,这个是不会变的,而pageLSN一直在更新。
lastLSN: 记录事务中最新的一个日志
Master Record: check point最新的LSN
如果pageLSN <= flushedLSN, 表明这个page的数据都已经写入磁盘了
事务提交的时候,往日志里面写入一个txn end。
当事务commit后写入磁盘,然后更新flushedLSN,接下来添加txn end标识
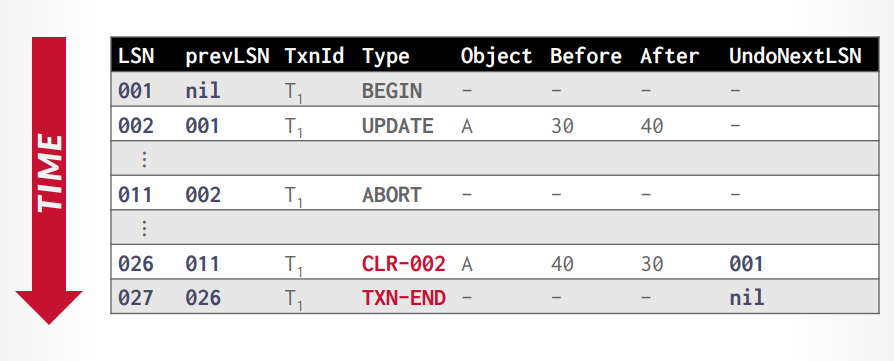
CLR:abort算法
当事务abort的时候,进行撤销操作,日志里面添加CLR记录,before是对应的之前事务日志的after,CLR的after对应之前的before,undo next指针指向下个需要撤销的日志。
撤销完成以后添加 txn end。
写入的时候如同链表一样,除了记录本次的LSN以外,还要记录上一个的LSN,比如本次001,上次是Nil,本次002,上次001,以此找出这一次事务的所有日志,比如事务t1是001-nil,002-001,接下来事务t2是003-nil,004-003,然后事务t1是005-002。
接下来插入CLR日志,CLR可以是026-011,CLR-002代表要撤销的是LSN=002的日志,记录了从40恢复到30,最后在插入txn-end标识
check point写入
第一种方式是停止创建新事务,等所有事务完成的时候开始写入
优点是能完全保证数据一致性
缺点是耗时,执行的时候不能创建新事务
第二种方法暂停更新的事务,只读事务不受影响,需要维护一个active transation table和一个dirty page table
active transation table包含事务id,lastLSN和状态,状态有运行中,提交中,等待undo
dirty page table 包含所有的dirty page信息
第三种方法最好,叫fuzzy checkpoint,checkpoint的时候允许所有事务运行。
开始的时候记录checkpoint begin
结束的时候记录checkpoint end,end里面包含了 checkpoint期间的active transation table和dirty page table信息。
ATT(Active Transation Table)
DPT(Dirty Page Table)
第一个check point记录了ATT是T2事务,代表事务t2在check point之前开始,且未提交,而事务t1在check point之前已经提交了,所以不记录,DPT记录了事务t2在check point之前修改的脏页是P22
第二个check point记录了事务T2,T3,因为T2虽然在第二个check point之前提交了,但是没有插入txn-end代表没有提交结束,DPT记录了两个check point之间的脏页P11和P33
fuzzy check point
因为所有事务都在运行中,所以增加了check point begin 和 end来标识check point的开始和结束,第一个check point end里面记录了事务t2和脏页P22,是因为这些发生在check point begin之前。
arise recovery
分析:根据master record跳到对应的check point的位置,然后开始扫描需要恢复的信息。
redo: 重新执行所有的操作。
undo: 从日志最后开始往上,撤销所有未提交的更改。这个时候已提交的已经写入磁盘,未提交的已经被撤销。
分析阶段:从master record的位置开始扫描到最后,找出这之间的所有active transation table和dirty page table信息。
redo: 根据分析出的信息,找到dirty page中最早的一个recLSN, 也就是最早的一个日志,然后从这里开始恢复数据,执行一遍所有的操作。来恢复buffer pool。
undo: 从最后开始往上面扫描,把需要撤销的数据进行撤销。
分布式数据库介绍 并行数据库
系统架构
shared everthing
shared memory:常见于高性能计算领域,有多个CPU,共享内存和磁盘
shared disk: 内存也有多个,共享磁盘,这个更常见,例如云数据库
更新数据的时候需要通知其余的节点
spark,HBase
shared noting: 磁盘也是多个
有更好的效率,但是很难保证数据一致性和扩容
mongo,ES,Etcd,Zookeeper,ClickHouse
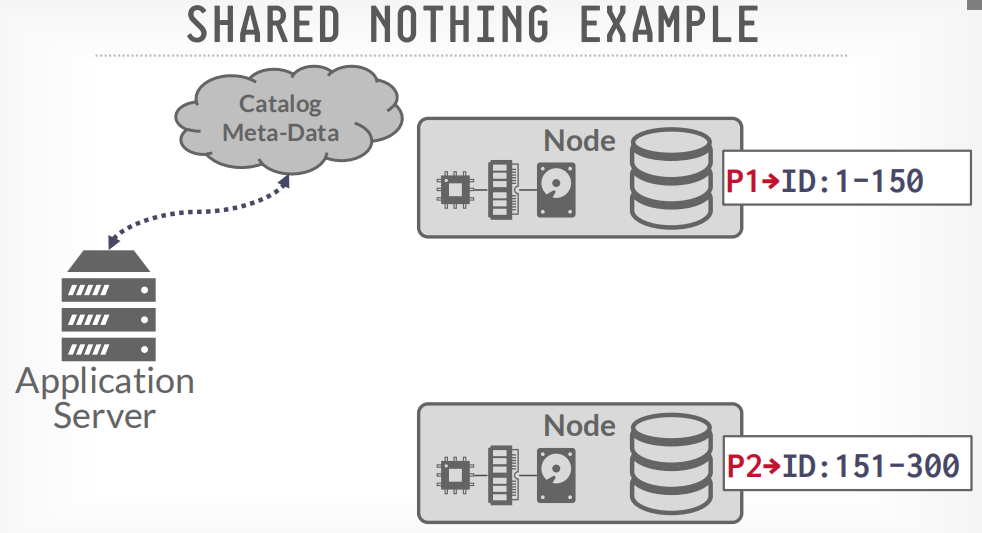
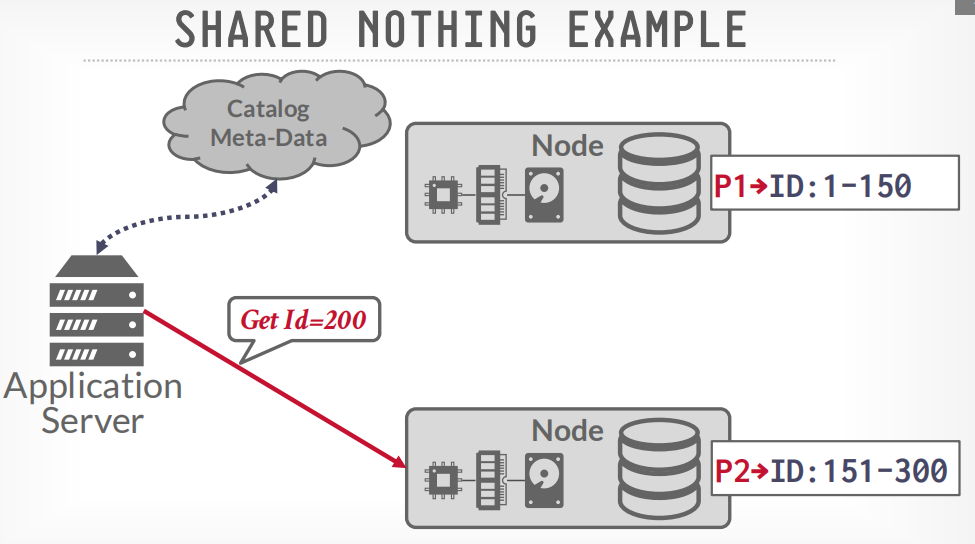
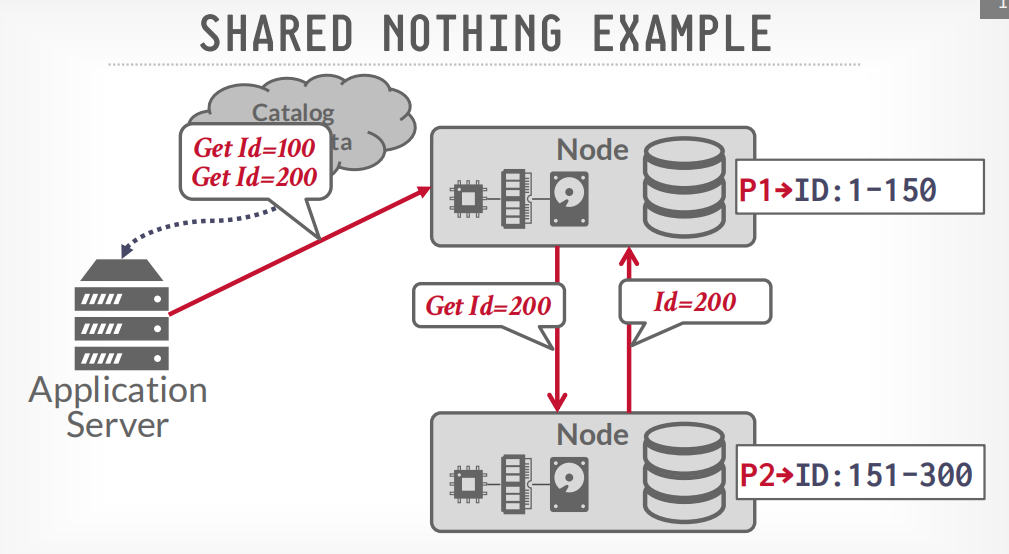
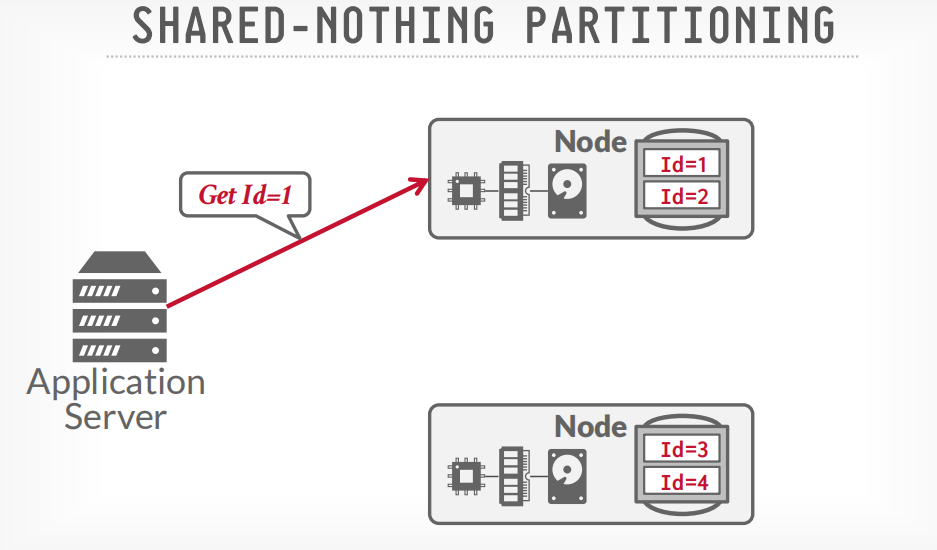
shared noting example
首先通过catalog查询应该请求哪个节点
然后发送查询请求到相应的节点
如果数据跨节点存储,那么数据会节点间通信,比如获取100和200的数据,node p1会请求p2获取200的数据,然后p1将两个数据返回给客户端
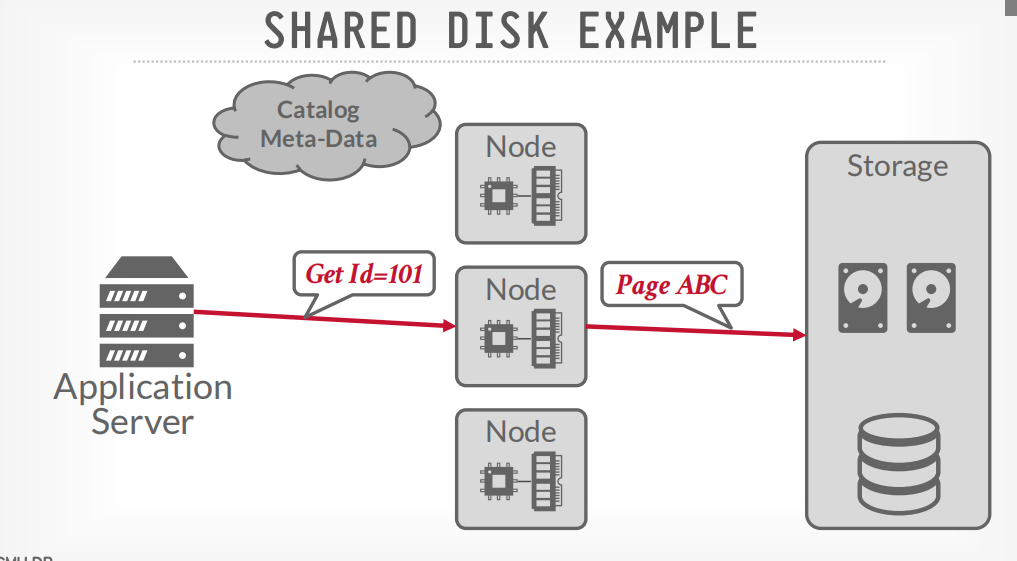
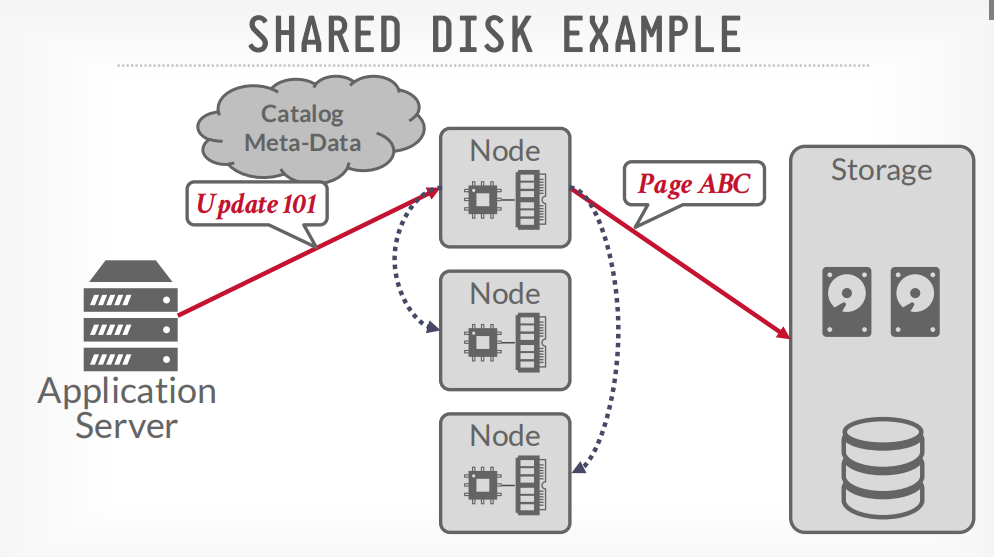
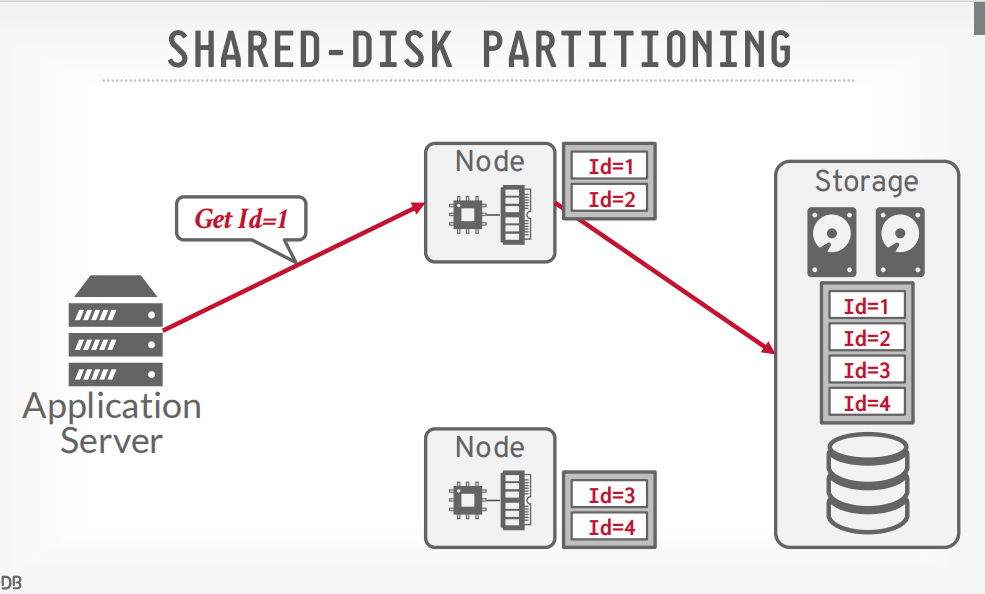
shared disk example
客户端请求节点获取数据,节点请求disk获取数据,然后返回
但是更新的时候需要广播给其他节点
mongo属于shared noting
route节点,负责把请求路由到对应的节点上
config节点,route从这里获取请求应该到哪个节点上
db节点
数据拆分
将不同的数据放到每个shared上面
不同的查询交给不同的shared去做,可以通过exchange operate来并行执行。
最简单的方式是一个表一个分区,mongodb可以这样。
水平分区
将数据水平分到每个分区中
可以是hash,也可以是一个范围一个范围的分区
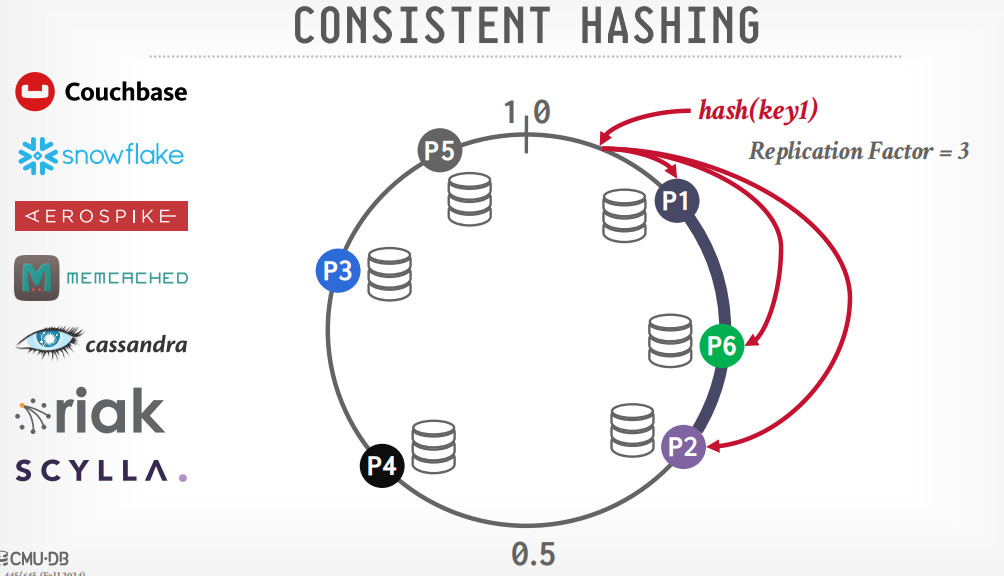
hash的话,想增加分区很麻烦,可以使用一致性hash来解决增加分区的问题,而不是取余。
采用一致性hash的有snowflake,memcached,cassandra等
SHARED-DISK PARTITIONING
SHARED-NOTHING PARTITIONING
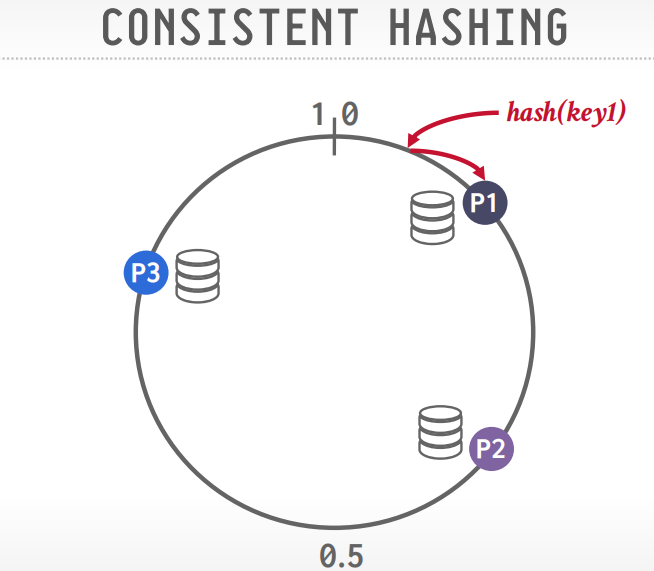
一致性hash
节点分布在环上,数据也分布在环上,顺时针旋转,数据就属于第一个到达的节点。
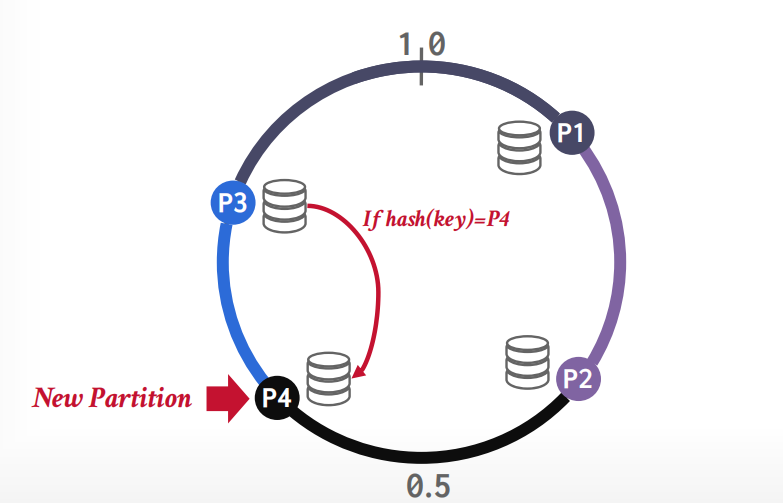
增加节点的时候,只需要重新hash其中一个节点的数据就可以,比如增加p4,因为P4节点落在p3节点的范围里面,所以只需要重新hash节点p3的数据,其他节点无影响。
如果需要复制数据,将数据存储在多个节点上,假设replication=3,复制数据到三个节点,则顺时针旋转的3个节点都存储该数据。
分布式事务
通过中心化服务器,来分发lock,然后提交事务的时候通过他来请求每一个分区是否能提交事务,如果都可以,才提交事务
去中心化事务提交
spanner
HNSW
分布式OLTP数据库 假设所有节点是友好的
replication:可以提高可用性
分区 vs 非分区
shared noting vs shared disk
设计
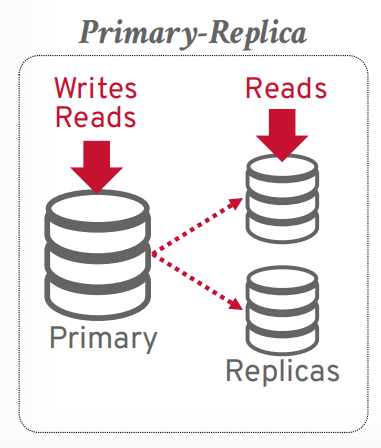
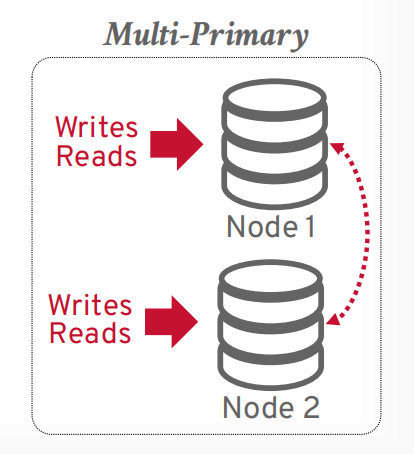
副本配置
primary: 有一个主节点,其他是从节点,大部分都是这样的,主节点负责同步给其他从节点。比如主从复制,读写分离这种
multi-primary: 事务可以在任何一个节点提交,并同步给其他节点,mysql group replication就支持这个。这种方案所有副本都可以读写,冲突的时候通过两阶段提交或者Paxos来觉得写入哪个。Facebook使用了这个。
primary,写入主节点,读取可以在从节点
multi-primary 任何节点都可以读写
K-safety: 通过监控对象来看有哪些replica是活跃的。至少要有k个replica,如果小于k个,就认为宕机了。
传播方案
同步:强一致性,所有从节点都同步以后才返回成功
异步:最终一致性,先返回成功,在同步给其他的从节点
半同步:同步给一些节点后返回成功给客户端
传播时序
即时:立即传递给其他节点,同时当事务提交或回滚的时候也传递给其他节点
提交:事务提交的时候才传播给其他节点
事务提交的顺序由数据库状态决定,原子提交协议也是分布式的共识协议
原子提交协议
两阶段提交(1970)
三阶段提交(1983)
Viewstamped Replication (1988)
Paxos(1989)
Raft(2013)
ZAB(2008)
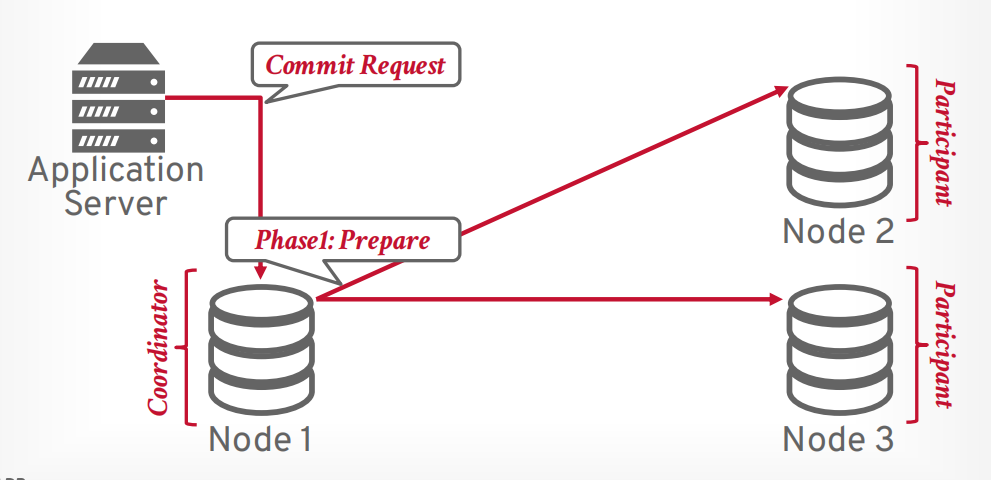
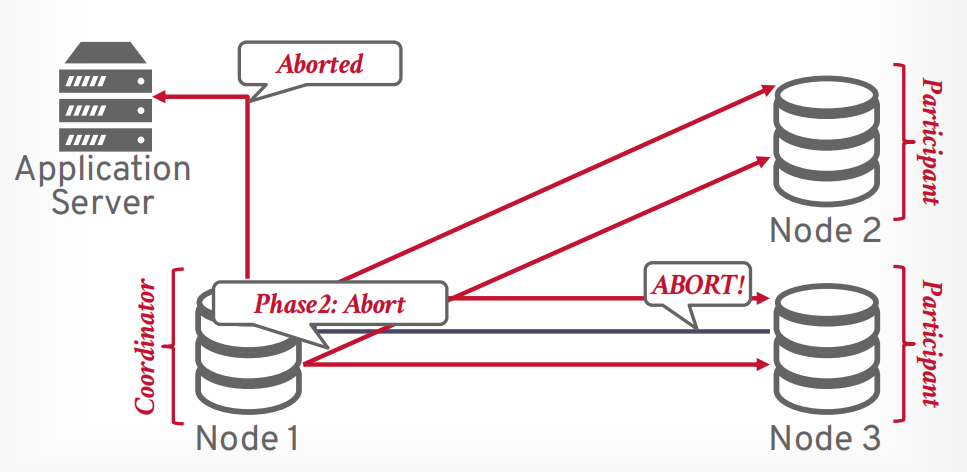
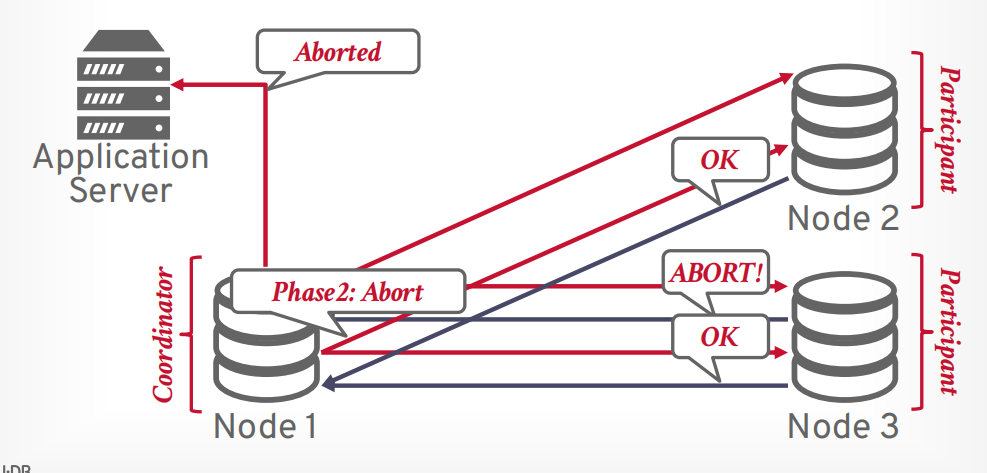
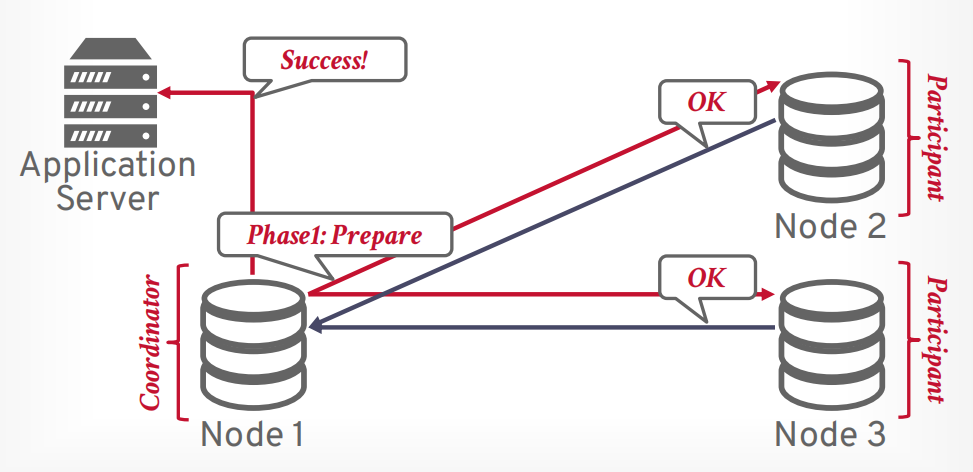
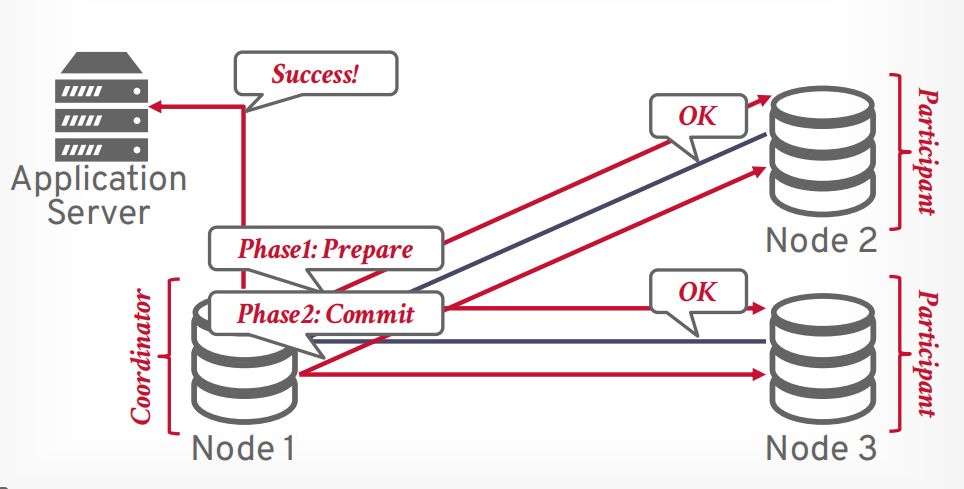
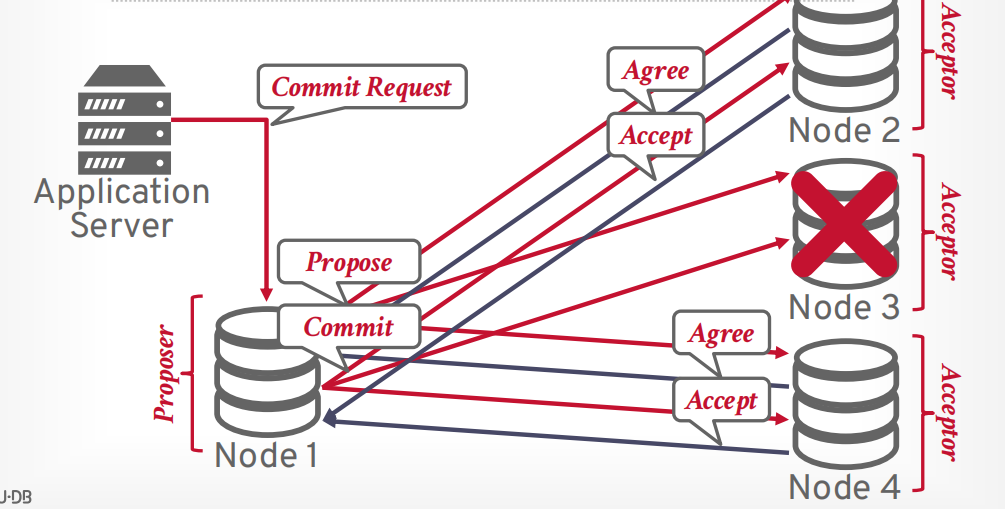
两阶段提交
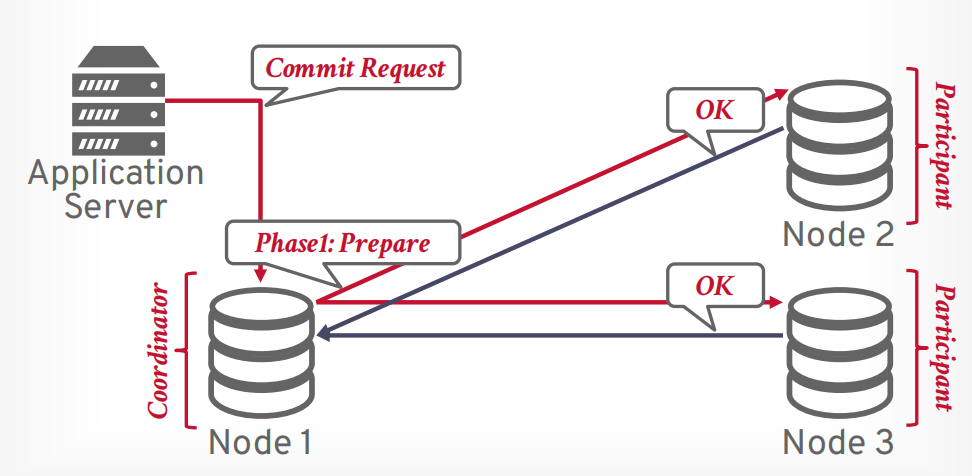
第一阶段 prepare, 像所有参与者发送请求,是否能提交事务,只有所有都可以提交,才进入第二阶段,如果有一个节点abort,那么事务就会进入第二阶段abort
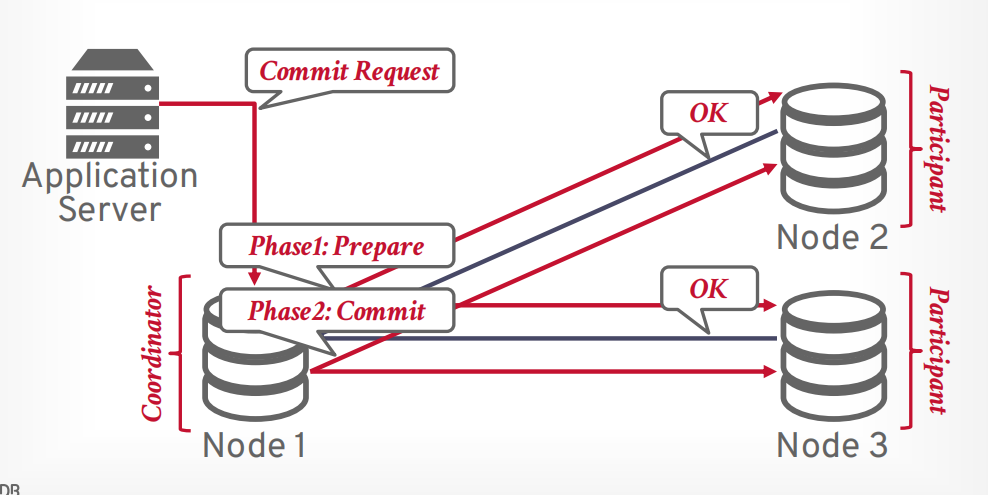
第二阶段 commit, 想所有参与者发送请求,进行提交事务。
第二阶段 abort, 返回abort,然后所有参与者abort。
假设客户端发送提交事务的请求,有一个协调器和若干个参与者,协调器接收请求以后,向参与者发送第一阶段prepare请求。
如果所有参与者返回OK,表示全部同意提交,则可以提交。
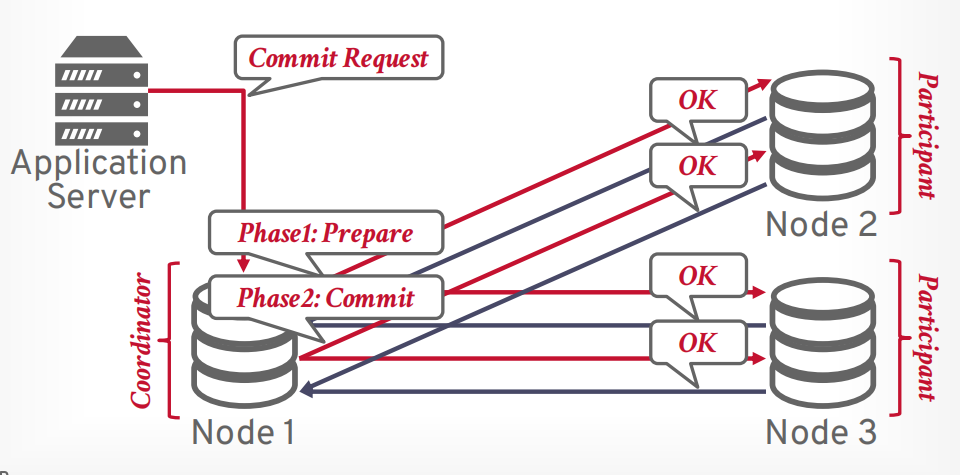
接下来协调器发送第二阶段commit请求给所有参与者
所有参与者返回OK以后,协调器返回提交成功给客户端
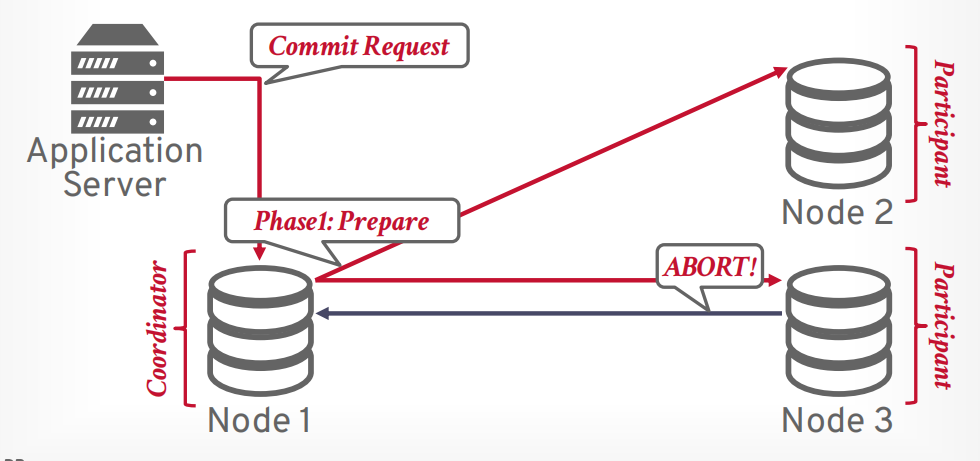
假设有任何一个参与者在第一阶段返回了不同意,则终止事务提交
协调器向所有节点发送第二阶段abort请求
等待所有节点返回OK以后,协调器返回abort给客户端
崩溃恢复
如果协调器崩溃了。要么全部abort,要么选出新的协调器继续执行事务。
如果参与者崩溃了,那么协调器会认为参与者返回了abort,从而终止事务。
优化
early prepare voting: 这个很少,最后一个查询执行的时候,告诉他可以直接进入prepare阶段
early Ack After Prepare: 这个很常见,prepare阶段结束就返回事务执行成功,然后自己再接着commit。
early Ack After Prepare:当第一阶段prepare返回成功以后,立即给客户端返回成功。
返回给客户端以后再发送第二阶段commit请求给其他参与者。
Paxos,来自分布式计算领域,也被称为共识协议。两阶段提交是Paxos的一个子集。
Paxos大部分节点同意提交就可以提交,而两阶段提交需要所有参与者同意,所以Paxos没有容错。
multi-Paxos
选举一个leader来进行提案,每隔一段时间重新选举
防止有两个 proposer 来回提交导致的starving问题
两阶段提交 vs Paxos vs Raft
两阶段提交
如果协调器在发送prepare消息后挂掉,则阻塞直到协调器恢复
Paxos
如果大多数参与者活着则非阻塞,前提是有足够长的时间不再出现故障
Raft
与Paxos类似,但节点类型较少。
只有拥有最新日志的节点才能成为领导者
CAP理论
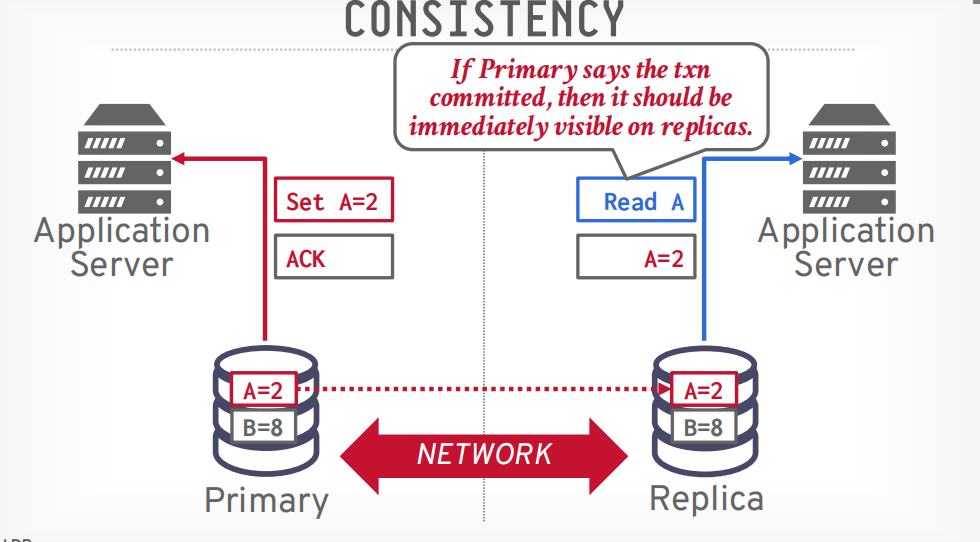
Consistent: 一致性
Always Available: 始终可用
Network Partition Tolerant:分区容错性
Nosql基本都是AP,事务性的基本都是CP
一致性代表从哪个节点获取的数据都是一样的
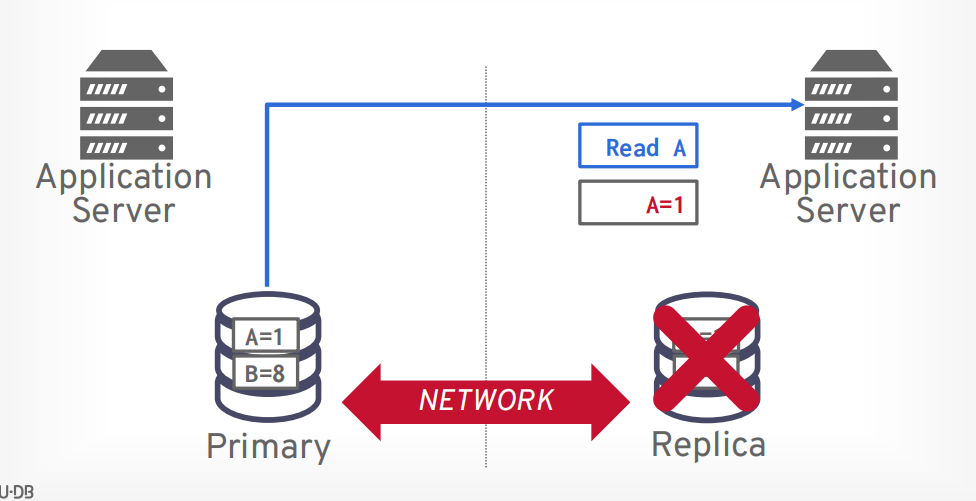
可用性代表当节点挂了以后系统还可以使用
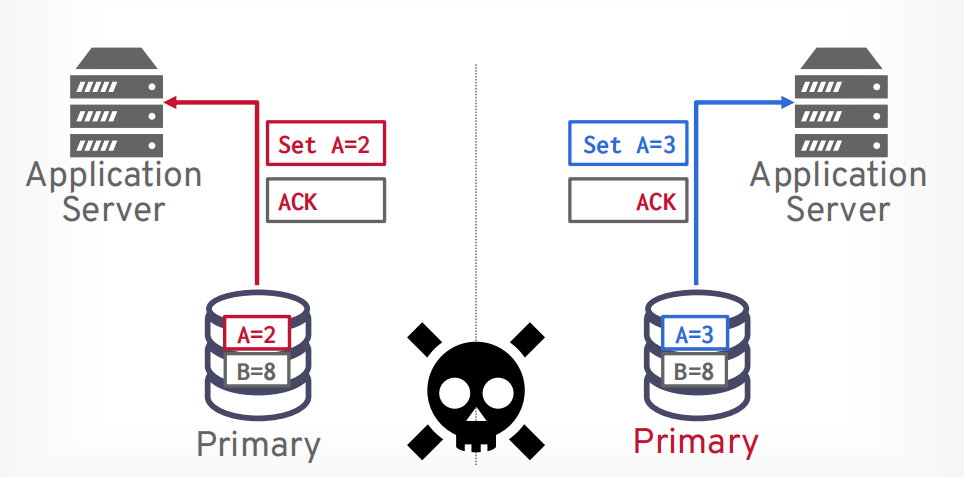
分区容错性最难,容易出现脑裂问题。当网络挂掉以后从节点以为主节点挂了,所以把自己选举为主节点,就产生了两个主节点
当网络恢复以后,两个节点的数据就不一样了。
解决方法1:停止系统
解决方案2:允许拆分,协调更改
允许分区的每一侧都接收更新
根据时间来确定最后的版本,以最后的版本为准
服务端:last update wins 用最后的版本为准
客户端:vector clocks(不要这么做)
2010年提议对CAP进行扩展
Partition Tolerant:分区容忍
Always Available:随时可用
Consistent:一致
Latency:延迟
Consistency: 一致性
分布式OLAP数据库 OLAP数据库也被称作数据仓库,通过ETL,把数据存入数据仓库。
星形模型
雪花模型
一个事实表
更多的dim表,dim表可以有他的dim表
查询执行
push: 发送查询到包含数据的节点,返回数据的时候会做过滤和处理,就像条件下推那样
pull: 知道需要的数据在哪些page里面,把page取过来在执行查询。
push
pull
查询计划
物理操作: 先生成查询计划,然后将对应的需要执行的物理操作直接发送给其余节点,其余节点只负责执行,返回数据。大部分分布式数据库都这样。
sql: 将sql发给每个节点,每个节点生成自己的执行计划。然后执行返回。