stream
stream是java8新增的非常重要的一个特性。并且非常的常用。它实现了函数式编程。具体函数式编程的概念已经很久了,比如js中的箭头函数。java中也通过stream做出了支持。想深入理解的可以参考cmu的课程15-150或者stanford的CS 95SI。
它可以帮助我们方便的处理很多东西。处理分为两种,中间态和结果态。
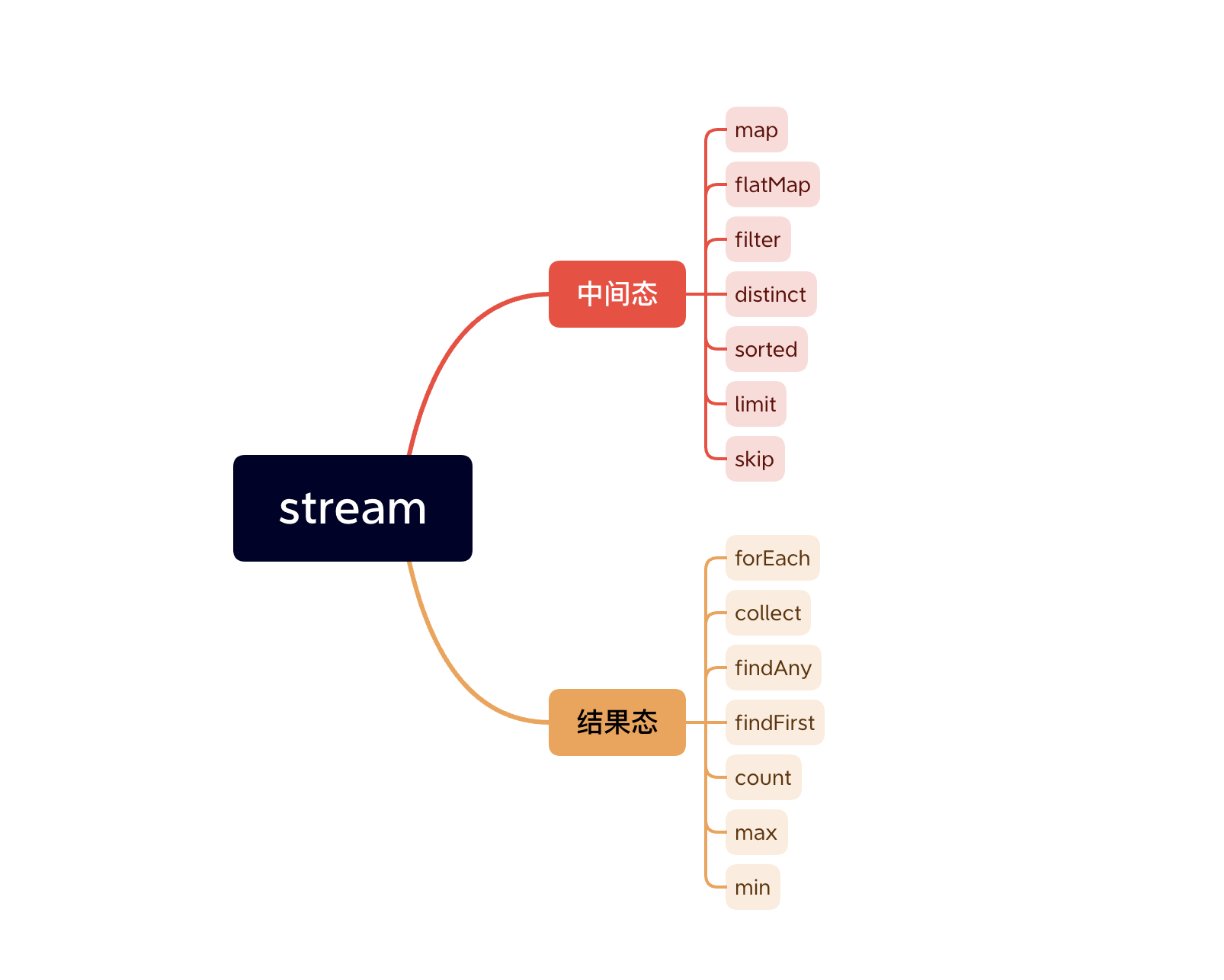
下面是一些中间态操作。他们位于链式操作的中间,当调用他们的时候并没有真正执行。只有当调用结果态的方法的时候才会真正的执行操作,也就是所谓的延迟执行。
| 方法名 | 说明 |
|---|---|
| map | 循环。可以简单理解为foreach |
| flatMap | 将二维数据展开成一维 |
| filter | 过滤数据 |
| distinct | 去重 |
| sorted | 排序 |
| limit | 限制只取n个元素 |
| skip | 跳过n个元素 |
stream的初始化
看一个例子,假设我们有一个需求。输出大于5的所有数。
- 期望输入:2,5,7,1,3,2,8
- 期望输出:7,8
1 | //首先初始化输入列表 |
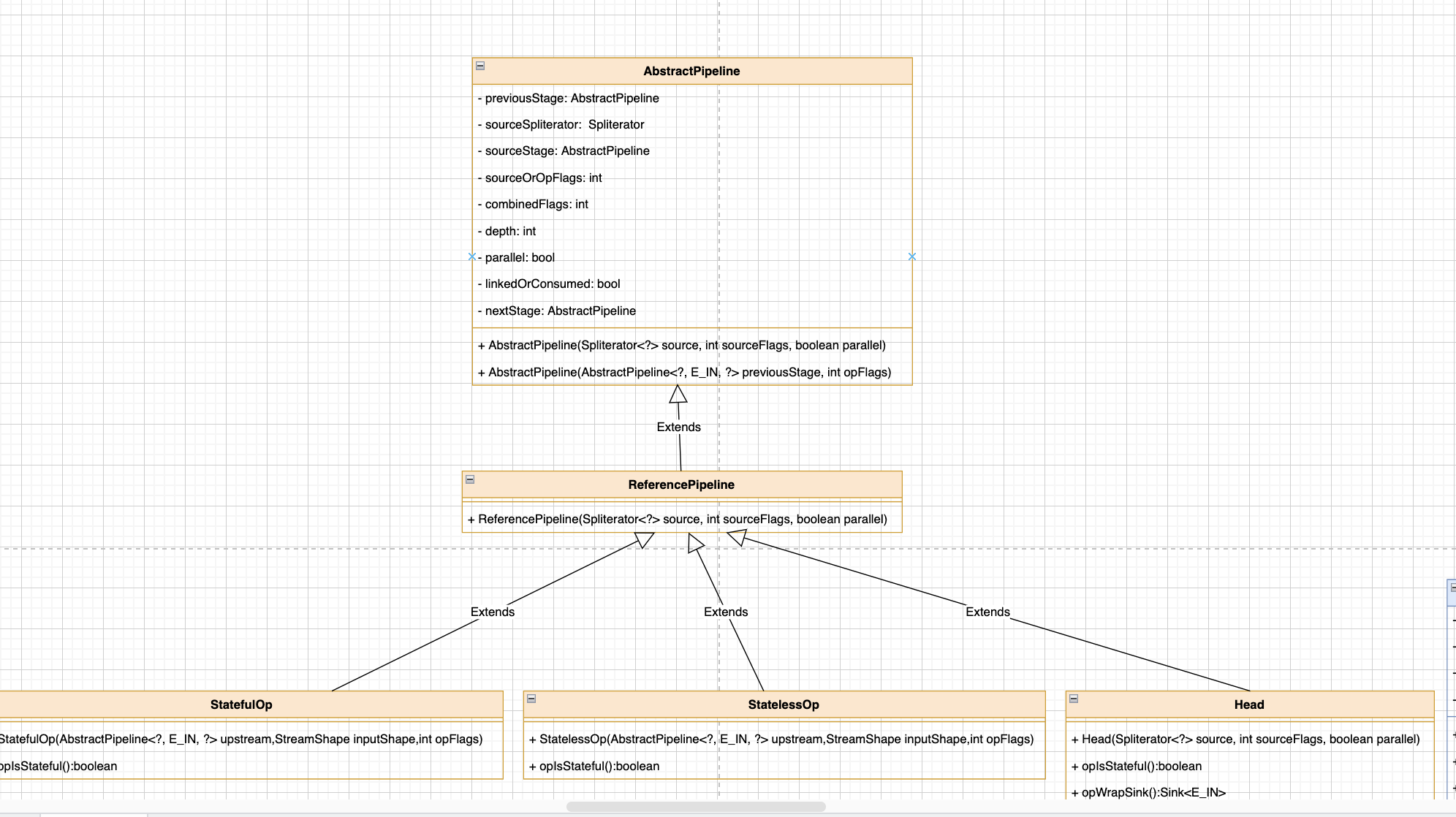
接下来看一下stream是如何执行的。下面是stream的一个类图。可以看到初始化需要使用到一个接口和6个类。主要分为三大类。
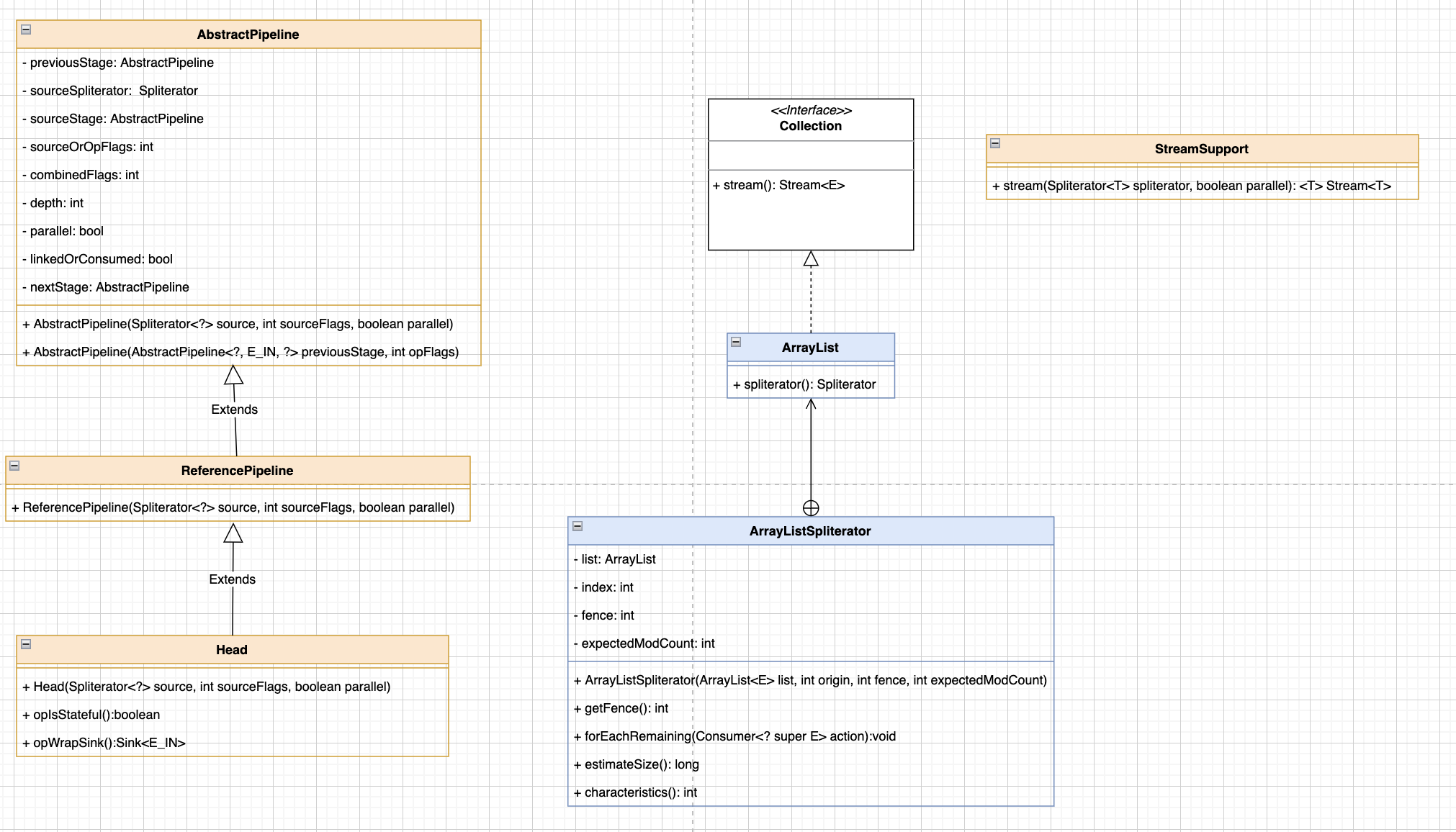
类介绍
第一类是ArrayList类和ArrayListSpliterator类。这两个类是核心类。毕竟我们输入类型是ArrayList,这个就不用说了。
主要在于ArrayListSpliterator这个类,这个类是ArrayList的一个内部类。最主要的操作方法和数据都在里面。看一下几个属性
- list 我们要进行stream操作的list
- fence 大小
- expectedModCount 期望的处理数量
- index
最主要的循环处理方法同样在这个类里面。处理逻辑全部在forEachRemaining这个方法中。
第二大类是StreamSupport流的支持类,算是一个单独的类,提供了对stream的一些操作方法,比如初始化一个stream。
第三大类是AbstractPipeline抽象类为主的3个类,还有两个是继承自AbstractPipeline的ReferencePipeline类,主要负责处理引用类的流。和继承ReferencePipeline的Head类,实现了双向链表的头节点。他们的主要功能就是构造为流的双向链表数据结构。
执行流程介绍
这几个类的执行时序图如下。
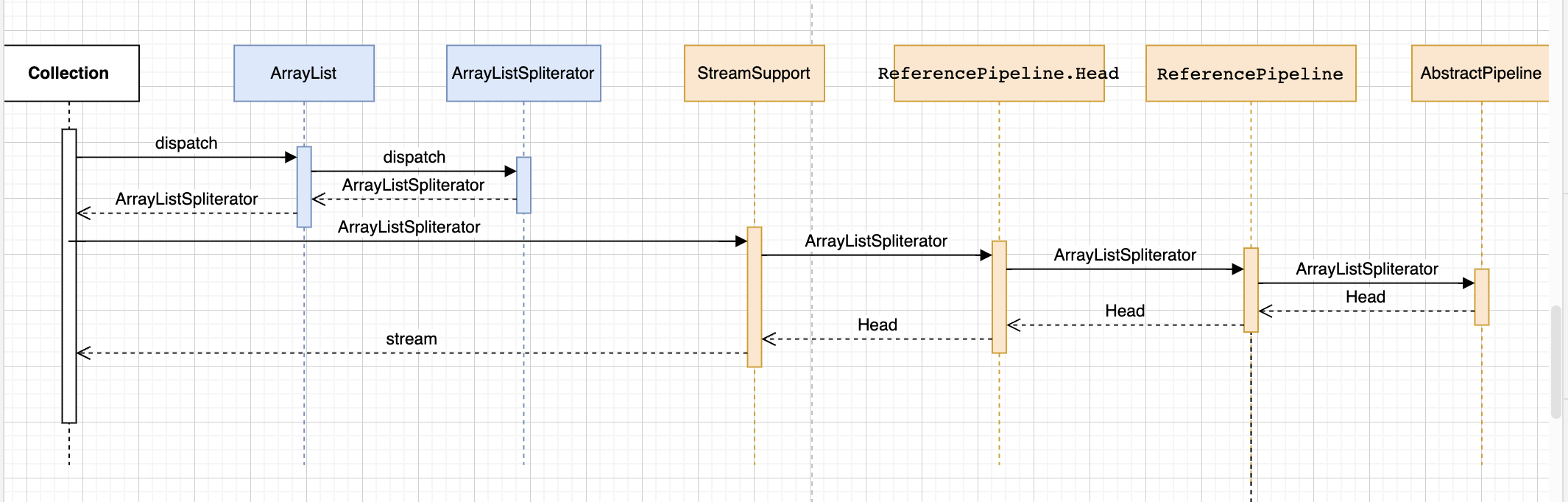
可以清晰的看到,通过Collection类的stream方法调用到了ArrayList的方法然后调用到了ArrayListSpliterator的方法,来初始化了ArrayListSpliterator对象,并存储到流中。
接下来Collection类将初始化好的ArrayListSpliterator对象传递给了StreamSupport类用来初始化stream。
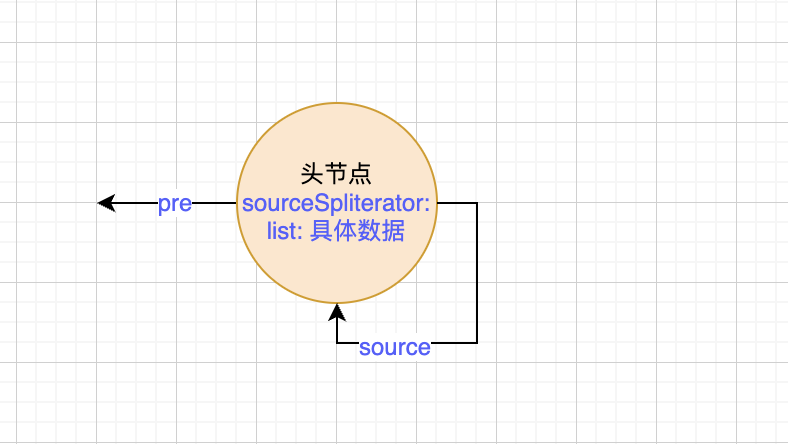
StreamSupport将会创建一个双向链表的头节点。并将ArrayListSpliterator对象放入头节点。初始化以后的流如下图所示:
流介绍
流分为两种,顺序流和并行流。
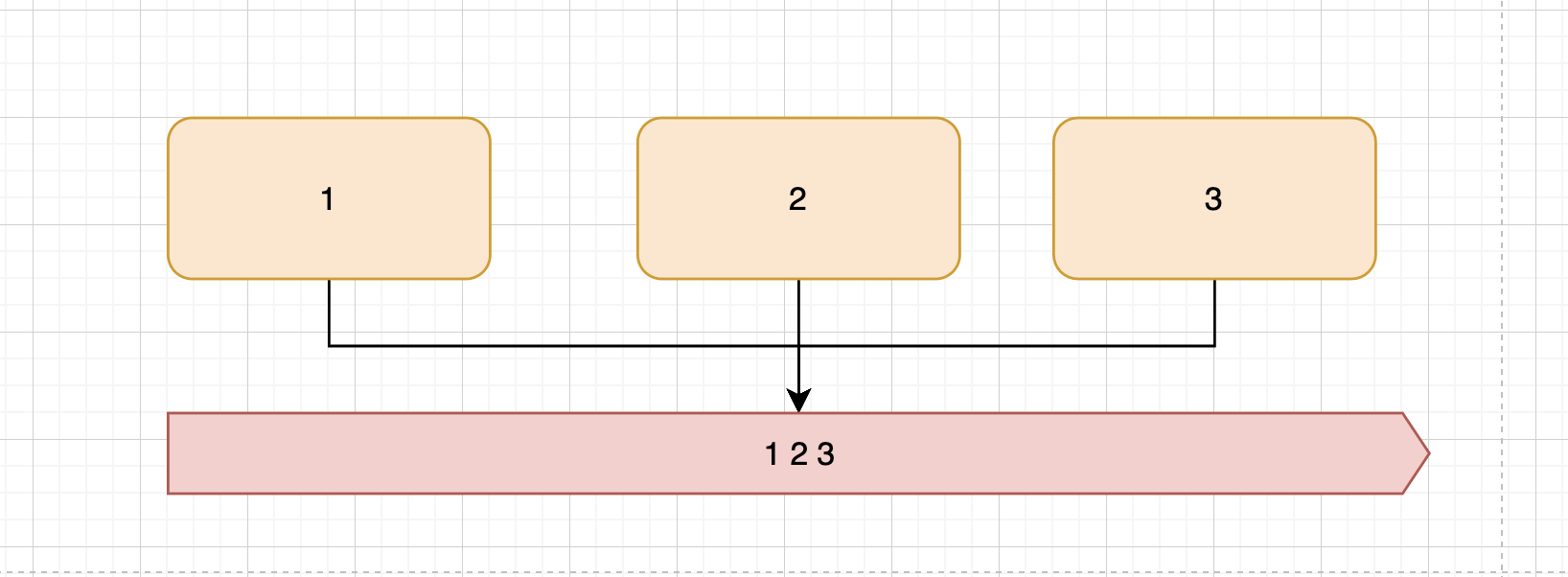
顺序流
顺序流顾名思义就是按照顺序执行。可以直接的类比为for循环。如下图,如果1,2,3三个元素,进入流以后,依然是1,2,3三个元素。
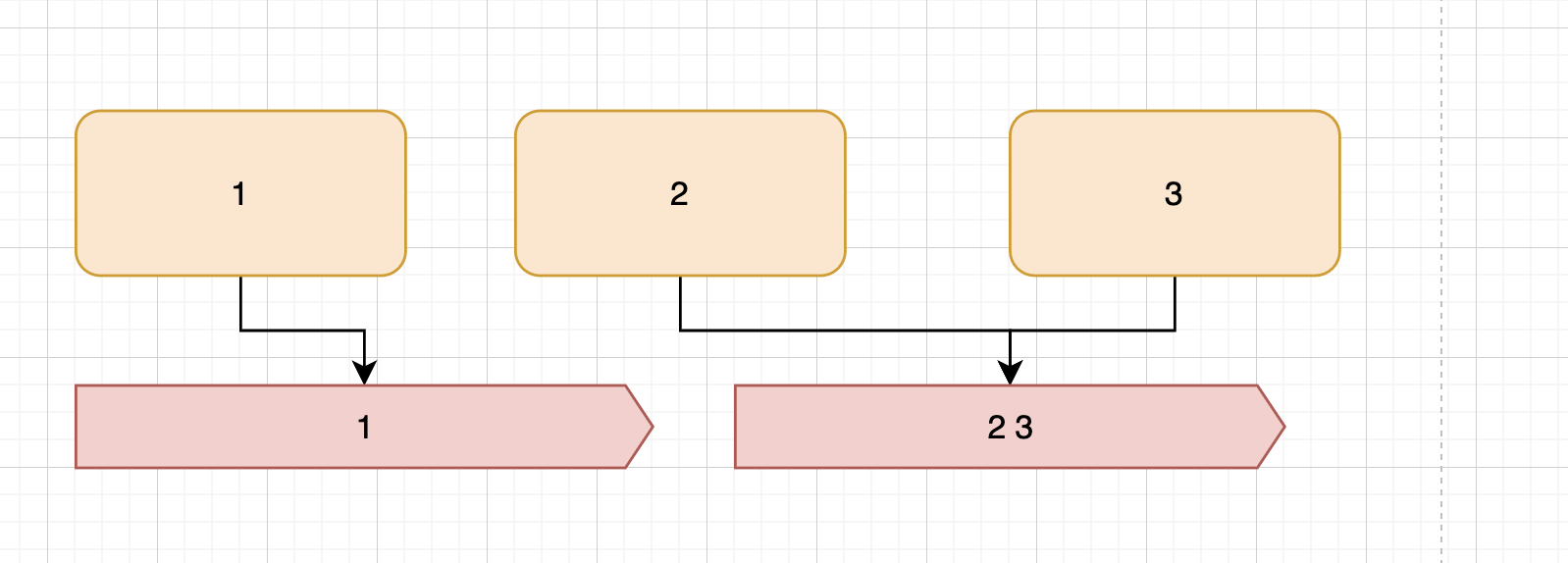
并行流
并行流是充分的利用现代多核计算机的性能而出的。它可以把流分散到各个进程/线程中去执行。来达到并行执行的效果。如下图,1,2,3三个元素,可能会进入2个流中。
源码分析
list的stream方法调用的是Collection类的stream方法。所以首先来看这个方法,该方法返回一个顺序流,顺序流中包含了list中的所有元素。
1 | //该方法返回一个顺序流,顺序流中包含了list中的所有元素。 |
接下来来到StreamSupport类的stream方法。通过spliterator来创建一个顺序流。只有当结果态操作开始后,spliterator才会真正开始运行
1 | /** |
在生成Head对象的时候,第二个参数调用了StreamOpFlag类的fromCharacteristics方法。来看一下这个方法。
可以看到有一个判断是否是自然排序的,如果不是自然排序就会走到if里面,也就是不会将spliterator标记为已排序状态。
最终返回结果为80
1 | //将spliterator的characteristic bit转换为stream flags |
接下来看Head类,它是ReferencePipeline类的一个内部类。主要作用是头节点的一些属性和操作。包括生成头节点等。
1 |
|
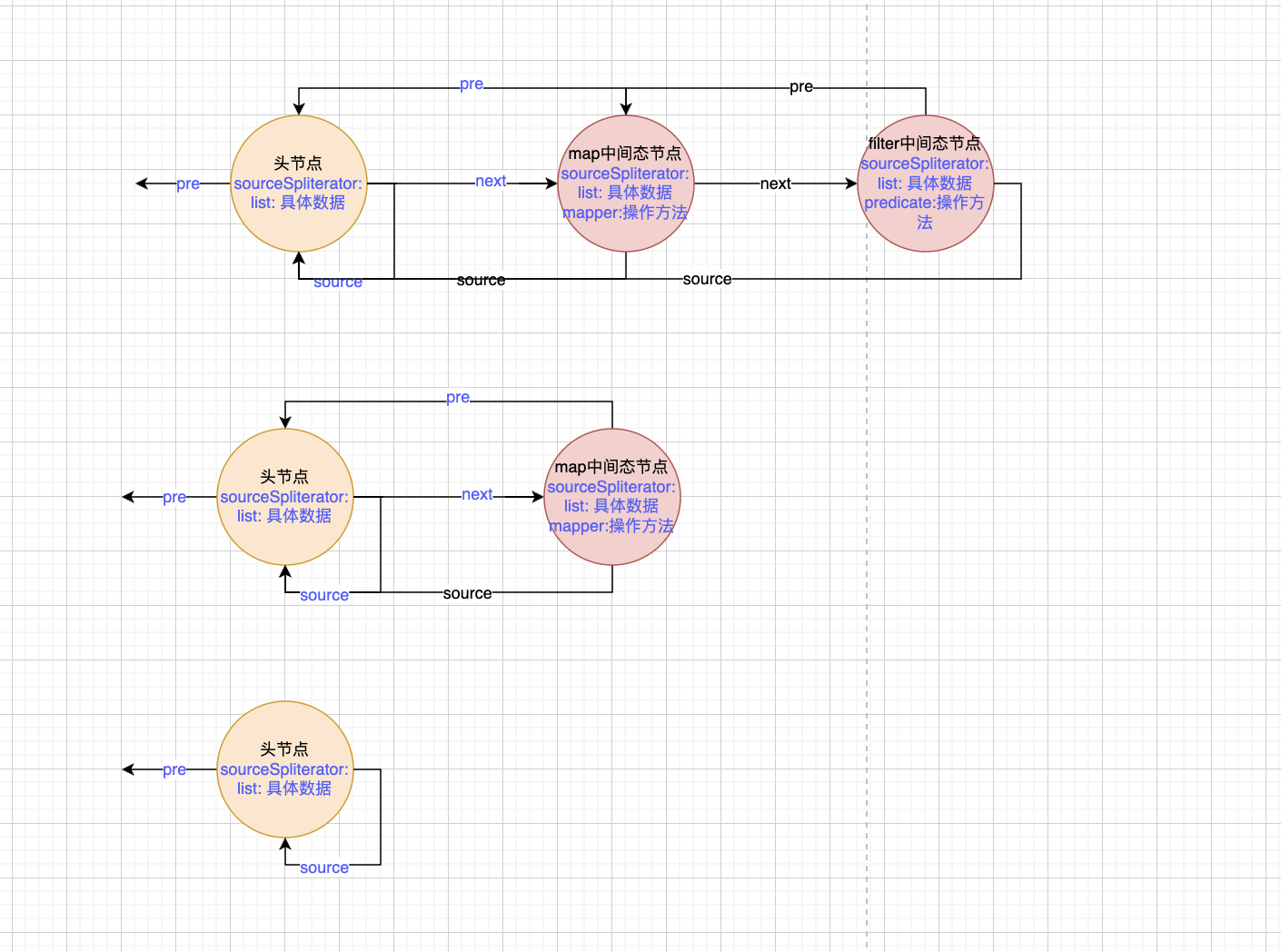
list.stream()函数的源码就完了。主要调用了构造函数,构造了一个含有list数据的头节点,头指针指向空,next指针指向自己。完成了流的初始化。当前数据结构如下。
stream的中间态
中间态的具体源码和流程在后面介绍,这里只介绍中间态的作用。
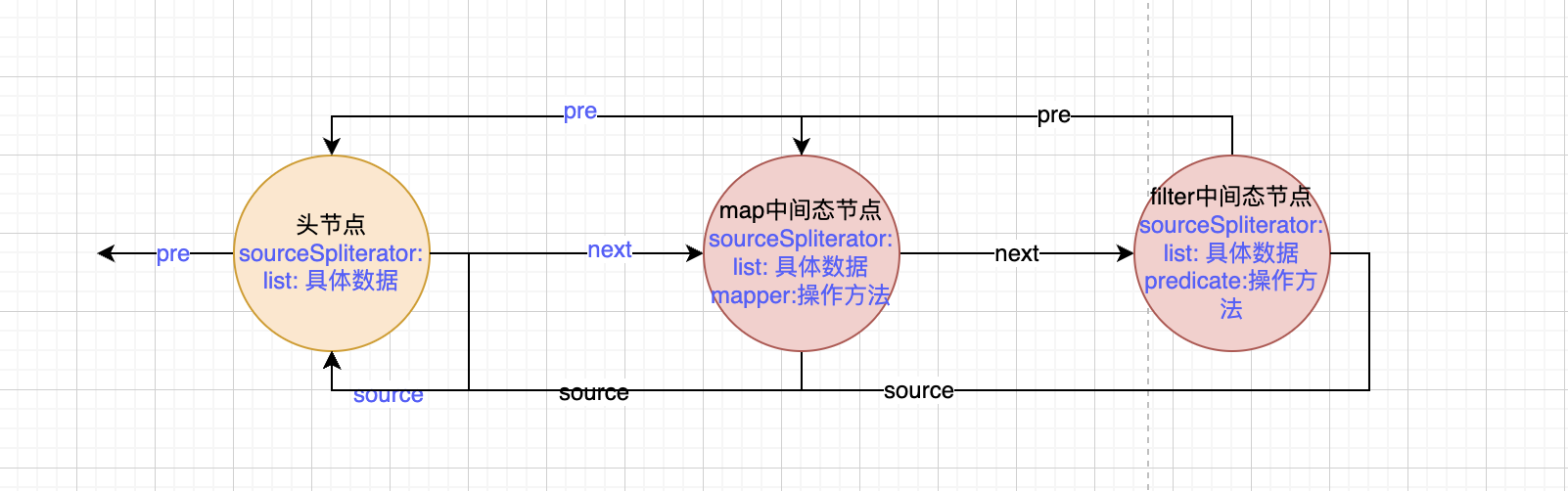
中间态的主要作用是构建双向链表的中间节点。一个操作对应一个节点。比如map,就会创建一个节点。其中pre指针指向前一个节点也就是头节点。而头节点的next指针指向map节点。
filter操作的时候同样创建一个节点,pre指针指向上一个操作也就是map节点。map节点的next指针指向filter节点。
每个中间态节点中都存储了操作,也就是中间态的时候传入的函数。而数据则全部在头节点中。
比如下面这样:
每个中间态节点其实又分成两种
- 有状态节点
- 无状态节点
类图如下:
stream的结果态
结果态的具体源码和流程在后面介绍,这里只介绍结果态的作用。
结果态的主要作用有三个
- 构造结果态节点
- 构造sink链表
- 执行流。
先说第一个,结果态节点是ReduceOp对象。这个结果态节点中包含了一个makeSink方法,用来构建结果态的sink节点。结果态的sink节点是一个ReducingSink对象。
第二个,当结果态节点和结果态的sink节点构造完成以后。接下来会根据之前构建好的双向链表来生成对应的sink链表。
一开始的双向链表我们知道是这样的
而sink链表则是反过来了,根据双向链表从后向前通过pre指针不断向前,把每个节点包裹在sink节点中并通过downstream指针来指向下个节点。这里因为在第一步的时候把源数据取出来了,所以sink中不包含头节点。创建完后如图所示:
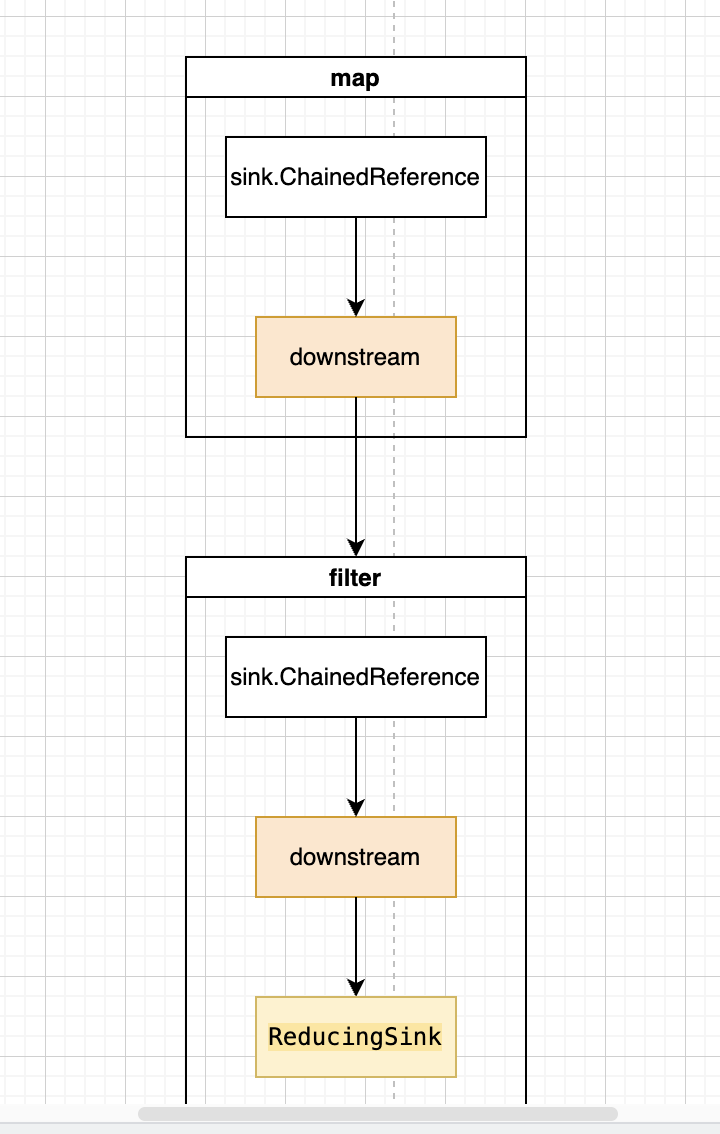
第三步才是真正的执行流。根据sink链表来执行,每次把元素传递给第一个sink也就是map操作,当第一个sink节点处理完以后通过downstream流动到下一个sink节点执行。不断通过downsteram流动,直到最后到结果态的sink执行完以后。再次把第二个元素进行流动执行。直至所有元素执行完毕。
总结
因为是通过自顶向下的方式来了解stream。所以这里主要介绍了stream的执行流程和初始化的源码分析。中间态和结果态的源码分析放在了后面。
在执行流程中可以看到。首先创建了一个双向链表,然后在根据双向链表创建了sink链表。最后通过sink链表进行执行流的操作。也可以看出来确实是流动,传播,充满了stream的味道。
从这里也能看出来为何一开始是双向链表而不是单向的,因为要通过pre指针构造sink链表。
但是这里就有一个问题了,为什么不直接用一开始的双向链表,而要在创建一个sink链表呢?
我个人觉得有几个原因:
- 因为当前处于结果态节点,想从头流动执行,需要当前指针先指向头节点,所以必须遍历一遍。
- 重新构建一个纯净的sink链表,来达到
不变性的性质。保持之前的数据和节点等不可变。 - 双向链表只负责存储数据和操作。真正的执行通过sink链表来执行,达到
单一职责和分层清晰。 - 其中或许还有并行流并发的问题。