大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
关注我发送”MySQL知识图谱”领取完整的MySQL学习路线。
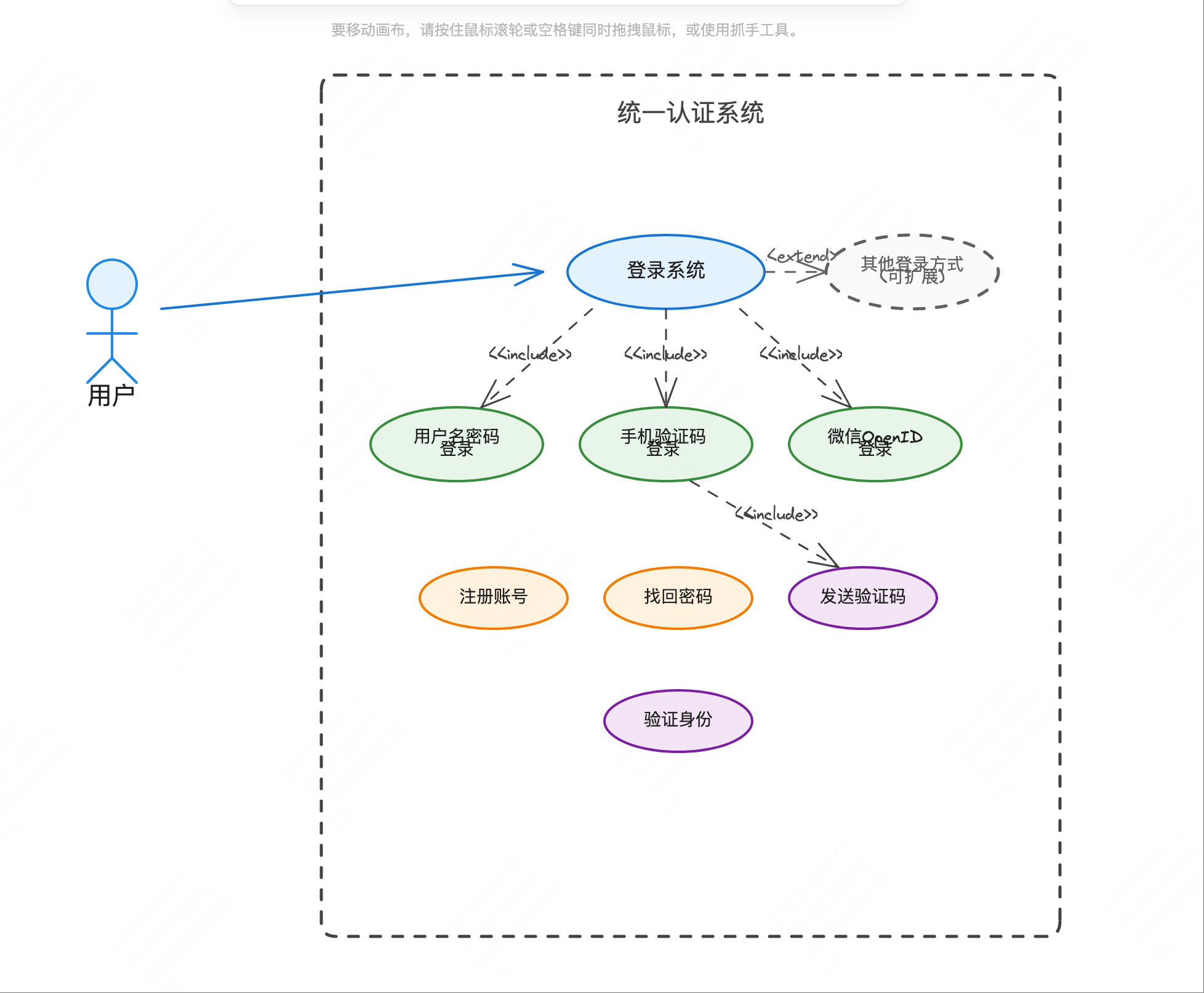
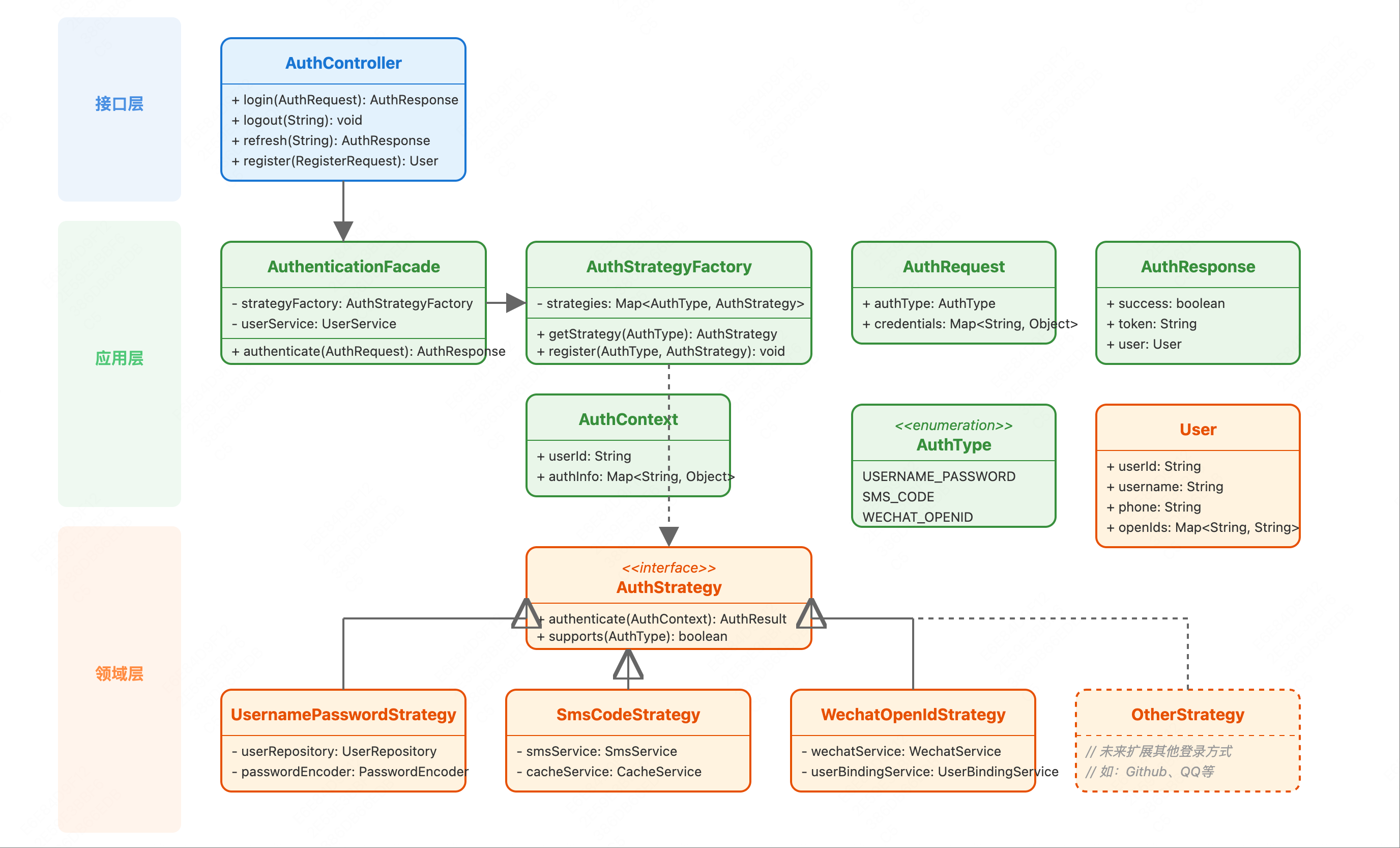
DDD记账软件实战四 前情提要 在实战三中,我们完成了登录系统的设计与实现,运用了策略模式、工厂模式等设计模式,实现了一个可扩展的多种登录方式的认证系统。
我们已经按照DDD划分了目录并创建了项目结构:
starter: 接口层,包括HTTP接口、队列的消费者、DTO、启动类
api: 接口层,提供RPC接口,包括外部RPC接口需要使用的DTO、枚举等
application:应用服务层,放应用服务,负责编排领域服务、聚合根等。
domain:领域服务层,放领域相关的一切信息,领域服务负责编排聚合根,聚合根负责完成自身的业务逻辑。
infrastructure: 基础设施层,放配置、仓储、工厂、对外部的请求、发送MQ消息等。
common: 放一些公共信息。
技术栈版本:
Spring Boot 3.5.4
Java 21
如何设计一个记账微服务 在完成用户认证系统后,我们要开始实现核心的业务功能了。对于记账软件来说,记账功能是最核心的模块。
记账功能看似简单,但是涉及的业务逻辑其实不少,比如:
账本管理
账本列表
创建账本
更新账本信息
删除账本
更新账本预算
查询账本预算
查询账本信息
邀请用户加入账本
用户加入账本
账本成员管理
收入支出记录管理
分类管理
面对如此复杂的记账业务,如何设计一个既能满足当前需求,又能支持未来扩展的微服务架构呢?
有办法的,兄弟,DDD来解决。
业务流程 基于DDD的核心思想,我们需要先理解业务,然后识别核心领域,最后通过代码来实现业务逻辑。
而针对复杂的业务场景,在软件设计上已经有了很多前人的智慧,比如领域驱动设计原则、各种企业级设计模式等。
首先,我们应该梳理一下记账的核心业务流程。深入理解业务是做好架构设计的基础。
用户进入记账小程序页面后,首先看到的就是一个账本列表,需要从账本列表中选择一个账本,然后点击记账、选择收入/支出类型,接着选择分类(如餐饮、交通等),填写金额和备注,最后保存记录。
从这个流程可以看出,记账涉及三个核心业务概念:
账本(AccountBook) - 用户可以创建多个账本,比如个人账本、家庭账本记录(Record) - 具体的收入支出记录分类(Category) - 对收支进行分类管理
因此,我们可以识别出三个核心领域模型。
领域分析 基于DDD的思想,我们需要对记账业务进行领域分析,识别出核心的聚合根、实体和值对象。
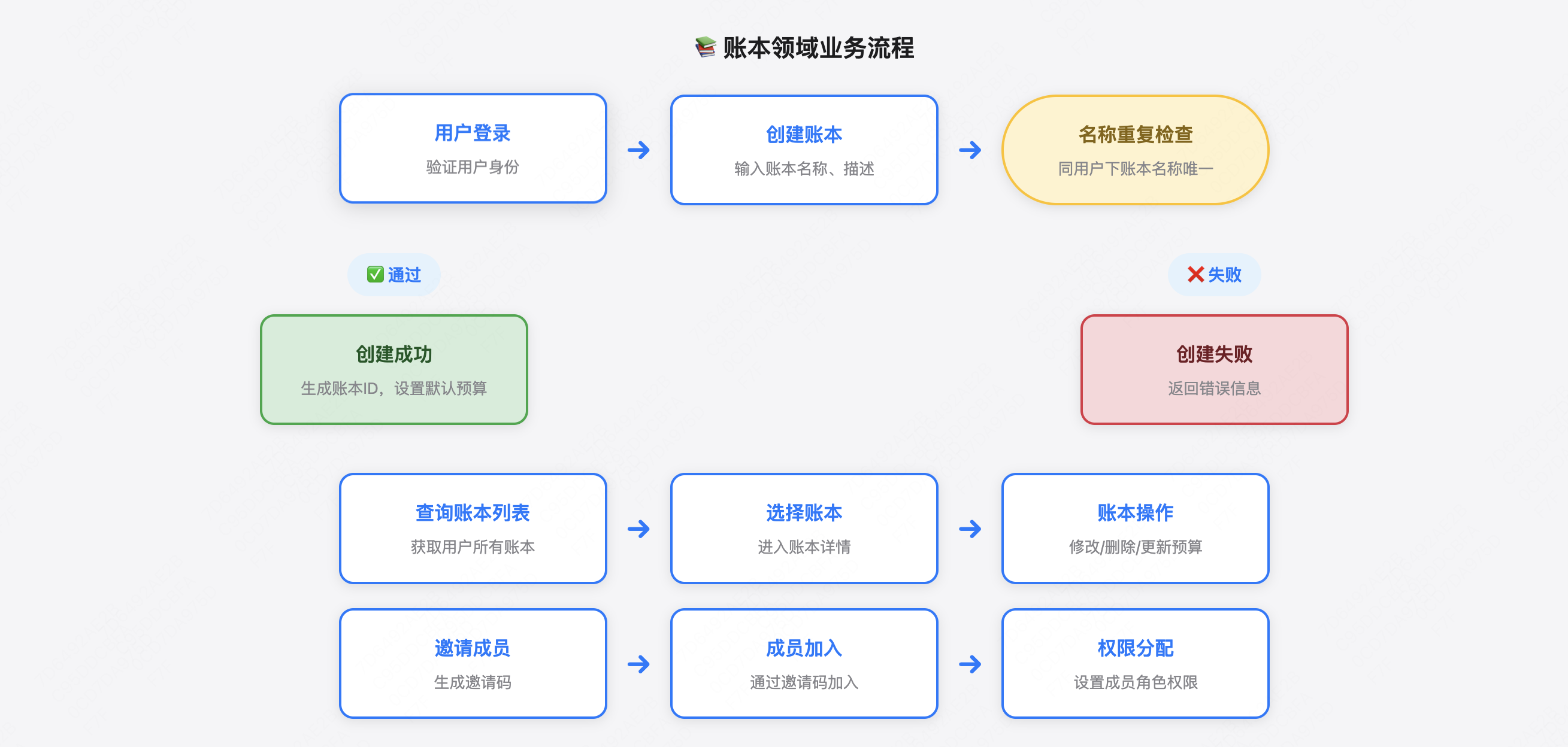
账本领域(AccountBook Domain) 账本是用户记账的载体,一个用户可以有多个账本。
核心业务逻辑:
创建账本
修改账本信息
删除账本
查询账本列表
查询账本信息
更新账本预算
加入账本
查询账本的成员列表
业务规则:
同一用户下的账本名称不能重复
删除账本时需要检查是否还有记录
只有账本管理员可以删除账本
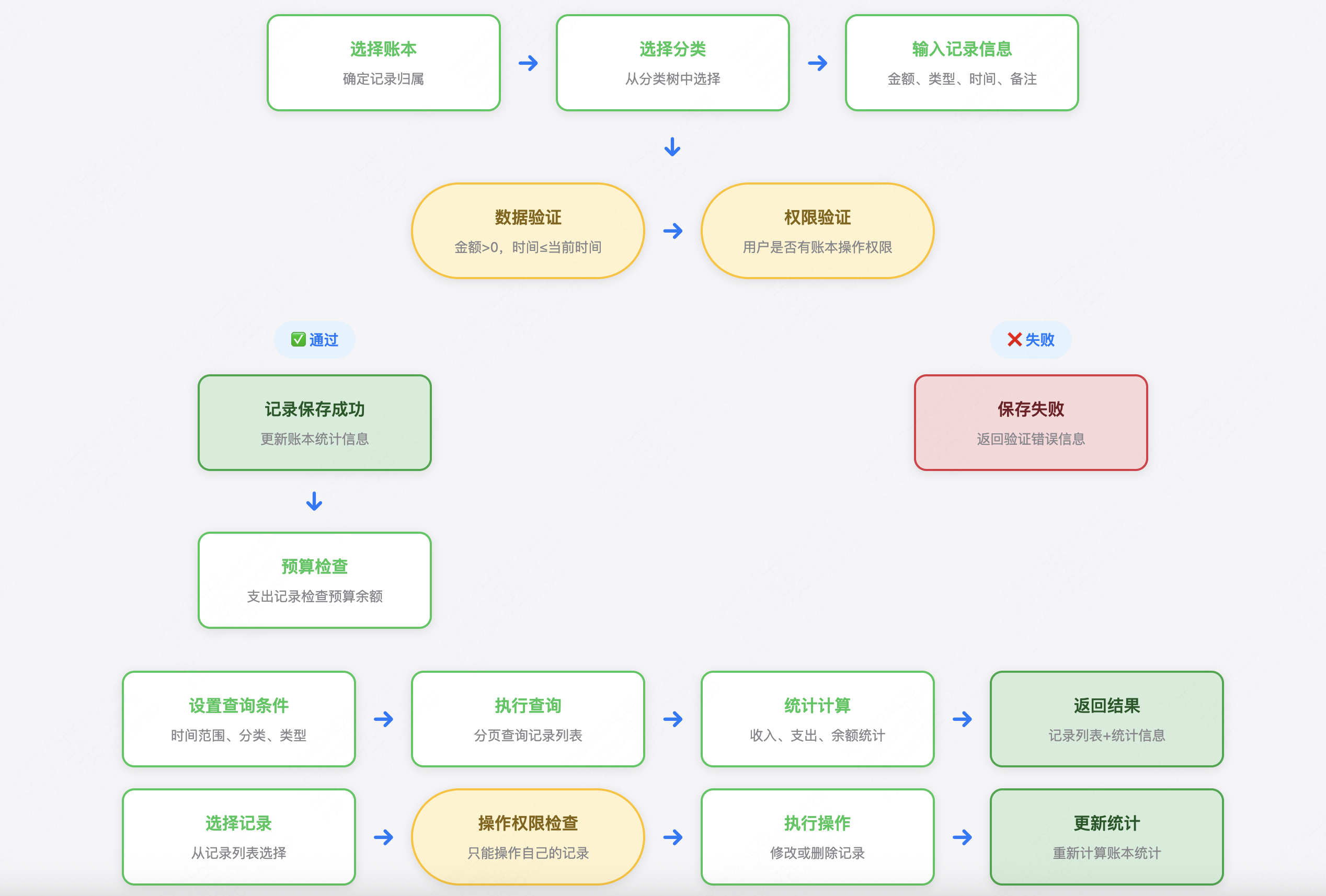
记录领域(Record Domain) 记录是记账的核心,包含收入和支出两种类型。
核心业务逻辑:
添加收支记录
修改记录信息
删除记录
查询记录列表
业务规则:
金额必须大于0
记录必须归属于某个账本
记录必须有分类
记录时间不能超过当前时间
删除记录需要权限验证
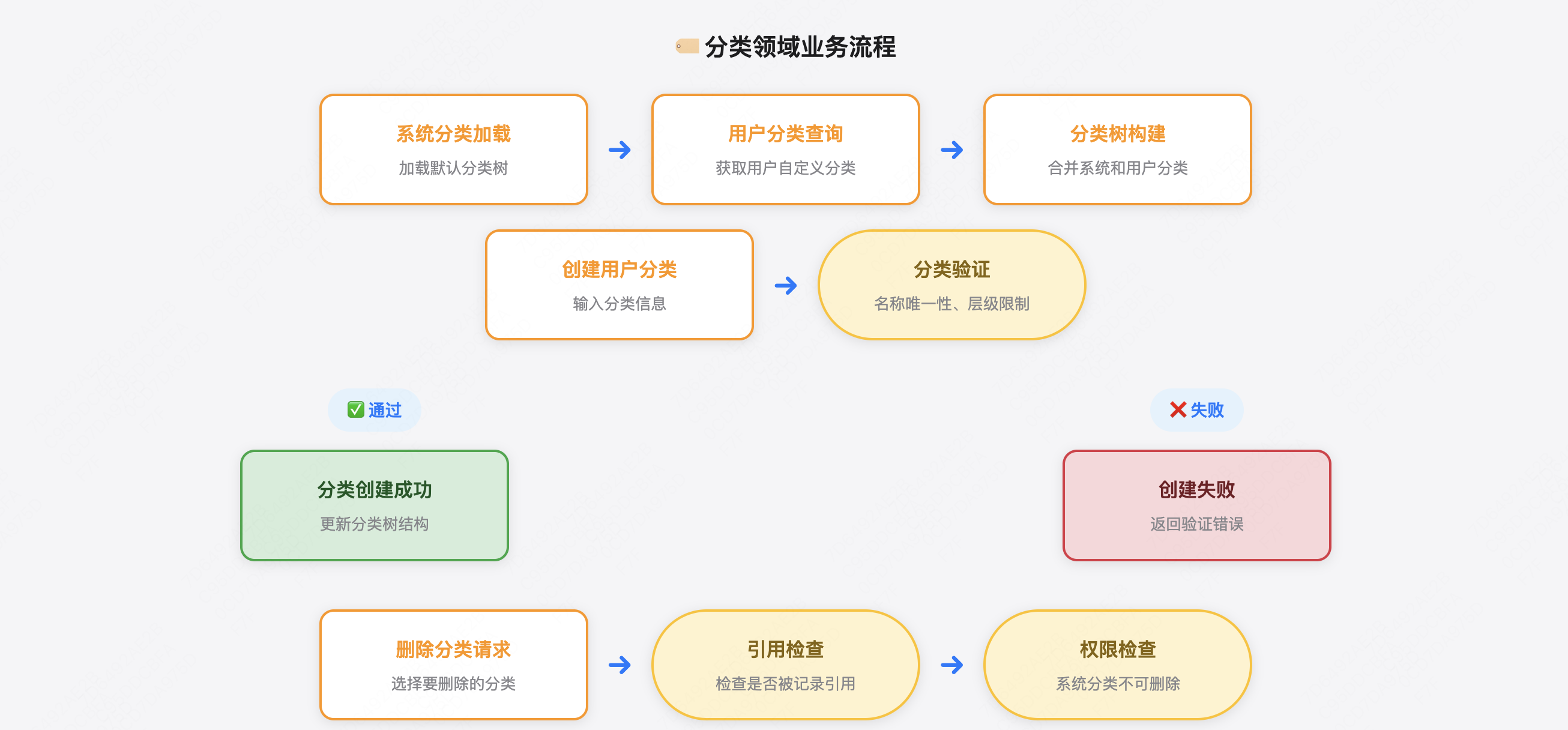
分类领域(Category Domain) 分类是记账系统中对收支记录进行归类管理的重要功能,帮助用户更好地分析自己的消费习惯和收入来源。分类分为系统分类和用户分类。
系统分类是系统自带的一些分类,这些分类是所有用户都可以使用的,一些通用的分类。
用户分类是用户自身维护的一些分类,可以根据用户自己的使用习惯来创建不同的分类,这些分类只能用户自己使用,方便用户自定义自身的需求。
核心业务逻辑:
系统分类管理
用户分类管理
创建用户自定义分类
修改用户分类信息
删除用户分类
查询用户分类列表
分类层级管理
支持父子分类关系(如:餐饮 -> 早餐/午餐/晚餐)
查询完整分类树结构
分类层级深度限制(建议最多3层)
分类统计分析
按分类统计收支金额
分类使用频率统计
分类趋势分析
业务规则:
分类层级规则 :支持树形结构,最多支持2级分类(一级分类 -> 二级分类)删除约束 :删除分类时需要检查是否被记录引用,如有引用则不能删除系统分类保护 :系统提供的默认分类不可删除和修改,保证基础功能可用用户分类权限 :用户只能管理自己创建的分类,不能修改他人分类分类名称唯一性 :同一层级下的分类名称不能重复分类图标 :每个分类可以设置图标,提升用户体验
常见系统默认分类:
支出分类:
餐饮美食(早餐、午餐、晚餐、夜宵)
交通出行(打车、公交、地铁、加油)
购物消费(服装、数码、日用品)
娱乐休闲(电影、游戏、旅游)
医疗健康(看病、买药、体检)
生活缴费(水电费、房租、话费)
学习教育(培训、书籍、课程)
接下来我们需要分析,这三个领域之间的关系和需要使用哪些能力。
从业务架构图可以看出:
账本是聚合根,管理属于它的记录
记录依赖分类进行归类
三个领域之间通过领域事件进行解耦
统计分析等功能可以通过读模型实现
这样,我们就明确了记账微服务的核心业务能力和领域边界。
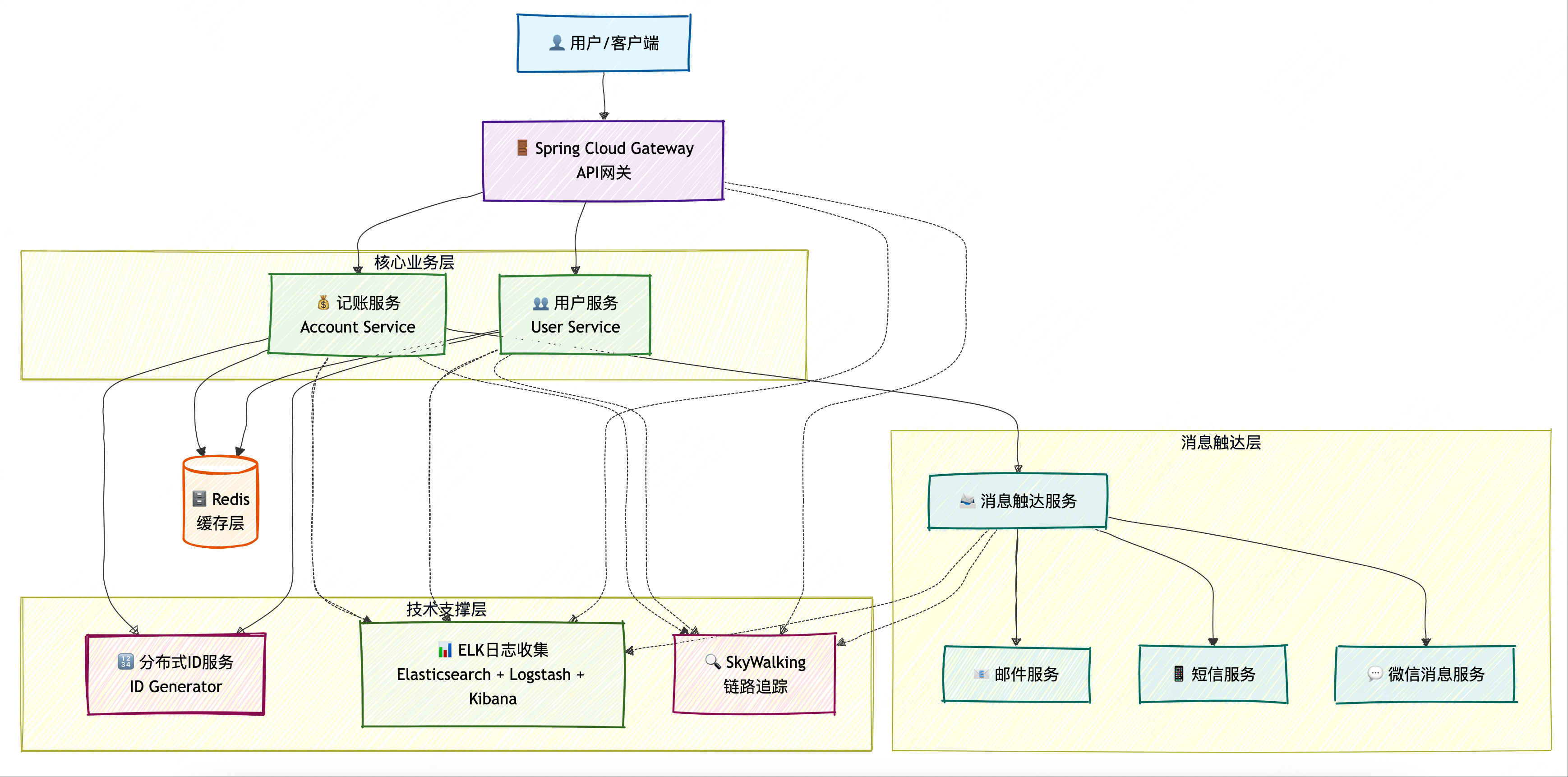
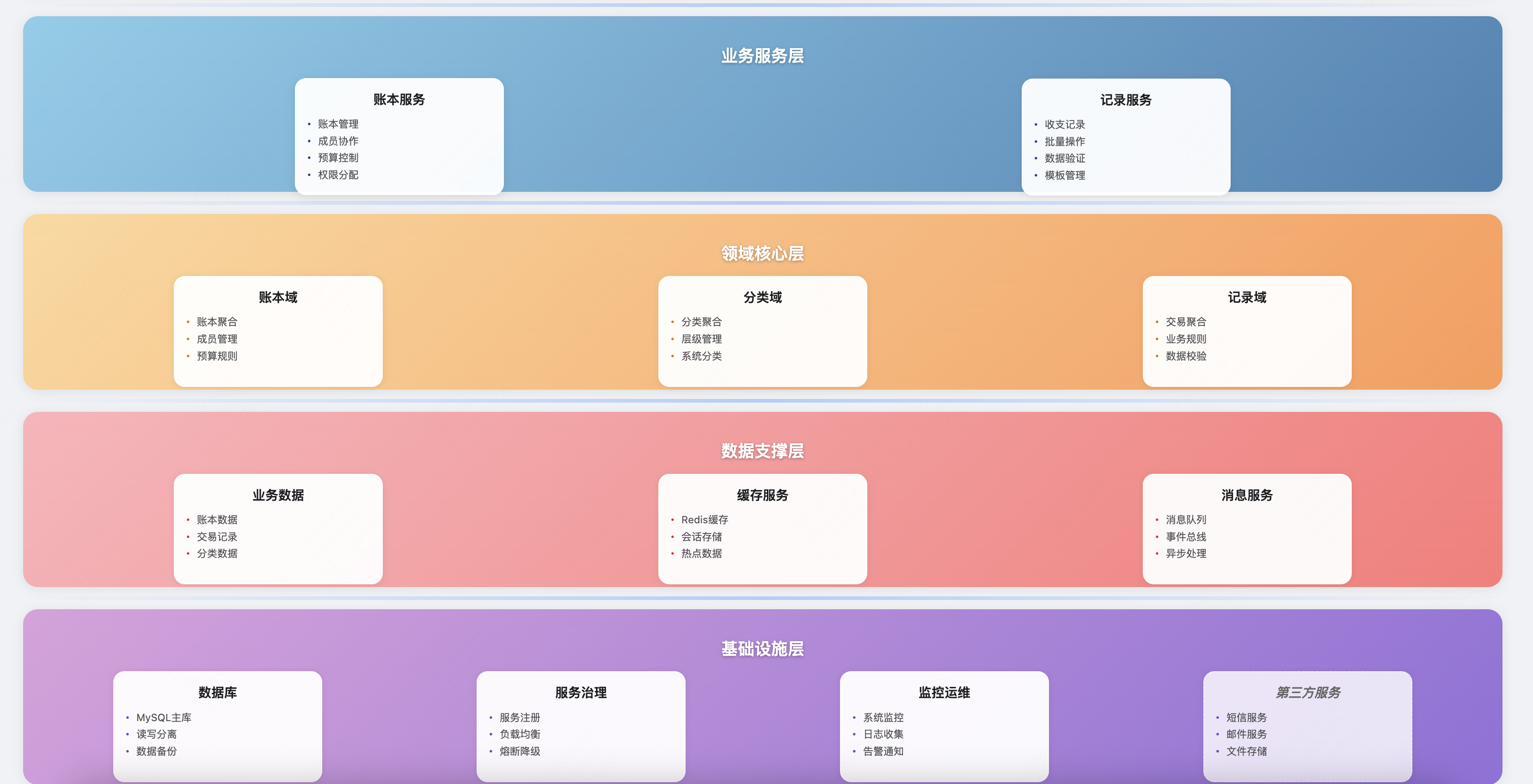
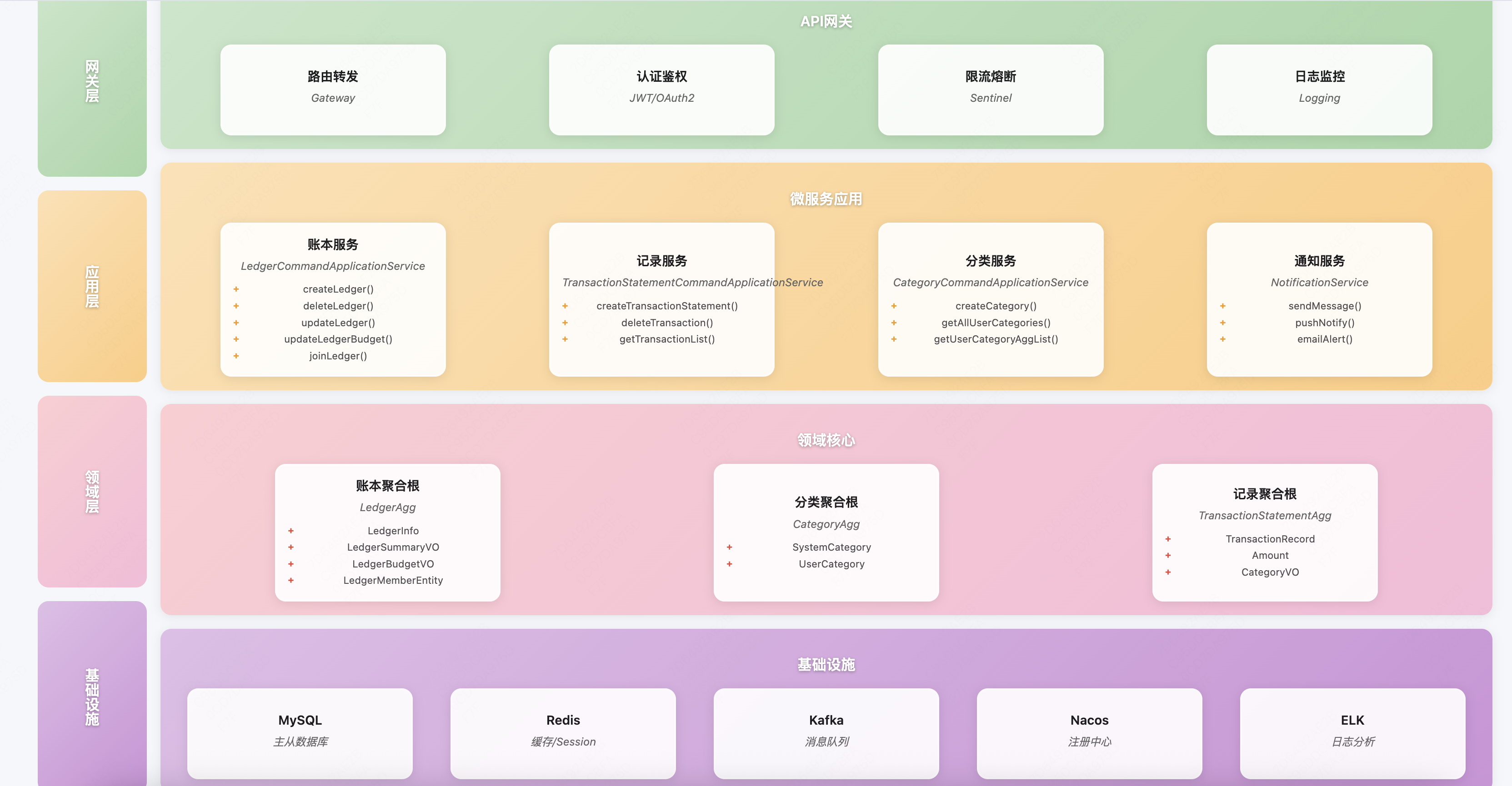
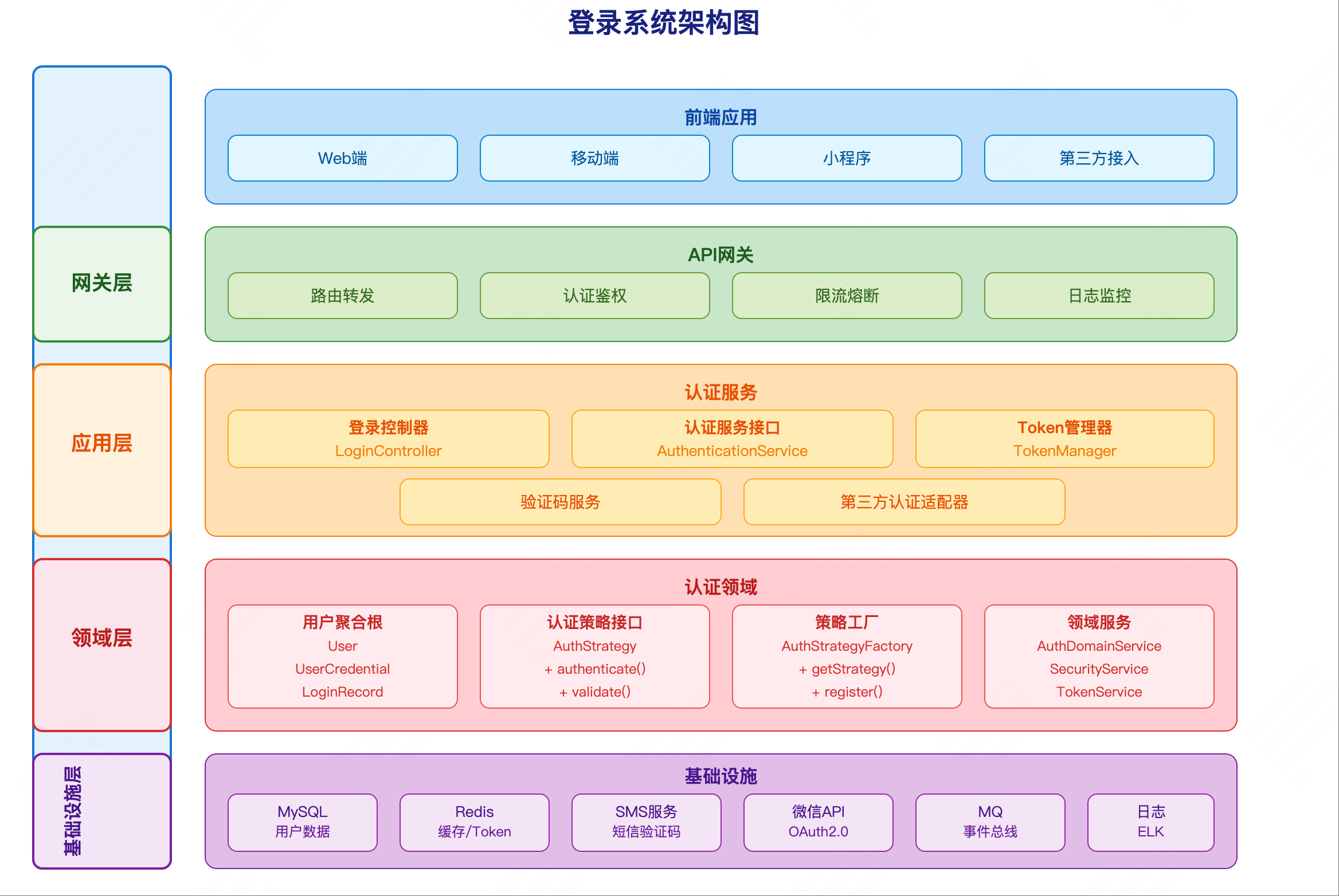
系统架构 在明确了业务领域和架构边界后,我们需要设计系统架构来支撑这些业务能力。
微服务分层架构 基于DDD的分层架构,记账微服务的系统架构如下:
网关层(GateWay Layer)
应用服务层(Application Layer)
账本应用服务(LedgerCommandApplicationService)
记录应用服务(TransactionStatementCommandApplicationService)
分类应用服务(CategoryCommandApplicationService)
通知应用服务(NotificationService)
领域层(Domain Layer)
账本聚合(Leger Aggregate)
记录聚合(TransactionStatement Aggregate)
分类聚合(Category Aggregate)
领域服务
领域事件
基础设施层(Infrastructure Layer)
数据存储设计 基于领域模型,我们设计了以下数据表结构:
ledger : 账本表ledger_budget : 账本预算表leger_members : 账本成员表(支持共享账本)invitation : 邀请码表invitation_usage : 邀请码使用表transaction_statement : 记录表sys_category : 系统分类表user_category : 用户分类表
这样的设计既能保证数据一致性,又能支撑高并发的业务场景。
详细设计 经过上面的架构设计以后,我们明确了下面几点:
明确了记账微服务的三个核心领域
明确了各领域的责任边界和交互关系
明确了系统的技术架构和存储设计
接下来,我们需要进行详细设计,明确具体的实现方案。
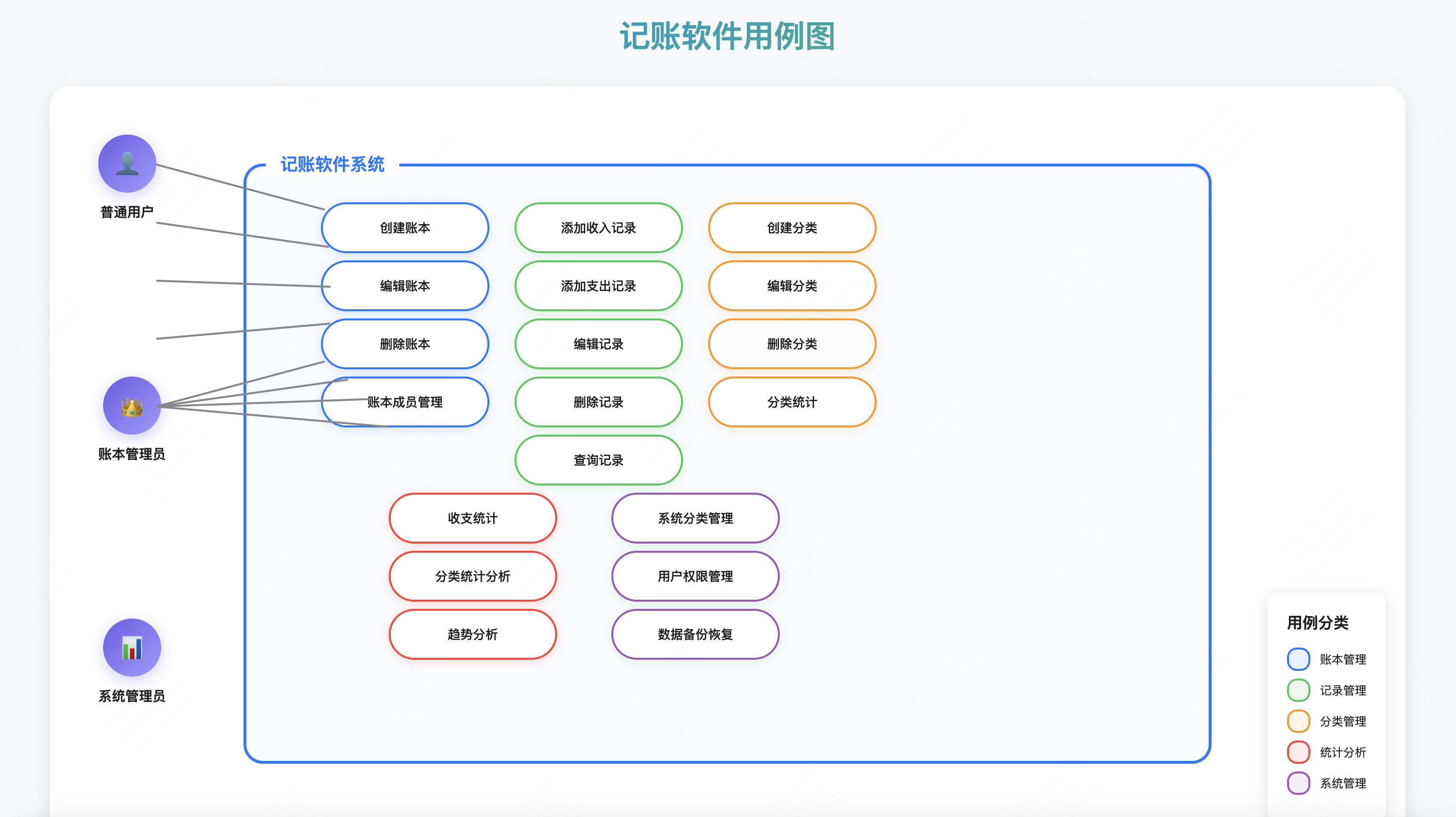
用例设计 我们通过用例图来理解记账微服务的核心功能。
主要用例:
账本管理
记录管理
添加收入记录
添加支出记录
编辑记录
删除记录
查询记录
分类管理
统计分析
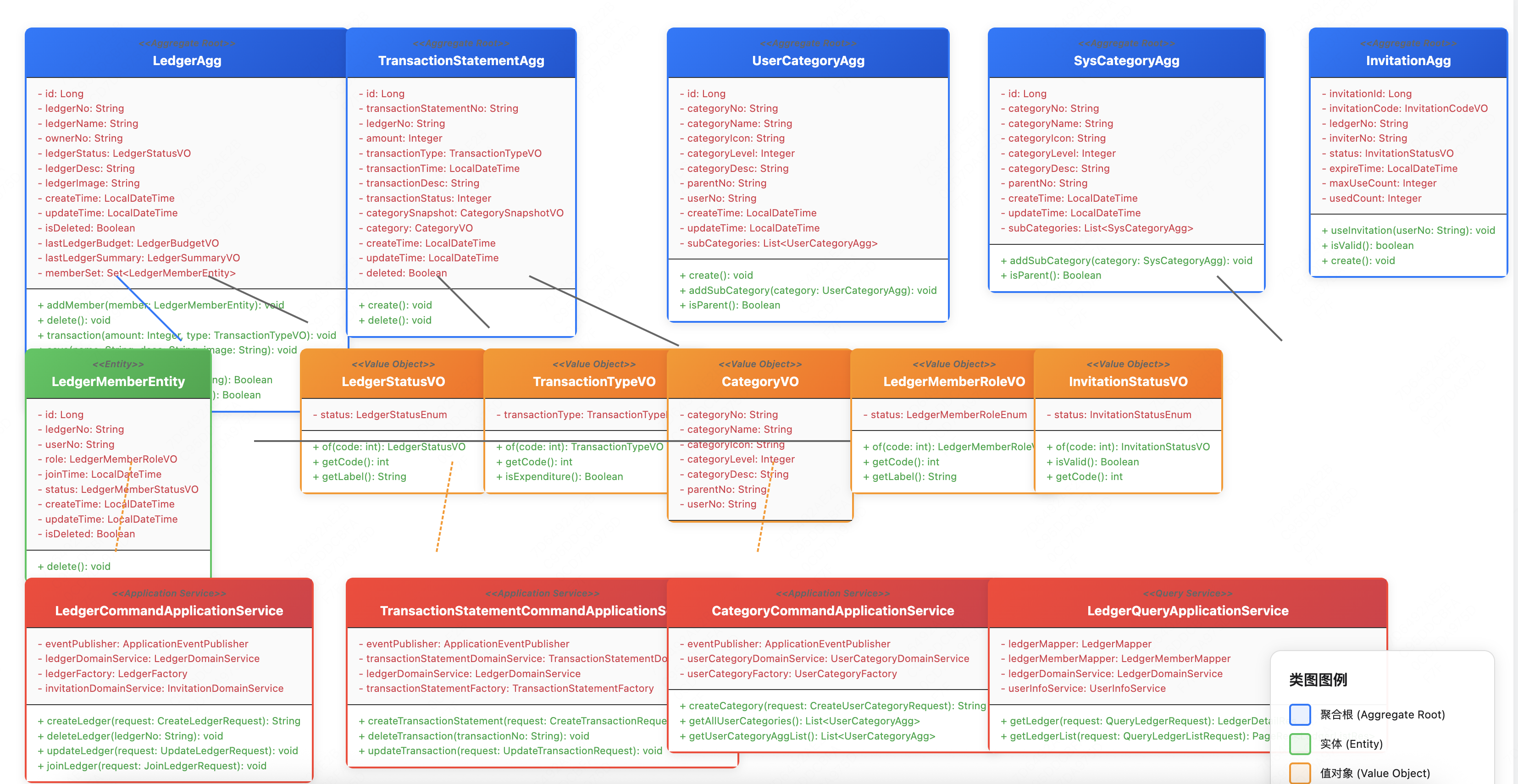
领域模型UML设计 基于DDD的领域建模,我们设计了以下核心领域模型:
设计亮点:
聚合根设计 :以AccountBook为聚合根,管理所有相关的Record值对象设计 :Money、RecordType等作为值对象,封装业务规则领域服务 :处理复杂的业务逻辑,如统计、校验等仓储模式 :抽象数据访问,解耦领域和基础设施
架构优势:
高内聚低耦合:各领域职责清晰
易于测试:领域逻辑独立于基础设施
易于扩展:新增功能不影响现有代码
符合业务语言:代码结构反映业务概念
开发 当设计完成以后就可以进入开发阶段了。这里给出记账微服务的核心代码实现。
接口层(Interface Layer) LedgerController - 账本管理控制器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 @RestController @RequestMapping("/ledger") public class LedgerController { @Resource private LedgerCommandApplicationService ledgerCommandApplicationService; @Resource private LedgerQueryApplicationService ledgerQueryApplicationService; @PostMapping("/create") public Result<String> createLedger (@RequestBody CreateLedgerRequest request) { String ledgerNo = ledgerCommandApplicationService.createLedger(request); return Result.success(ledgerNo); } @PostMapping("/update") public Result<String> updateLedger (@RequestBody UpdateLedgerRequest request) { ledgerCommandApplicationService.updateLedger(request); return Result.success(); } @DeleteMapping() public Result<String> deleteLedger (@RequestBody DeleteLedgerRequest request) { ledgerCommandApplicationService.deleteLedger(request.getLedgerNo()); return Result.success(); } @GetMapping("/list") public Result<PageRes<LedgerListRes>> getLedgerList (QueryLedgerListRequest request) { return Result.success(ledgerQueryApplicationService.getLedgerList(request)); } @GetMapping("/detail") public Result<LedgerDetailRes> getLedgerDetail (QueryLedgerRequest request) { return Result.success(ledgerQueryApplicationService.getLedger(request)); } @PostMapping("/update/budget") public Result<String> updateLedgerBudget (@RequestBody UpdateLedgerBudgetRequest request) { ledgerCommandApplicationService.updateLedgerBudget(request); return Result.success(); } @PostMapping("/join") public Result<String> joinLedger (@RequestBody JoinLedgerRequest request) { ledgerCommandApplicationService.joinLedger(request); return Result.success(); } @GetMapping("/memberList") public Result<List<LedgerMemberListRes>> memberList (QueryLedgerMemberListRequest request) { List<LedgerMemberListRes> memberList = ledgerQueryApplicationService.getMemberList(request); return Result.success(memberList); } }
应用服务层(Application Layer) 整体采用CQRS来实现,所以应用服务分成两种,分别是增删改的command应用服务和只负责查询的query应用服务LedgerCommandApplicationService - 账本command应用服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 @Service @Slf4j public class LedgerCommandApplicationService { @Resource private ApplicationEventPublisher eventPublisher; @Resource private LedgerDomainService ledgerDomainService; @Resource private LedgerFactory ledgerFactory; @Resource private InvitationDomainService invitationDomainService; public void deleteLedger (String ledgerNo) { LedgerAgg ledgerAgg = ledgerDomainService.findByNo(ledgerNo); if (ledgerAgg == null ) { throw new AggNotExistsException (ResultCode.LEDGER_NOT_FOUND); } ledgerAgg.delete(); ledgerDomainService.save(ledgerAgg); } public String createLedger (CreateLedgerRequest request) { String userNo = UserContextHolder.getCurrentUserNo(); LedgerAgg ledger = ledgerDomainService.findByNameInUser(request.getLedgerName(), userNo); if (ledger != null ) { throw new AggNotExistsException (ResultCode.LEDGER_ALREADY_EXISTS); } LedgerAgg ledgerAgg = ledgerFactory.createLedgerAgg(request.getLedgerName(), userNo, request.getLedgerDesc(), request.getLedgerImage()); ledgerAgg.create(); ledgerDomainService.save(ledgerAgg); List<DomainEvent> domainEventList = ledgerAgg.getDomainEvents(); domainEventList.forEach(event -> eventPublisher.publishEvent(event)); return ledgerAgg.getLedgerNo(); } public void updateLedger (UpdateLedgerRequest request) { LedgerAgg ledgerAgg = ledgerDomainService.findByNo(request.getLedgerNo()); if (ledgerAgg == null ) { throw new AggNotExistsException (ResultCode.LEDGER_NOT_FOUND); } ledgerAgg.save(request.getLedgerName(), request.getLedgerDesc(), request.getLedgerImage()); ledgerDomainService.save(ledgerAgg); List<DomainEvent> domainEventList = ledgerAgg.getDomainEvents(); eventPublisher.publishEvent(domainEventList); } public void updateLedgerBudget (UpdateLedgerBudgetRequest request) { LedgerAgg ledgerAgg = ledgerDomainService.findByNo(request.getLedgerNo()); if (ledgerAgg == null ) { throw new AggNotExistsException (ResultCode.LEDGER_NOT_FOUND); } LedgerBudgetVO ledgerBudget = ledgerFactory.createLedgerBudget(request.getLedgerNo(), request.getBudgetAmount(), request.getBudgetDate()); ledgerAgg.updateBudget(ledgerBudget); ledgerDomainService.save(ledgerAgg); List<DomainEvent> domainEventList = ledgerAgg.getDomainEvents(); eventPublisher.publishEvent(domainEventList); } public void joinLedger (JoinLedgerRequest request) { String userNo = UserContextHolder.getCurrentUserNo(); invitationDomainService.useInvitationCode(request.getInvitationCode(), userNo); InvitationAgg invitationAgg = invitationDomainService.loadByCode( new InvitationCodeVO (request.getInvitationCode())); LedgerAgg ledgerAgg = ledgerDomainService.findByNo(invitationAgg.getLedgerNo()); LedgerMemberEntity ledgerMember = ledgerFactory.createLedgerMember( ledgerAgg.getLedgerNo(), userNo, LedgerMemberRoleVO.MEMBER); ledgerAgg.addMember(ledgerMember); ledgerDomainService.save(ledgerAgg); List<DomainEvent> domainEventList = ledgerAgg.getDomainEvents(); eventPublisher.publishEvent(domainEventList); } }
LedgerQueryApplicationService - 账本query应用服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 @Service @Slf4j public class LedgerQueryApplicationService { @Resource private LedgerMapper ledgerMapper; @Resource private LedgerMemberMapper ledgerMemberMapper; @Resource private LedgerDomainService ledgerDomainService; @Resource private UserInfoService userInfoService; private List<LedgerListRes> convertToLedgerListResList (List<LedgerMemberPO> memberList, Map<String, LedgerPO> ledgerMap) { if (CollectionUtils.isEmpty(memberList)) { return Collections.emptyList(); } return memberList.stream().map(member -> {return convertToLedgerListRes(member, ledgerMap.get(member.getLedgerNo()));}).filter(Objects::nonNull).collect(Collectors.toList()); } private LedgerListRes convertToLedgerListRes (LedgerMemberPO memberPO, LedgerPO ledgerPO) { if (memberPO == null || ledgerPO == null ) { return null ; } LedgerListRes res = new LedgerListRes (); res.setLedgerName(ledgerPO.getLedgerName()); res.setLedgerImage(ledgerPO.getLedgerImage()); res.setLedgerNo(ledgerPO.getLedgerNo()); res.setLedgerDesc(ledgerPO.getLedgerDesc()); res.setLedgerStatus(ledgerPO.getLedgerStatus()); res.setCreateTime(LocalDateTimeUtil.format(ledgerPO.getCreateTime())); res.setUpdateTime(LocalDateTimeUtil.format(ledgerPO.getUpdateTime())); res.setRole(LedgerMemberRoleVO.of(memberPO.getRole()).getLabel()); res.setJoinTime(LocalDateTimeUtil.format(memberPO.getJoinTime())); return res; } public LedgerDetailRes getLedger (QueryLedgerRequest request) { String userNo = UserContextHolder.getCurrentUserNo(); LedgerAgg ledgerAgg = ledgerDomainService.findByNo(request.getLedgerNo()); if (ledgerAgg == null ) { return null ; } if (!ledgerAgg.hasViewPermission(userNo)) { return null ; } return convertToLedgerRes(ledgerAgg); } private LedgerDetailRes convertToLedgerRes (LedgerAgg ledgerAgg) { LedgerDetailRes res = new LedgerDetailRes (); res.setLedgerNo(ledgerAgg.getLedgerNo()); res.setLedgerName(ledgerAgg.getLedgerName()); res.setLedgerDesc(ledgerAgg.getLedgerDesc()); res.setLedgerStatus(ledgerAgg.getLedgerStatus().getLabel()); res.setLedgerBudget(buildLedgerBudget(ledgerAgg.getLastLedgerBudget())); res.setLedgerSummary(buildLedgerSummary(ledgerAgg.getLastLedgerSummary())); return res; } private LedgerSummaryRes buildLedgerSummary (LedgerSummaryVO summaryVO) { LedgerSummaryRes res = new LedgerSummaryRes (); res.setIncome(summaryVO.getIncome()); res.setExpense(summaryVO.getExpense()); res.setRemained(summaryVO.getRemained()); return res; } private LedgerBudgetRes buildLedgerBudget (LedgerBudgetVO budgetPO) { LedgerBudgetRes res = new LedgerBudgetRes (); res.setAmount(MoneyUtil.fen2Yuan(budgetPO.getBudgetAmount())); res.setUsed(MoneyUtil.fen2Yuan(budgetPO.getUsedAmount())); res.setRemained(MoneyUtil.fen2Yuan(budgetPO.getRemainedAmount())); res.setBudgetDate(LocalDateTimeUtil.format(budgetPO.getBudgetDate())); return res; } public PageRes<LedgerListRes> getLedgerList (QueryLedgerListRequest request) { String userNo = UserContextHolder.getCurrentUserNo(); LambdaQueryWrapper<LedgerMemberPO> wrapper1 = new LambdaQueryWrapper <>(); wrapper1.eq(LedgerMemberPO::getUserNo, userNo) .eq(LedgerMemberPO::getStatus, LedgerMemberStatusVO.NORMAL.getCode()) .eq(LedgerMemberPO::getIsDeleted, false ) .orderByDesc(LedgerMemberPO::getJoinTime); Page<LedgerMemberPO> pageList = ledgerMemberMapper.selectPage(Page.of(request.getPage(), request.getSize()), wrapper1); if (pageList.getTotal() == 0 ) { PageRes<LedgerListRes> pageRes = new PageRes <>(); pageRes.setPageNum(pageList.getCurrent()); pageRes.setPageSize(pageList.getSize()); pageRes.setTotal(pageList.getTotal()); pageRes.setList(Collections.emptyList()); return pageRes; } List<String> ledgerNoList = pageList.getRecords().stream() .map(LedgerMemberPO::getLedgerNo).collect(Collectors.toList()); LambdaQueryWrapper<LedgerPO> wrapper = new LambdaQueryWrapper <>(); wrapper.in(LedgerPO::getLedgerNo, ledgerNoList) .eq(LedgerPO::getIsDeleted, false ); List<LedgerPO> ledgerList = ledgerMapper.selectList(wrapper); Map<String, LedgerPO> ledgerMap = ledgerList.stream() .collect(Collectors.toMap(LedgerPO::getLedgerNo, Function.identity())); PageRes<LedgerListRes> pageRes = new PageRes <>(); pageRes.setPageNum(pageList.getCurrent()); pageRes.setPageSize(pageList.getSize()); pageRes.setTotal(pageList.getTotal()); pageRes.setList(convertToLedgerListResList(pageList.getRecords(), ledgerMap)); return pageRes; } public List<LedgerMemberListRes> getMemberList (QueryLedgerMemberListRequest request) { LambdaQueryWrapper<LedgerMemberPO> wrapper = new LambdaQueryWrapper <>(); wrapper.eq(LedgerMemberPO::getLedgerNo, request.getLedgerNo()) .eq(LedgerMemberPO::getStatus, LedgerMemberStatusVO.NORMAL.getCode()) .eq(LedgerMemberPO::getIsDeleted, false ); List<LedgerMemberPO> memberList = ledgerMemberMapper.selectList(wrapper); if (CollectionUtils.isEmpty(memberList)) { return Collections.emptyList(); } String userNo = UserContextHolder.getCurrentUserNo(); if (memberList.stream().noneMatch(member -> member.getUserNo().equals(userNo))) { return Collections.emptyList(); } List<String> userNoList = memberList.stream() .map(LedgerMemberPO::getUserNo) .collect(Collectors.toList()); List<UserInfoBO> userBOList = userInfoService.batchQueryUserInfo(userNoList); Map<String, UserInfoBO> userBOMap = userBOList.stream() .collect(Collectors.toMap(UserInfoBO::getUserNo, Function.identity())); return memberList.stream() .map(member -> convertToMemberListRes(member, userBOMap.get(member.getUserNo()))) .collect(Collectors.toList()); } private LedgerMemberListRes convertToMemberListRes (LedgerMemberPO memberPO, UserInfoBO userBO) { LedgerMemberListRes res = new LedgerMemberListRes (); res.setUserNo(memberPO.getUserNo()); res.setRole(LedgerMemberRoleVO.of(memberPO.getRole()).getLabel()); res.setJoinTime(LocalDateTimeUtil.format(memberPO.getJoinTime())); if (userBO != null ) { res.setUsername(userBO.getUserName()); res.setAvatar(userBO.getUserAvatar()); } return res; } }
领域层(Domain Layer) LedgerAgg - 账本聚合根
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 @Data @Builder public class LedgerAgg extends AbstractAgg { private Long id; private String ledgerNo; private String ledgerName; private String ownerNo; private LedgerStatusVO ledgerStatus; private String ledgerDesc; private String ledgerImage; private LocalDateTime createTime; private LocalDateTime updateTime; private Boolean isDeleted; private LedgerBudgetVO lastLedgerBudget; private LedgerSummaryVO lastLedgerSummary; private Set<LedgerMemberEntity> memberSet; public void addMember (LedgerMemberEntity member) { if (memberSet == null ) { memberSet = new HashSet <>(); } memberSet.add(member); registerDomainEvent(new UserJoinedLedgerEvent (this )); } public void delete () { if (memberSet != null ) { memberSet.forEach(LedgerMemberEntity::delete); } if (lastLedgerBudget != null ) { lastLedgerBudget.delete(); } isDeleted = true ; registerDomainEvent(new LedgerDeletedEvent (this )); } public void deleteTransaction (Integer amount) { lastLedgerBudget.increase(amount); } public void transaction (Integer amount, TransactionTypeVO transactionType) { if (transactionType.isExpenditure()) { lastLedgerBudget.reduce(amount); } } public void save (String ledgerName, String ledgerDesc, String ledgerImage) { updateSelf(ledgerName, ledgerDesc, ledgerImage); registerDomainEvent(new LedgerUpdatedEvent (this )); } public void updateBudget (LedgerBudgetVO ledgerBudget) { lastLedgerBudget = ledgerBudget; } private void updateSelf (String ledgerName, String ledgerDesc, String ledgerImage) { this .ledgerName = ledgerName; this .ledgerDesc = ledgerDesc; this .ledgerImage = ledgerImage; } public void create () { ledgerStatus = LedgerStatusVO.NORMAL; createTime = LocalDateTime.now(); updateTime = createTime; registerDomainEvent(new LedgerCreatedEvent (this )); } public Boolean checkUserPermission (String userNo) { return ownerNo.equals(userNo); } public Boolean hasViewPermission (String userNo) { return memberSet.stream().anyMatch(member -> member.getUserNo().equals(userNo)); } }
TransactionStatementAgg - 记录聚合根
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Data @Builder public class TransactionStatementAgg extends AbstractAgg { private Long id; private String transactionStatementNo; private String ledgerNo; private Integer amount; private TransactionTypeVO transactionType; private LocalDateTime transactionTime; private String transactionDesc; private Integer transactionStatus; private CategorySnapshotVO categorySnapshot; private CategoryVO category; private LocalDateTime createTime; private LocalDateTime updateTime; private Boolean deleted; public void create () { LocalDateTime now = LocalDateTime.now(); this .setCreateTime(now); this .setUpdateTime(now); this .setTransactionTime(now); registerDomainEvent(new TransactionStatementCreatedEvent (this )); } public void delete () { deleted = true ; updateTime = LocalDateTime.now(); registerDomainEvent(new TransactionStatementCreatedEvent (this )); } }
Money - 金额值对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class Money { public static final Money ZERO = new Money (BigDecimal.ZERO); private final BigDecimal amount; private Money (BigDecimal amount) { if (amount == null ) { throw new IllegalArgumentException ("金额不能为空" ); } this .amount = amount.setScale(2 , RoundingMode.HALF_UP); } public static Money of (BigDecimal amount) { return new Money (amount); } public static Money of (double amount) { return new Money (BigDecimal.valueOf(amount)); } public Money add (Money other) { return new Money (this .amount.add(other.amount)); } public Money subtract (Money other) { return new Money (this .amount.subtract(other.amount)); } public boolean lessThanOrEqual (Money other) { return this .amount.compareTo(other.amount) <= 0 ; } @Override public boolean equals (Object obj) { if (this == obj) return true ; if (obj == null || getClass() != obj.getClass()) return false ; Money money = (Money) obj; return amount.equals(money.amount); } @Override public int hashCode () { return amount.hashCode(); } }
基础设施层(Infrastructure Layer) AccountBookRepositoryImpl - 账本仓储实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 @Repository public class LedgerRepositoryImpl implements LedgerRepository { @Resource private LedgerMapper ledgerMapper; @Resource private LedgerBudgetMapper ledgerBudgetMapper; @Resource private LedgerMemberMapper ledgerMemberMapper; @Resource private TransactionStatementMapper transactionStatementMapper; @Resource private LedgerFactory ledgerFactory; @Override @Transactional(rollbackFor = Exception.class) public void insert (LedgerAgg ledgerAgg) { LedgerPO ledgerPO = this .toPO(ledgerAgg); ledgerMapper.insert(ledgerPO); LedgerBudgetPO ledgerBudgetPO = toLedgerBudgetPO(ledgerAgg.getLastLedgerBudget()); ledgerBudgetMapper.insert(ledgerBudgetPO); saveMemberSet(ledgerAgg.getMemberSet()); } private void insertMember (Set<LedgerMemberEntity> memberSet) { LedgerMemberEntity memberEntity = memberSet.stream().findFirst().orElse(null ); if (memberEntity == null ) { return ; } ledgerMemberMapper.insert(toMemberPO(memberEntity)); } private LedgerPO toPO (LedgerAgg userAgg) { return LedgerPO.builder() .id(userAgg.getId()) .ledgerName(userAgg.getLedgerName()) .ledgerNo(userAgg.getLedgerNo()) .ledgerStatus(userAgg.getLedgerStatus().getCode()) .ownerNo(userAgg.getOwnerNo()) .ledgerDesc(userAgg.getLedgerDesc()) .ledgerImage(userAgg.getLedgerImage()) .isDeleted(userAgg.getIsDeleted()) .build(); } private LedgerBudgetPO toLedgerBudgetPO (LedgerBudgetVO ledgerBudgetVO) { return LedgerBudgetPO.builder() .id(ledgerBudgetVO.getId()) .ledgerNo(ledgerBudgetVO.getLedgerNo()) .budgetAmount(ledgerBudgetVO.getBudgetAmount()) .usedAmount(ledgerBudgetVO.getUsedAmount()) .remainedAmount(ledgerBudgetVO.getRemainedAmount()) .budgetDate(ledgerBudgetVO.getBudgetDate()) .isDeleted(ledgerBudgetVO.getIsDeleted()) .build(); } private LedgerMemberPO toMemberPO (LedgerMemberEntity memberEntity) { return LedgerMemberPO.builder() .id(memberEntity.getId()) .ledgerNo(memberEntity.getLedgerNo()) .userNo(memberEntity.getUserNo()) .role(memberEntity.getRole().getCode()) .joinTime(memberEntity.getJoinTime()) .status(memberEntity.getStatus().getCode()) .isDeleted(memberEntity.getIsDeleted()) .build(); } public LedgerAgg findByNameInUser (String name, String userNo) { LambdaQueryWrapper<LedgerPO> wrapper = new LambdaQueryWrapper <>(); wrapper.eq(LedgerPO::getLedgerName, name) .eq(LedgerPO::getOwnerNo, userNo); LedgerPO ledgerPO = ledgerMapper.selectOne(wrapper); if (ledgerPO == null ) { return null ; } return toEntity(ledgerPO, null , null , 0L , 0L ); } private LedgerAgg toEntity (LedgerPO ledgerPO, LedgerBudgetPO ledgerBudgetPO, List<LedgerMemberPO> memberList, Long income, Long expense) { LedgerAgg ledgerAgg = LedgerAgg.builder() .id(ledgerPO.getId()) .ledgerName(ledgerPO.getLedgerName()) .ledgerNo(ledgerPO.getLedgerNo()) .ledgerStatus(LedgerStatusVO.of(ledgerPO.getLedgerStatus())) .ownerNo(ledgerPO.getOwnerNo()) .ledgerDesc(ledgerPO.getLedgerDesc()) .ledgerImage(ledgerPO.getLedgerImage()) .createTime(ledgerPO.getCreateTime()) .updateTime(ledgerPO.getUpdateTime()) .build(); if (ledgerBudgetPO != null ) { LedgerBudgetVO ledgerBudgetVO = LedgerBudgetVO.builder() .ledgerNo(ledgerBudgetPO.getLedgerNo()) .budgetAmount(ledgerBudgetPO.getBudgetAmount()) .usedAmount(ledgerBudgetPO.getUsedAmount()) .remainedAmount(ledgerBudgetPO.getRemainedAmount()) .budgetDate(ledgerBudgetPO.getBudgetDate()) .createTime(ledgerBudgetPO.getCreateTime()) .updateTime(ledgerBudgetPO.getUpdateTime()) .build(); ledgerAgg.setLastLedgerBudget(ledgerBudgetVO); } if (!CollectionUtils.isEmpty(memberList)) { Set<LedgerMemberEntity> memberSet = new HashSet <>(); memberList.forEach(member -> { LedgerMemberEntity memberEntity = LedgerMemberEntity.builder() .id(member.getId()) .ledgerNo(member.getLedgerNo()) .userNo(member.getUserNo()) .joinTime(member.getJoinTime()) .role(LedgerMemberRoleVO.of(member.getRole())) .status(LedgerMemberStatusVO.of(member.getStatus())) .createTime(member.getCreateTime()) .updateTime(member.getUpdateTime()) .build(); memberSet.add(memberEntity); }); ledgerAgg.setMemberSet(memberSet); } LedgerSummaryVO ledgerSummaryVO = ledgerFactory.createLedgerSummary(income, expense); ledgerAgg.setLastLedgerSummary(ledgerSummaryVO); return ledgerAgg; } @Override public LedgerAgg load (String ledgerNo) { LambdaQueryWrapper<LedgerPO> wrapper = new LambdaQueryWrapper <>(); wrapper.eq(LedgerPO::getLedgerNo, ledgerNo) .last("limit 1" ); LedgerPO ledgerPO = ledgerMapper.selectOne(wrapper); if (ledgerPO == null ) { return null ; } LambdaQueryWrapper<LedgerBudgetPO> wrapperBudget = new LambdaQueryWrapper <>(); wrapperBudget.eq(LedgerBudgetPO::getLedgerNo, ledgerPO.getLedgerNo()) .orderByDesc(LedgerBudgetPO::getId) .last("limit 1" ); LedgerBudgetPO ledgerBudgetPO = ledgerBudgetMapper.selectOne(wrapperBudget); LambdaQueryWrapper<LedgerMemberPO> wrapperMember = new LambdaQueryWrapper <>(); wrapperMember.eq(LedgerMemberPO::getLedgerNo, ledgerPO.getLedgerNo()) .orderByDesc(LedgerMemberPO::getId) .last("limit 10" ); List<LedgerMemberPO> memberList = ledgerMemberMapper.selectList(wrapperMember); Long incomeAmount = transactionStatementMapper.getSummaryAmount(ledgerPO.getLedgerNo(), TransactionTypeVO.INCOME.getCode()); Long expenditureAmount = transactionStatementMapper.getSummaryAmount(ledgerPO.getLedgerNo(), TransactionTypeVO.EXPENDITURE.getCode()); return toEntity(ledgerPO, ledgerBudgetPO, memberList, incomeAmount, expenditureAmount); } @Override public void update (LedgerAgg ledgerAgg) { LedgerPO ledgerPO = this .toPO(ledgerAgg); ledgerMapper.updateById(ledgerPO); LedgerBudgetPO ledgerBudgetPO = toLedgerBudgetPO(ledgerAgg.getLastLedgerBudget()); LambdaQueryWrapper<LedgerBudgetPO> wrapper = new LambdaQueryWrapper <>(); wrapper.eq(LedgerBudgetPO::getLedgerNo, ledgerBudgetPO.getLedgerNo()) .eq(LedgerBudgetPO::getBudgetDate, LocalDateTimeUtil.format(ledgerBudgetPO.getBudgetDate(), LocalDateTimeUtil.DATE_FORMATTER_MONTH_ONE)); LedgerBudgetPO budget = ledgerBudgetMapper.selectOne(wrapper); if (budget == null ) { ledgerBudgetMapper.insert(ledgerBudgetPO); } else { ledgerBudgetPO.setId(budget.getId()); ledgerBudgetPO.setUsedAmount(budget.getUsedAmount()); ledgerBudgetPO.setRemainedAmount(ledgerBudgetPO.getBudgetAmount() - ledgerBudgetPO.getUsedAmount()); ledgerBudgetMapper.updateById(ledgerBudgetPO); } saveMemberSet(ledgerAgg.getMemberSet()); } private void saveMemberSet (Set<LedgerMemberEntity> memberSet) { if (CollectionUtils.isEmpty(memberSet)) { return ; } memberSet.forEach(member -> { if (member.getId() == null ) { ledgerMemberMapper.insert(toMemberPO(member)); } else { ledgerMemberMapper.updateById(toMemberPO(member)); } }); } public Boolean exists (String ledgerNo) { LambdaQueryWrapper<LedgerPO> wrapper = new LambdaQueryWrapper <>(); wrapper.eq(LedgerPO::getLedgerNo, ledgerNo); return ledgerMapper.exists(wrapper); } }
总结 本文重点在如何进行设计系统,部分代码如上所示,完整代码可私信领取。
我们从0-1,完整实现了一个可扩展的记账微服务设计,包括:
领域分析 :识别出账本、记录、分类三个核心领域架构设计 :基于DDD的分层架构,明确各层职责详细设计 :用例图和UML类图指导开发实现代码实现 :完整的四层架构代码示例
核心设计亮点:
领域驱动 :以业务为核心,代码结构反映业务概念聚合设计 :LedgerAgg作为聚合根,保证数据一致性值对象 :Money等值对象封装业务规则分层架构 :职责清晰,易于维护和扩展仓储模式 :抽象数据访问,解耦领域和基础设施
架构优势:
高内聚低耦合,各模块职责明确
易于单元测试,领域逻辑独立
支持后续功能扩展,如报表分析等
符合企业级开发规范
通过这个设计思路,我们可以继续实现其他微服务模块,构建完整的记账系统。
文末福利
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。