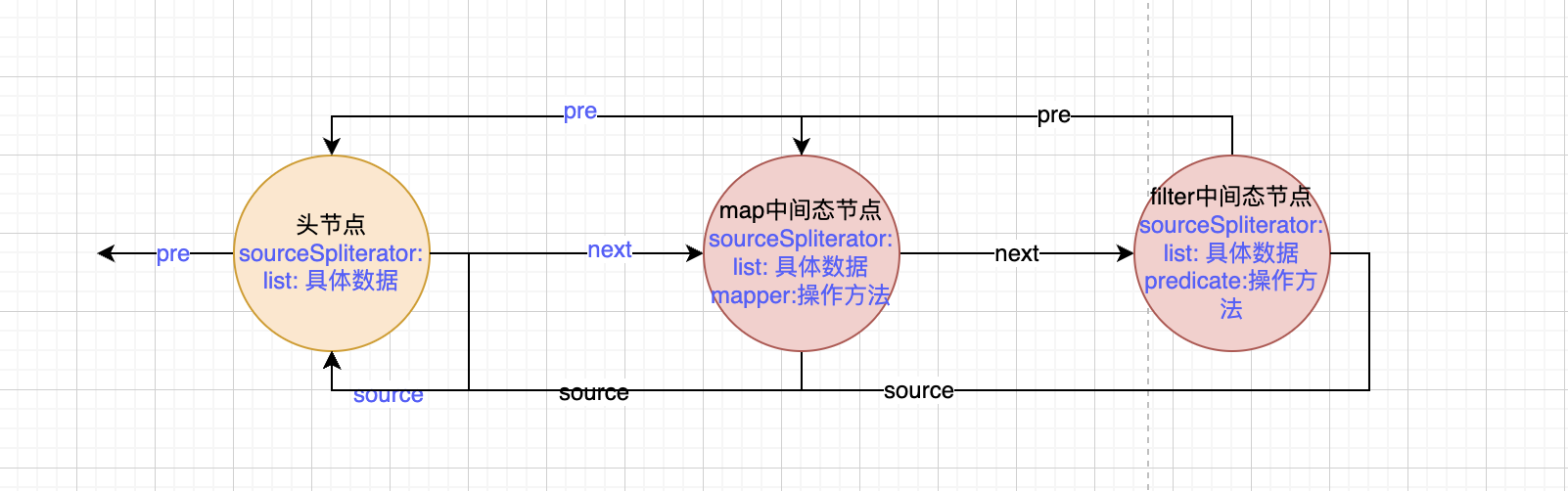
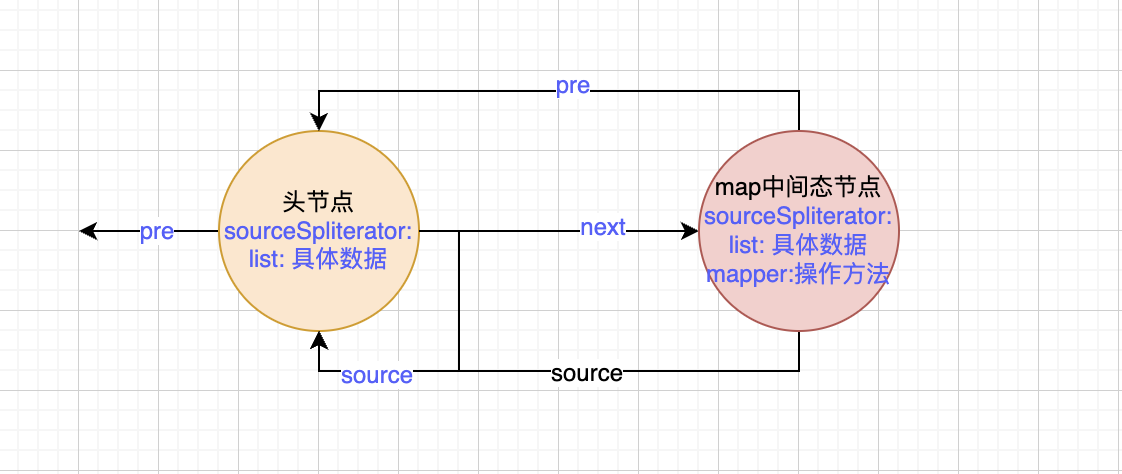
stream stream的中间态 中间态的主要作用是构建双向链表的中间节点。一个操作对应一个节点。比如map,就会创建一个节点。其中pre指针指向前一个节点也就是头节点。而头节点的next指针指向map节点。
filter操作的时候同样创建一个节点,pre指针指向上一个操作也就是map节点。map节点的next指针指向filter节点。
每个中间态节点中都存储了操作,也就是中间态的时候传入的函数。而数据则全部在头节点中。
比如下面这样:
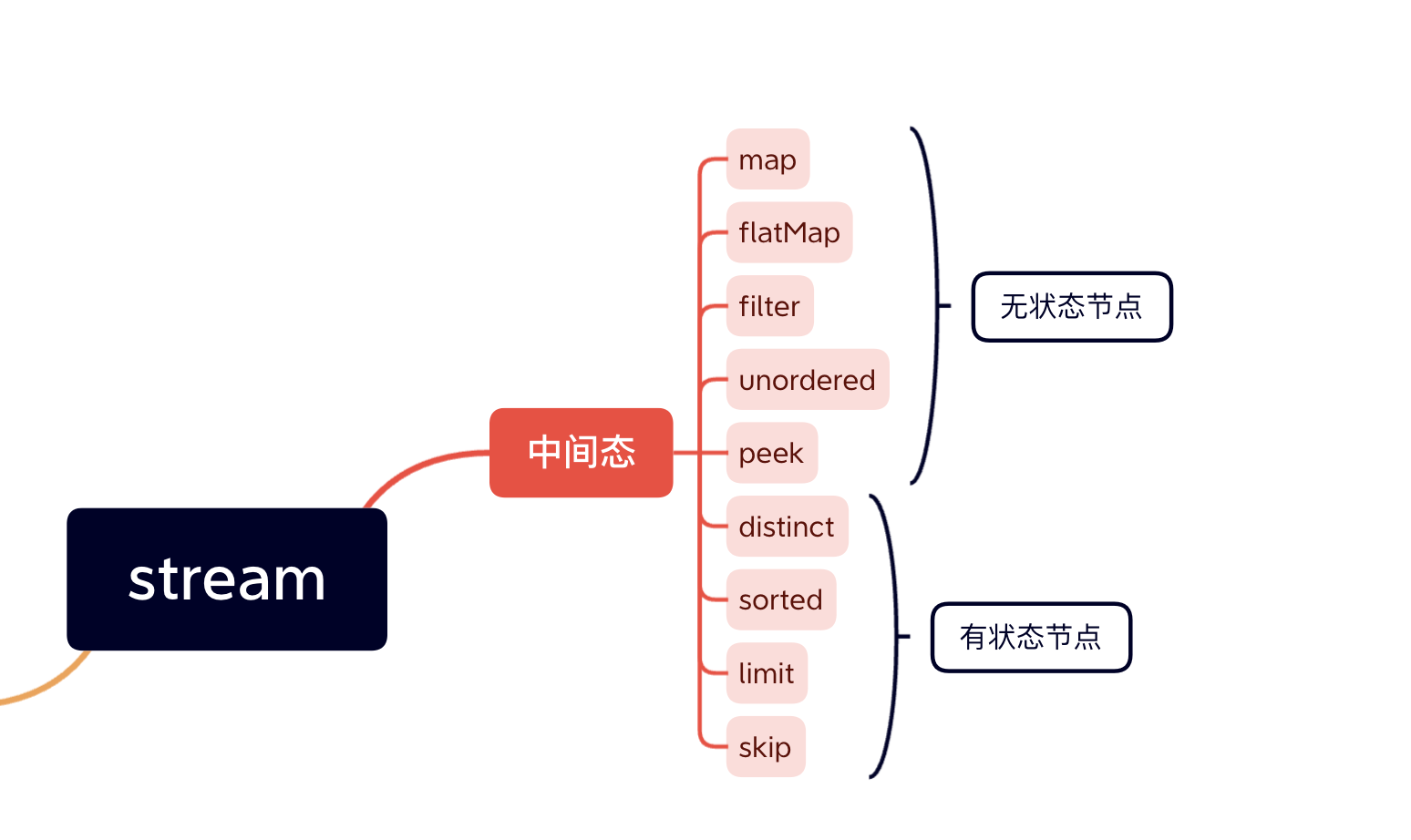
每个中间态节点其实又分成两种
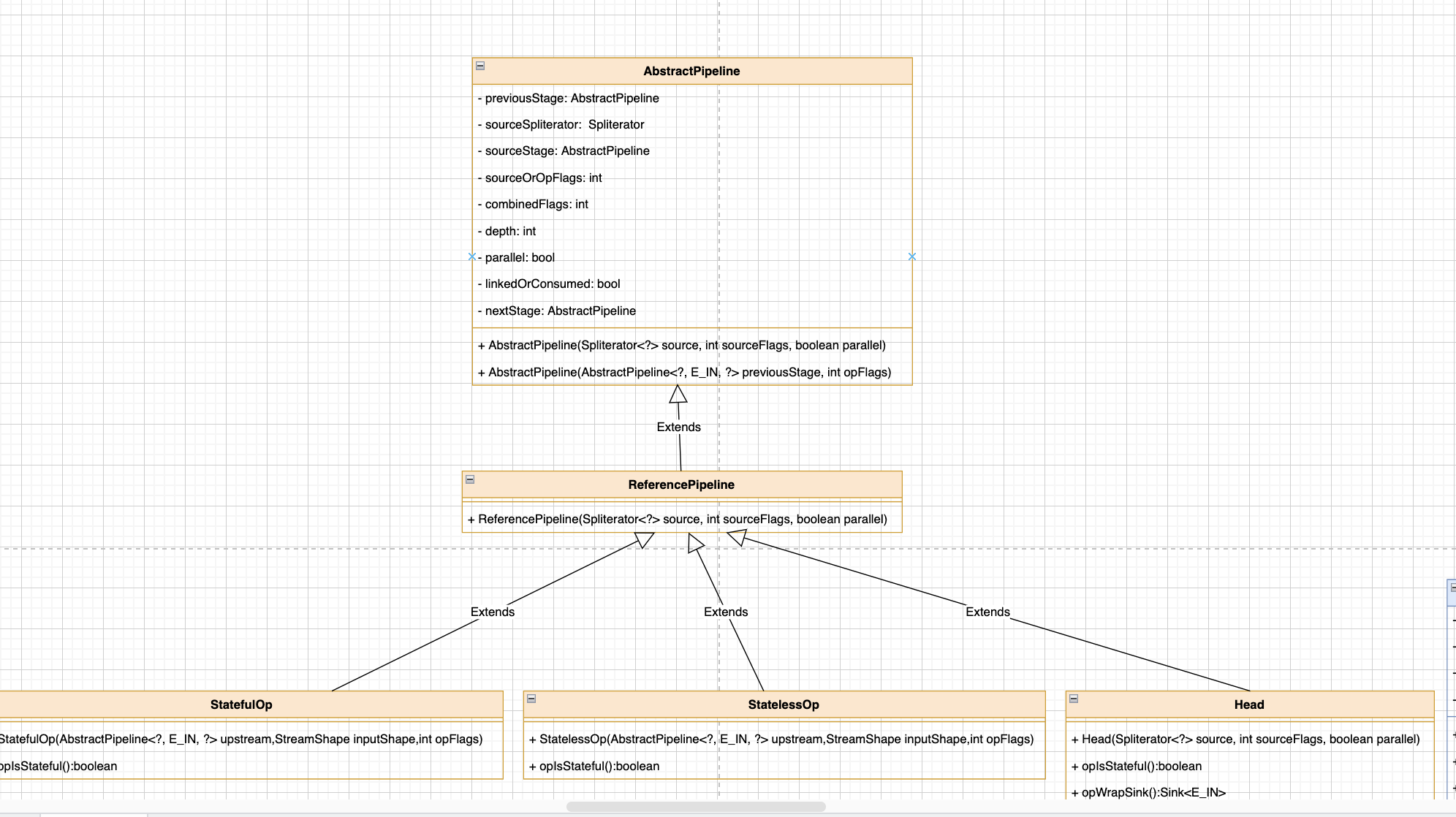
类图如下:
中间态节点的几个操作如下:
我们目前的代码中使用了两个中间态的方法。
map 我们调用的是ReferencePipeline类的map方法。作为中间态方法,需要链式操作,所以返回值当然是一个stream了。接受一个函数作为入参,可以是一个写好的函数,也可以是一个lambda表达式的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 public final <R> Stream<R> map (Function<? super P_OUT, ? extends R> mapper) { Objects.requireNonNull(mapper); return new StatelessOp <P_OUT, R>(this , StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) { @Override Sink<P_OUT> opWrapSink (int flags, Sink<R> sink) { return new Sink .ChainedReference<P_OUT, R>(sink) { @Override public void accept (P_OUT u) { downstream.accept(mapper.apply(u)); } }; } }; } StatelessOp(AbstractPipeline<?, E_IN, ?> upstream, StreamShape inputShape, int opFlags) { super (upstream, opFlags); assert upstream.getOutputShape() == inputShape; } ReferencePipeline(AbstractPipeline<?, P_IN, ?> upstream, int opFlags) { super (upstream, opFlags); } AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) { if (previousStage.linkedOrConsumed) throw new IllegalStateException (MSG_STREAM_LINKED); previousStage.linkedOrConsumed = true ; previousStage.nextStage = this ; this .previousStage = previousStage; this .sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK; this .combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags); this .sourceStage = previousStage.sourceStage; if (opIsStateful()) sourceStage.sourceAnyStateful = true ; this .depth = previousStage.depth + 1 ; } static int combineOpFlags (int newStreamOrOpFlags, int prevCombOpFlags) { return (prevCombOpFlags & StreamOpFlag.getMask(newStreamOrOpFlags)) | newStreamOrOpFlags; } @Override final StreamShape getOutputShape () { return StreamShape.REFERENCE; }
到这里map方法就执行结束了。可以看到这里依然没有真正的执行map方法。只是封装成了一个中间态的节点并加入了双向链表。并将数据list和操作mapper都存入了节点。如下。
filter filter和map一样,作为中间态的方法。来看一下它的源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public final Stream<P_OUT> filter (Predicate<? super P_OUT> predicate) { Objects.requireNonNull(predicate); return new StatelessOp <P_OUT, P_OUT>(this , StreamShape.REFERENCE, StreamOpFlag.NOT_SIZED) { Sink<P_OUT> opWrapSink (int flags, Sink<P_OUT> sink) { return new Sink .ChainedReference<P_OUT, P_OUT>(sink) { @Override public void begin (long size) { downstream.begin(-1 ); } @Override public void accept (P_OUT u) { if (predicate.test(u)) downstream.accept(u); } }; } }; }
当filter完成以后,可以得到下面的数据结构。
其他的中间态方法 总共有9个中间态方法,除了上面的两个还有
无状态
有状态
distinct
sorted
limit
skip
flatMap 先来看flatMap这个。他的作用是把给定的二维数组,转化成一维数组。比如
给定输入:[[1],[2],[3],[4,5]]
要求输出:[1,2,3,4,5]
来看应用层代码。首先构建一个二维数组,然后调用flatMap方法,传入Collection::stream方法进行处理元素,最后通过collect变成一个一维的list。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 List<String> list1 = new ArrayList <>(); List<String> list2 = new ArrayList <>(); List<String> list3 = new ArrayList <>(); List<String > list4 = new ArrayList <>(); list1.add("1" ); list2.add("2" ); list3.add("3" ); list4.add("4" ); list4.add("5" ); List<List<String>> list = new ArrayList <>(); list.add(list1); list.add(list2); list.add(list3); list.add(list4); List<String> listT = list.stream().flatMap(Collection::stream).collect(Collectors.toList()); return listT;
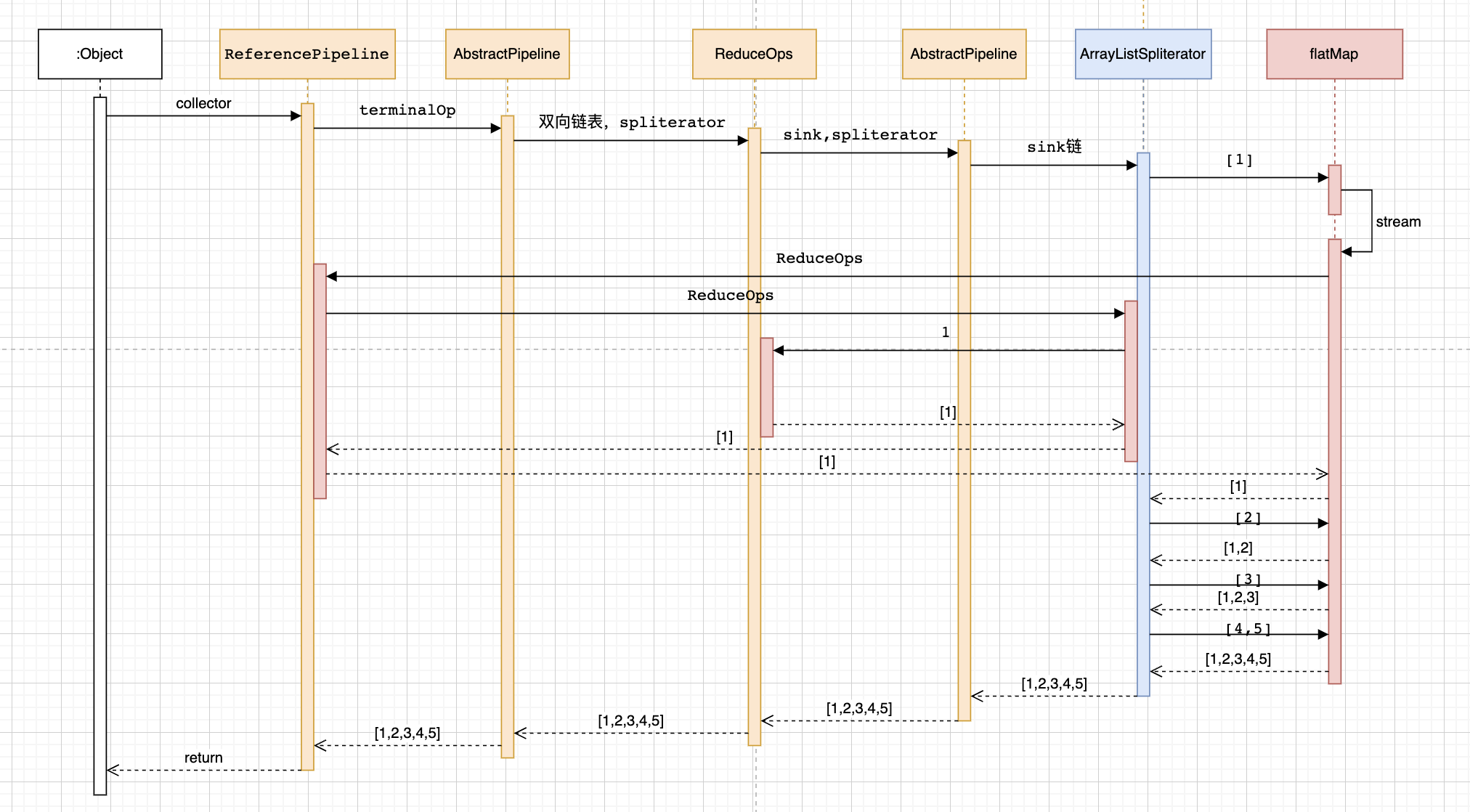
看一下具体的执行流程。橙色的是stream的通用执行流程,不管你中间态用哪个方法,这里是不变的,蓝色的是ArrayListSpliterator分割器。红色的执行流程是flatMap的执行流程。
可以看到ArrayListSpliterator先取出第一个元素[1]这个一维数组传递给flatMap,然后flatMap执行了我们传入的Collection::stream方法,该方法我们之前说过是初始化一个stream头节点。也就是再生成了一个stream
重点就是这里了。再次把[1]这个一维数组放入了新的stream里面。然后把结果态节点ReduceOps传递给了新的stream作为新的stream的结果态节点。
这个时候新的stream开始执行ArrayListSpliterator。从而把[1]一维数组进行for循环,取出了其中的1这个元素,然后把1传入了同一个ReduceOps进行处理从而组成了一个结果list->[1]。
把步骤总结如下:
取出二维数组的第一个一维数组
把一维数组和结果态节点重新创建一个stream
执行stream把一维数组的元素循环放入结果态的list
循环二维数组,不断重复上述步骤,就可以把二维数组展开成一维数组了。
源码分析 来看方法的源码,可以看到接受一个方法,返回一个stream,标准的中间态处理。
可以看到参数校验以后就创建了一个无状态节点,节点的具体创建上面说过了。是一样的,不同的就是accpet这个方法。
这个处理逻辑,接受一个参数,这个参数就是上面传入的一维数组,第一次是[1],第二次是[2],第三次是[3],第四次是[4,5]。因为我们传入的方法是 Collection.stream方法,所以会生成一个新的stream并返回给result。
这个时候的result就是一个只有一个头节点的stream。头节点中包含了一维数组[1]。然后判断stream不为空,则调用stream顺序流进行处理,并把collect结果态节点传入。
当forEach处理完以后,该accept方法处理完成。回到当前流也就是二维数组的流中。然后取出下一个一维数组[2]再次进入accept方法执行。直到当前二维数组的流处理完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @Override public final <R> Stream<R> flatMap (Function<? super P_OUT, ? extends Stream<? extends R>> mapper) { Objects.requireNonNull(mapper); return new StatelessOp <P_OUT, R>(this , StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT | StreamOpFlag.NOT_SIZED) { @Override Sink<P_OUT> opWrapSink (int flags, Sink<R> sink) { return new Sink .ChainedReference<P_OUT, R>(sink) { @Override public void begin (long size) { downstream.begin(-1 ); } @Override public void accept (P_OUT u) { try (Stream<? extends R > result = mapper.apply(u)) { if (result != null ) result.sequential().forEach(downstream); } } }; } }; }
来看一下forEach方法,这个方法很简单。如果不是并行流,那么调用ArrayListSpliterator的forEachRemaining进行处理,传入结果态节点collect。
而forEachRemaining这个方法我们很熟悉了,无非就是循环流中的元素并传入sink链处理。要注意的是这个时候的流是上面新创建的流,这个流里面的元素是[1]这个一维数组。而这个流里面是没有中间态节点的,只有一个传入的collect结果态节点组成的sink链。所以这个流处理完以后就会把[1]里面的1这个元素收集到collect结果态节点中。
当这个forEach处理完这个一维数组以后,返回到上面的accept方法中。
1 2 3 4 5 6 7 8 9 10 11 @Override public void forEach (Consumer<? super E_OUT> action) { if (!isParallel()) { sourceStageSpliterator().forEachRemaining(action); } else { super .forEach(action); } }
unordered 这个方法很少使用。主要是不保证流有序,而不是主动打乱流的顺序。直接看当前类中的方法源码吧。
如果有序,直接返回了,如果无序的话会返回一个无状态节点。而这里面并没有accept操作,而是直接返回了传入的sink节点。
比如传入 reduceOp 这个结果态的sink,那就返回这个。如果传入 map 的 sink 就返回这个sink。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Override public Stream<P_OUT> unordered () { if (!isOrdered()) return this ; return new StatelessOp <P_OUT, P_OUT>(this , StreamShape.REFERENCE, StreamOpFlag.NOT_ORDERED) { @Override Sink<P_OUT> opWrapSink (int flags, Sink<P_OUT> sink) { return sink; } }; } final boolean isOrdered () { return StreamOpFlag.ORDERED.isKnown(combinedFlags); }
peek 这个方法很少使用。主要是调试的时候使用来查看元素是否经过流,当然了也有其他的用法,如果你能保证它不出错的情况下。
来看一个debug的例子。他将打印每一个流经peek方法的元素,在当前场景下,所有元素都会执行打印操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 List<String> list1 = new ArrayList <>(); List<String> list2 = new ArrayList <>(); List<String> list3 = new ArrayList <>(); List<String > list4 = new ArrayList <>(); list1.add("1" ); list2.add("3" ); list3.add("2" ); list4.add("5" ); list4.add("4" ); List<List<String>> list = new ArrayList <>(); list.add(list1); list.add(list2); list.add(list3); list.add(list4); List<String> listT = list.stream().flatMap(Collection::stream).peek(e -> System.out.println(e)).collect(Collectors.toList()); return listT;
但是如果我们修改一下,比如增加filter方法。这个时候,第二个peek方法,就只有>2的元素会流经了,从而只会打印出>2的元素。
1 2 3 4 List<String> listT = list.stream().flatMap(Collection::stream).peek(e -> System.out.println(e)).filter(x -> { return x > 2 ; }).peek(e -> System.out.println(e)).collect(Collectors.toList());
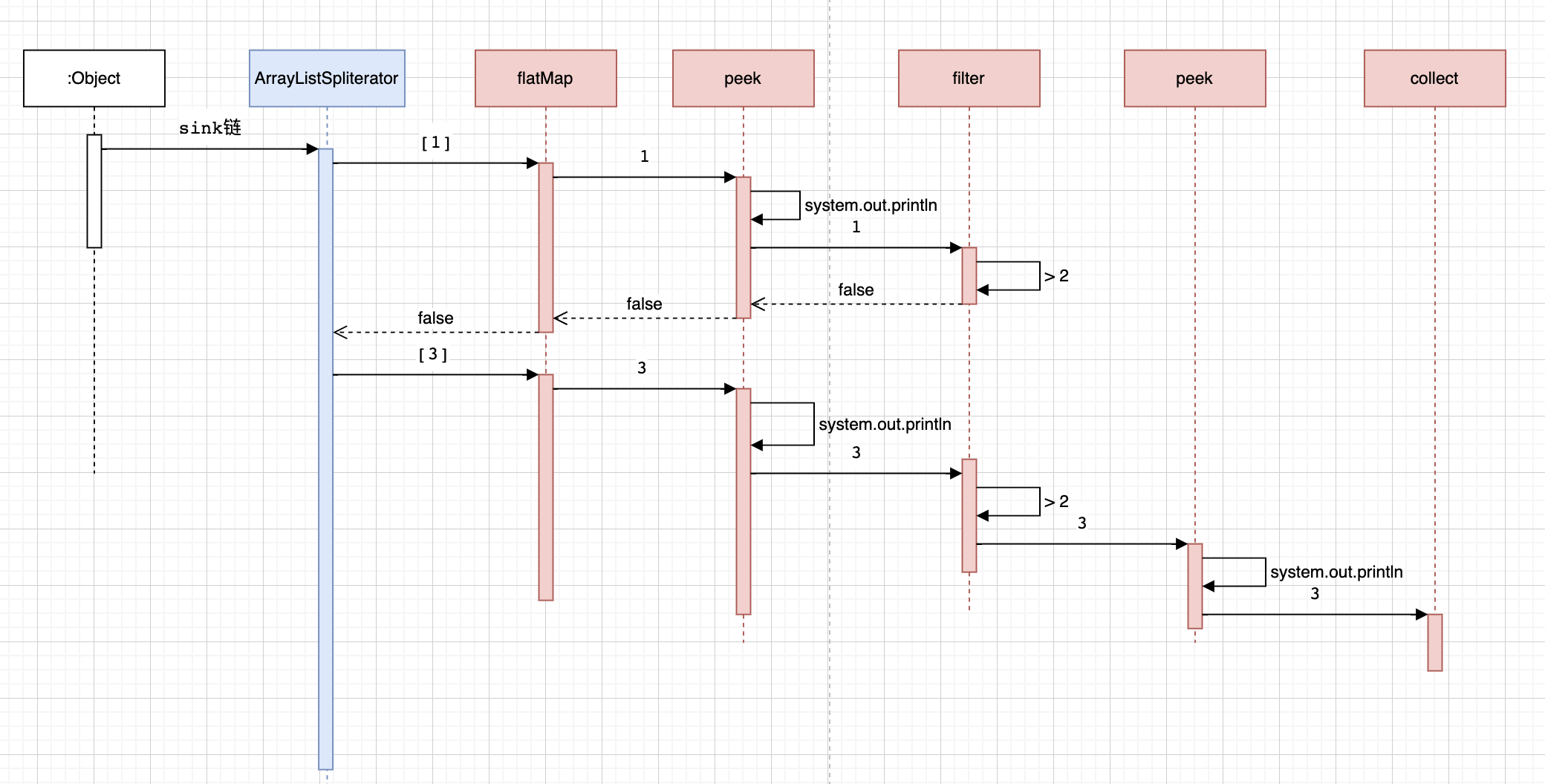
来看一下peek的执行时序图。可以看到第一个元素1执行完filter由于不满足条件所以后面的peek和collect都没有再执行。
而第二个元素3执行完filter以后又执行了peek和collect。所以这就是为什么一般又来debug的原因,因为他不一定执行。
接下来看一下它的源码.接受一个方法进行处理,返回一个stream。
而真正处理的时候,只是把流中的元素作为参数调用了peek的这个方法,然后不管结果,再次流动。相当于在流中间插入了一个方法。
所以理论上,你可以插入任何方法。但是要小心,如果因为某些原因导致流中的元素没有走到你的peek方法中,可能会产生印象不到的问题。
所以官方也更推荐用来debug。
This method exists mainly to support debugging, where you want to see the elements as they flow past a certain point in a pipeline
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Override public final Stream<P_OUT> peek (Consumer<? super P_OUT> action) { Objects.requireNonNull(action); return new StatelessOp <P_OUT, P_OUT>(this , StreamShape.REFERENCE, 0 ) { @Override Sink<P_OUT> opWrapSink (int flags, Sink<P_OUT> sink) { return new Sink .ChainedReference<P_OUT, P_OUT>(sink) { @Override public void accept (P_OUT u) { action.accept(u); downstream.accept(u); } }; } }; }
distinct distinct的作用很明显了,是去重
看一下应用层代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 List<String> list1 = new ArrayList <>(); List<String> list2 = new ArrayList <>(); List<String> list3 = new ArrayList <>(); List<String > list4 = new ArrayList <>(); list1.add("1" ); list2.add("3" ); list3.add("3" ); list4.add("5" ); list4.add("4" ); List<List<String>> list = new ArrayList <>(); list.add(list1); list.add(list2); list.add(list3); list.add(list4); List<String> listT = list.stream().flatMap(Collection::stream).peek(e -> System.out.println(e)).distinct().collect(Collectors.toList()); return listT;
接下来看源码。直接返回DistinctOps节点。
1 2 3 4 @Override public final Stream<P_OUT> distinct () { return DistinctOps.makeRef(this ); }
看一下makeRef这个方法。
他首先是创建了一个有状态节点stateFulOps对象。接下来分为三种情况
先看无序去重,在这个对象的begin初始化中,创建了一个hashSet对象。
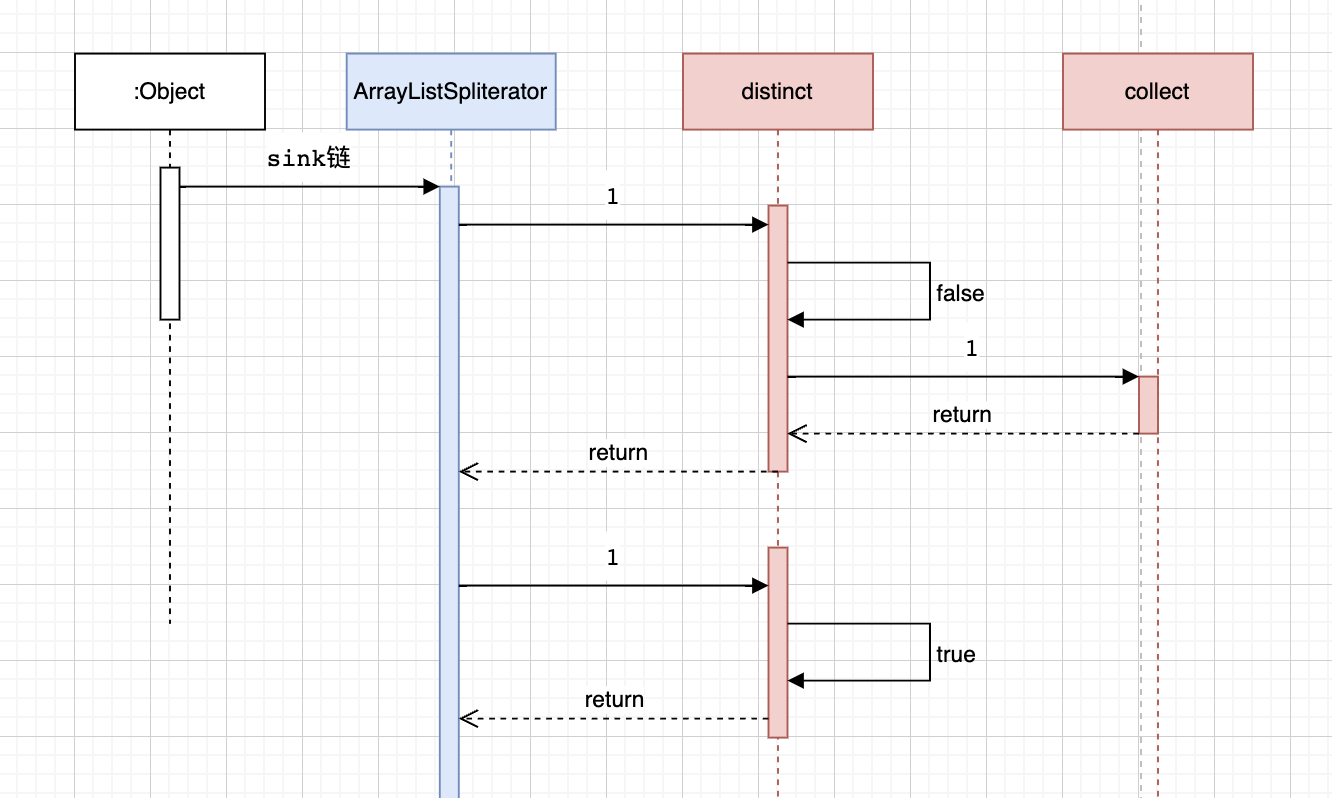
accept执行方法中。首先判断了流中的这个元素是否存在hashSet中,如果存在了就不继续沿着sink链执行了。如果不存在,将元素放入hashSet中并继续执行sink链。
通过hashSet来达到去重的一个效果。这将输出1,3,5,4
再来看有序去重,在这个对象的begin初始化中,创建了seenNull和lastSeen属性。
seenNull: 当前元素是否为null
lastSeen: 上一个元素
在accept方法中。判断当前元素是null并且seenNull = false,那么设置seenNull = true 且 lastSeen = null 并执行下一个操作。
否则,判断 lastSeen 是null也就是代表当前元素是第一个元素,或者 当前元素不等于上一个元素,那么自然是不重复的,所以执行下一个操作。
如果都不满足说明重复。那么不执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 static <T> ReferencePipeline<T, T> makeRef (AbstractPipeline<?, T, ?> upstream) { return new ReferencePipeline .StatefulOp<T, T>(upstream, StreamShape.REFERENCE, StreamOpFlag.IS_DISTINCT | StreamOpFlag.NOT_SIZED) { @Override Sink<T> opWrapSink (int flags, Sink<T> sink) { Objects.requireNonNull(sink); if (StreamOpFlag.DISTINCT.isKnown(flags)) { return sink; } else if (StreamOpFlag.SORTED.isKnown(flags)) { return new Sink .ChainedReference<T, T>(sink) { boolean seenNull; T lastSeen; @Override public void begin (long size) { seenNull = false ; lastSeen = null ; downstream.begin(-1 ); } @Override public void end () { seenNull = false ; lastSeen = null ; downstream.end(); } @Override public void accept (T t) { if (t == null ) { if (!seenNull) { seenNull = true ; downstream.accept(lastSeen = null ); } } else if (lastSeen == null || !t.equals(lastSeen)) { downstream.accept(lastSeen = t); } } }; } else { return new Sink .ChainedReference<T, T>(sink) { Set<T> seen; @Override public void begin (long size) { seen = new HashSet <>(); downstream.begin(-1 ); } @Override public void end () { seen = null ; downstream.end(); } @Override public void accept (T t) { if (!seen.contains(t)) { seen.add(t); downstream.accept(t); } } }; } } }; }
看一下执行的时序图。
sorted sorted作用是按照给定的方法进行排序。其实底层就是调用的List.sort方法或Arrays.sort方法。
如果不传排序方法,将按照自然排序的方法来排序。
看一下应用层代码。
输入 1 3 3 5 4
输出 1 3 3 4 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 List<String> list1 = new ArrayList <>(); List<String> list2 = new ArrayList <>(); List<String> list3 = new ArrayList <>(); List<String> list4 = new ArrayList <>(); list1.add("1" ); list2.add("3" ); list3.add("3" ); list4.add("5" ); list4.add("4" ); List<List<String>> list = new ArrayList <>(); list.add(list1); list.add(list2); list.add(list3); list.add(list4); List<String> listT = list.stream().flatMap(Collection::stream).sorted(String::compareTo).collect(Collectors.toList()); return listT;
接下来看源码。有两个方法,一个是传入给定的排序方法,一个是不传。他们都会通过SortedOps.makeRef创建OfRef对象,这个是StateFulOp的子类。
1 2 3 4 5 6 7 8 9 @Override public final Stream<P_OUT> sorted (Comparator<? super P_OUT> comparator) { return SortedOps.makeRef(this , comparator); } @Override public final Stream<P_OUT> sorted () { return SortedOps.makeRef(this ); }
看一下SortedOps,就是直接创建OfRef对象。
1 2 3 4 5 6 7 8 static <T> Stream<T> makeRef (AbstractPipeline<?, T, ?> upstream) { return new OfRef <>(upstream); } static <T> Stream<T> makeRef (AbstractPipeline<?, T, ?> upstream, Comparator<? super T> comparator) { return new OfRef <>(upstream, comparator); }
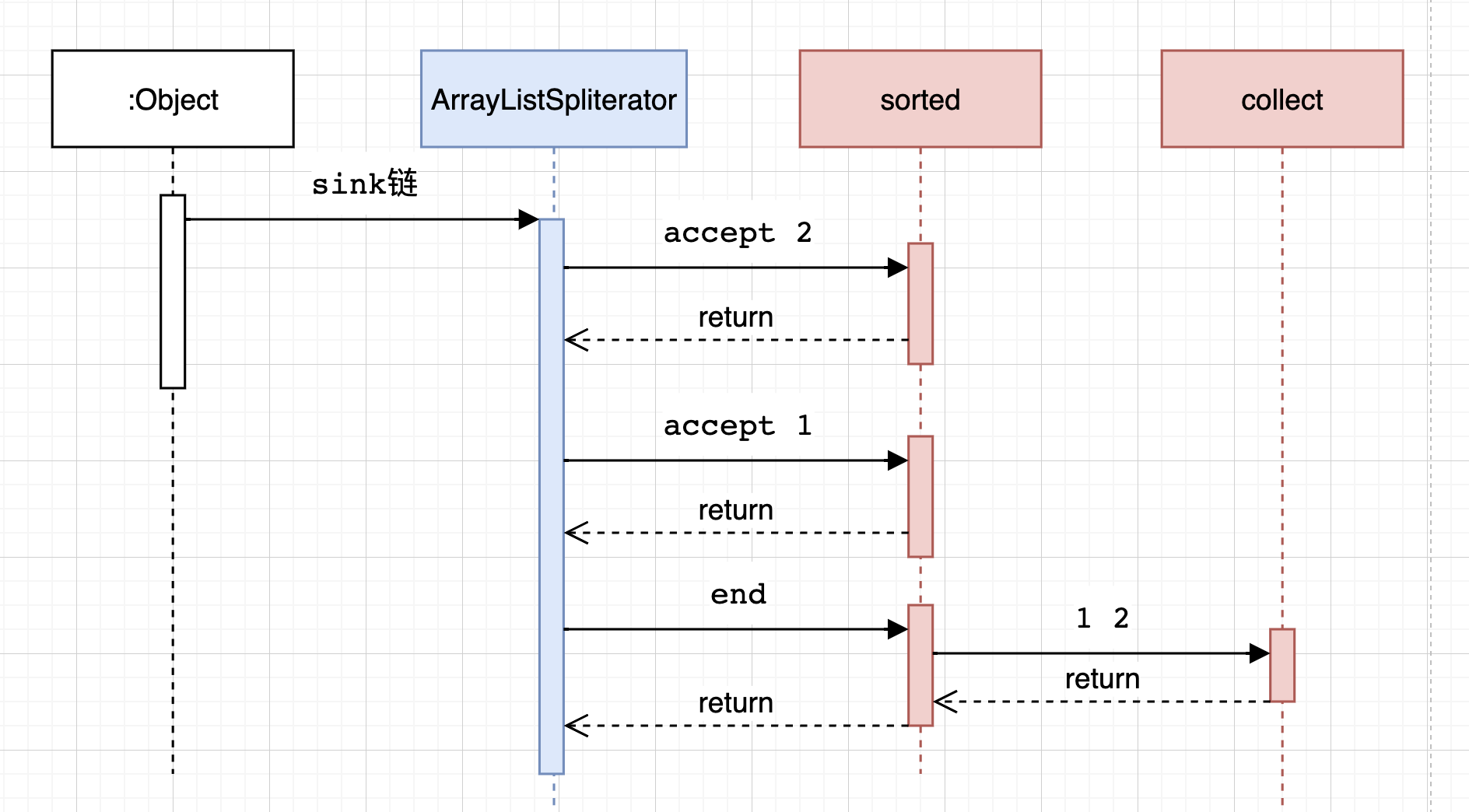
看这个类。有两个属性。最终根据是否有SIZED标志位,来决定使用array处理排序,还是array list处理排序。
isNaturalSort 是否自然有序
comparator 排序比较方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 private static final class OfRef <T> extends ReferencePipeline .StatefulOp<T, T> {private final boolean isNaturalSort;private final Comparator<? super T> comparator;OfRef(AbstractPipeline<?, T, ?> upstream) { super (upstream, StreamShape.REFERENCE, StreamOpFlag.IS_ORDERED | StreamOpFlag.IS_SORTED); this .isNaturalSort = true ; @SuppressWarnings("unchecked") Comparator<? super T> comp = (Comparator<? super T>) Comparator.naturalOrder(); this .comparator = comp; } OfRef(AbstractPipeline<?, T, ?> upstream, Comparator<? super T> comparator) { super (upstream, StreamShape.REFERENCE, StreamOpFlag.IS_ORDERED | StreamOpFlag.NOT_SORTED); this .isNaturalSort = false ; this .comparator = Objects.requireNonNull(comparator); } @Override public Sink<T> opWrapSink (int flags, Sink<T> sink) { Objects.requireNonNull(sink); if (StreamOpFlag.SORTED.isKnown(flags) && isNaturalSort) return sink; else if (StreamOpFlag.SIZED.isKnown(flags)) return new SizedRefSortingSink <>(sink, comparator); else return new RefSortingSink <>(sink, comparator); }
看一下array流的sink节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 private static final class SizedRefSortingSink <T> extends AbstractRefSortingSink <T> { private T[] array; private int offset; SizedRefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) { super (sink, comparator); } @Override @SuppressWarnings("unchecked") public void begin (long size) { if (size >= Nodes.MAX_ARRAY_SIZE) throw new IllegalArgumentException (Nodes.BAD_SIZE); array = (T[]) new Object [(int ) size]; } @Override public void end () { Arrays.sort(array, 0 , offset, comparator); downstream.begin(offset); if (!cancellationWasRequested) { for (int i = 0 ; i < offset; i++) downstream.accept(array[i]); } else { for (int i = 0 ; i < offset && !downstream.cancellationRequested(); i++) downstream.accept(array[i]); } downstream.end(); array = null ; } @Override public void accept (T t) { array[offset++] = t; } } private static abstract class AbstractRefSortingSink <T> extends Sink .ChainedReference<T, T> { protected final Comparator<? super T> comparator; protected boolean cancellationWasRequested; AbstractRefSortingSink(Sink<? super T> downstream, Comparator<? super T> comparator) { super (downstream); this .comparator = comparator; } @Override public final boolean cancellationRequested () { cancellationWasRequested = true ; return false ; } }
看一下array list的sink节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 private static final class RefSortingSink <T> extends AbstractRefSortingSink <T> { private ArrayList<T> list; RefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) { super (sink, comparator); } @Override public void begin (long size) { if (size >= Nodes.MAX_ARRAY_SIZE) throw new IllegalArgumentException (Nodes.BAD_SIZE); list = (size >= 0 ) ? new ArrayList <T>((int ) size) : new ArrayList <T>(); } @Override public void end () { list.sort(comparator); downstream.begin(list.size()); if (!cancellationWasRequested) { list.forEach(downstream::accept); } else { for (T t : list) { if (downstream.cancellationRequested()) break ; downstream.accept(t); } } downstream.end(); list = null ; } @Override public void accept (T t) { list.add(t); } }
最后看一下时序图。
limit limit的作用是选取多少个元素。常常用在截取流的一部分。
还是以上面的排序代码为例,排序后只取前3个元素,就可以使用limit(3).
1 2 3 List<String> listT = list.stream().flatMap(Collection::stream).sorted(String::compareTo).limit(3 ).collect(Collectors.toList());
简单看一下源码
1 2 3 4 5 6 7 8 @Override public final Stream<P_OUT> limit (long maxSize) { if (maxSize < 0 ) throw new IllegalArgumentException (Long.toString(maxSize)); return SliceOps.makeRef(this , 0 , maxSize); }
看一下创建的节点。这个节点里面包含了一个sink节点。
sink节点中有两个属性
n 也就是skip 跳过哪些,这里是0
m 也就是limit 取哪些,我们这里是3
首先在初始化的时候限制了接下里节点初始化的大小。
真正处理的时候,如果有跳过的,先进行跳过,没有跳过的,就进行流动,当流动的元素数量达到limit个数量以后,不再流动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 public static <T> Stream<T> makeRef (AbstractPipeline<?, T, ?> upstream, long skip, long limit) { if (skip < 0 ) throw new IllegalArgumentException ("Skip must be non-negative: " + skip); return new ReferencePipeline .StatefulOp<T, T>(upstream, StreamShape.REFERENCE, flags(limit)) { @Override Sink<T> opWrapSink (int flags, Sink<T> sink) { return new Sink .ChainedReference<T, T>(sink) { long n = skip; long m = limit >= 0 ? limit : Long.MAX_VALUE; @Override public void begin (long size) { downstream.begin(calcSize(size, skip, m)); } @Override public void accept (T t) { if (n == 0 ) { if (m > 0 ) { m--; downstream.accept(t); } } else { n--; } } @Override public boolean cancellationRequested () { return m = = 0 || downstream.cancellationRequested(); } }; } }; } private static int flags (long limit) { return StreamOpFlag.NOT_SIZED | ((limit != -1 ) ? StreamOpFlag.IS_SHORT_CIRCUIT : 0 ); } private static long calcSize (long size, long skip, long limit) { return size >= 0 ? Math.max(-1 , Math.min(size - skip, limit)) : -1 ; }
skip skip就是跳过多少个元素。可以和limit结合起来一起截取流。
还是以上面的代码为例.skip 1 , limit 3就代表取第2个元素到第4个元素。
1 List<String> listT = list.stream().flatMap(Collection::stream).sorted(String::compareTo).skip(1 ).limit(3 ).collect(Collectors.toList());
简单看一下源码。如果skip小于0就抛出异常,如果==0就直接返回,相当于不跳过。
创建节点的时候用的和上面limit的是一样的方法。只是参数变成了传skip,不传limit.
1 2 3 4 5 6 7 8 9 10 @Override public final Stream<P_OUT> skip (long n) { if (n < 0 ) throw new IllegalArgumentException (Long.toString(n)); if (n == 0 ) return this ; else return SliceOps.makeRef(this , n, -1 ); }
总结 好了,到这里为止,就分析完了stream所有的中间操作。
从源码的角度分析了他们是如何运行的,都有什么作用。
总结一下。这些操作主要分为两大类
作为中间操作,他们的返回类型全部是 stream。