大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等!
愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路!
无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
关注我一起挣大钱!文末有惊喜哦!
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
MySQL零基础教程
本教程为零基础教程,零基础小白也可以直接学习,有基础的可以跳到后面的原理篇学习。
基础概念和SQL已经更新完成。
接下来是应用篇,应用篇的内容大致如下图所示。
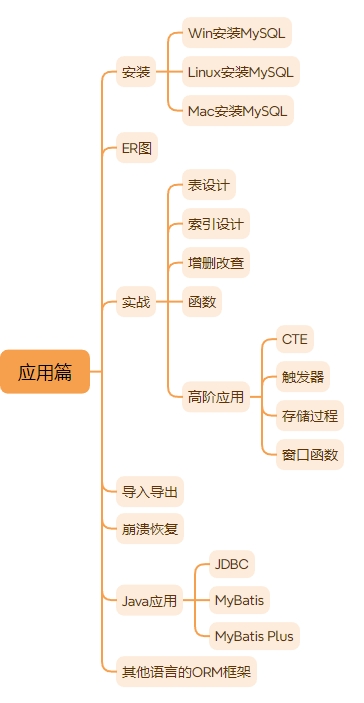
表设计
表设计可以聊的点其实是比较多的,这个也比较看具体的业务、流量等。
比如,某一个字段是否应该放在这张表里?一张表里应该有哪些字段?如何设计字段类型?
甚至于,如何设计字段的顺序?
这里很多人不知道的一个点在于,字段的顺序也会影响性能,至于为什么,这个就偏低层一些了,下面会讲到。
想要做表设计,那你首先需要知道表是什么,所以我们先来看看表到底是什么东西。
表是什么?
有的人会说,表就是Navicat上看到的一张表呗,还能是什么啊?
还有的人说,表就是一行一行数据组成的。
其实说的都对,但是这是逻辑上的表,也就是mysql给我们展现出来的表。
大家有没有想过,表的物理形式是什么,msyql如何将它转化成逻辑上的表方便我们查看呢?
接下来进行揭秘吧!
如何表示磁盘上文件的数据
数据库的数据最终以文件的形式放在磁盘中。通过文件读写将数据读写到文件中。文件有特定的格式,具体的内容有数据库进行解析然后展示在数据库中。这就是storage manager or storage engine。
比如MySQL数据库的存储引擎,常用的就是InnoDB存储引擎了,他就是负责干这个事情的。
storage manager负责文件的读写工作。所有的文件(不管是一个或者多个)以 page 的形式存储,管理多个 page 组成的集合。
一个page就是一个固定大小的数据块。page 可以保存任何东西,tupe, metadata, indexes, log等等。每个page有唯一的ID,是page ID。
有些page要求是独立的,自包含的(self-contained)。比如mysql的InnoDB。因为这样的话一个表的元数据和本身的数据内容在一起,如果发生问题的话,可以找回元数据和数据。如果元数据和数据在不同的page中,如果发生问题导致元数据的page丢失,那么数据则恢复不了了。
indirection layer记录page ID的相对位置,方便找到对应的偏移量。这样page目录就能找到对应的page。
不同的DBMS对于文件在磁盘上的存储方式不一样,有下面几种
- 堆存储
- 树存储
- 有序文件存储(ISAM)
- hashing文件存储
像MySQL数据库使用的就是堆存储的方式了,所以我们主要看一下什么是堆存储。
堆存储具有以下特点:
- 无序的,保存的顺序和存储的顺序无关。
- 需要读写page
- 遍历所有的page
- 需要元数据记录哪些是空闲的page,哪些是已经使用的page。
- 使用
page directory方式来记录文件位置。
page directory:说白了就是目录,记录了一些映射关系,在代码里面其实就是个Map。
- 存储page ID和所在位置的关系
- 存储page的空闲空间信息
大体结构如图所示: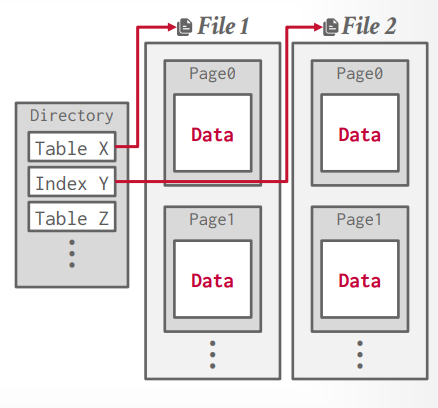
page header:每个page里面都有一段空间用来存储这个page的一些相关信息,这段空间就叫做page header。
- page 大小
- checksum 校验和
- DBMS版本信息
- 事务可见性
- 压缩信息
看到这里,其实你就明白了,我们在聊索引的时候,很多时候会说索引的叶子节点是一个page。不知道大家当时有没有疑问,这个page到底是什么?
在这里我就给你讲明白,这个page到底是个什么东西。
每个page里面除了包含page header以外,就是page data了。
这些page里面的数据就是我们能看到的一行行的数据。
我们通常称这样按照一行行数据来存储的数据库叫做行式数据库。比如MySQL就是。
除此之外还有一些按照一列列数据存储的列式数据库。
数据表示
我们在做表设计的时候还会考虑到字段的类型,那么如何选择类型呢?
这些类型的底层存储有什么区别?
上面我们已经知道了一个page里面存储了一行行的数据。那么一行数据是多长呢?
这个一行数据的长度自然就是这一行数据所有字段长度的总和了。
字段的长度分为两种类型
- 固定长度的字段
- 可变长度的字段
固定长度的字段有下面这些:
- Int:整型,当然了这里也包括
TinyInt、SmallInt、BigInt等。不同长度的Int类型只是所占的字节数不一样而已。 - Char:字符型,Char类型就是个字符串,你创建的时候给了多长,就是一个多长的字符串。
- Decimal:定点小数,也是最常用的小数类型。虽然运算速度慢一些,但是精度高。Flout和Double虽然也是小数,运算速度快但是会有精度丢失的问题。
- Date:时间类型,包括
DateTime、Time等。固定长度用来存储时间。TimeStamp类型已经快要达到上限了,不要再使用了。
可变长度的字段有下面这些,他们的长度会存储在header里面:
- Varchar: 可变的字符串类型,存储时只占用实际需要的字节数,对比Char类型而言,更加节省空间。
- VarBinary: 可变长度的二进制字符串类型,类似于 VARCHAR,但存储的是二进制数据。
- Text:可变长度的长文本类型,存储时占用的字节数取决于实际内容。
- BLOB:可变长度的二进制数据类型,存储时占用的字节数取决于实际内容。
表设计中尤其要注意的几点:
不要去使用TimeStamp类型了,使用DateTime或者Bigint来存储时间。
其次,避免去使用Flout和Double类型,而是使用Decimal来存储小数,或者使用Int类型来存储。
避免使用大值存储,比如Text和blob类型,而是使用Varchar来代替。
通常说的大值(large values)也就是里面存储的内容过多。
比如我们有一个字段是Text类型,这个字段的数据非常大,占据了Page的一半,再加上其他的数据,那么我们一个Page里面只能存储一行数据了,Page里面剩下的空间就会浪费掉了。
对于这种情况,数据库的设计者也考虑到了,所以他们实际存储的是一个指针,这个指针指向另外一个Page页面。将这个字段的内容存储到另外一个单独的Page里面。这个单独的Page页面叫做Overflow Page。
虽然这样解决了上面的问题,但是也引入了新的复杂度,比如对于这个额外的Page页面的维护管理。
NULL存储,表设计中还有重要的一点处理就是NULL值,因此我们通常把字段设置为NOT NULL类型来避免NULL值。因为NULL值有如下问题:
- 行数据库通常是在Header里面增加bit map来判断是否是null
- 列数据库通常使用占位符来标识NULL
- 在每个属性前面增加bit来标识是否是NULL,这么做会破坏对齐,或增加存储空间,MySQL曾使用这个方法,后来抛弃了这个方法。
- NULL == NULL 是 NULL, NULL is NULL 是 true
page是什么样子的
上面我们讲完了一行数据是什么样子的,那么一个Page里面又是什么样子的呢?
一般想法,就是一行贴着一行直接存储,新的行数据直接在后面追加,但是对于可变数据长度很难管理。
- 记录page数,也就是page内部可插入的偏移量
- 一个一个tupe按照顺序存储

所以,page内部,通常不使用上面那种,而使用的是slotted pages
- slotted pages
- slot array 存储插槽信息的偏移量,通过他找到对应的行数据
- 支持可变长度的行数据
- 但是会产生一些碎片空间,因为太小,一行数据放不下。
- 压缩可以去除碎片空间,但是压缩的时候这个page就不能读写了。
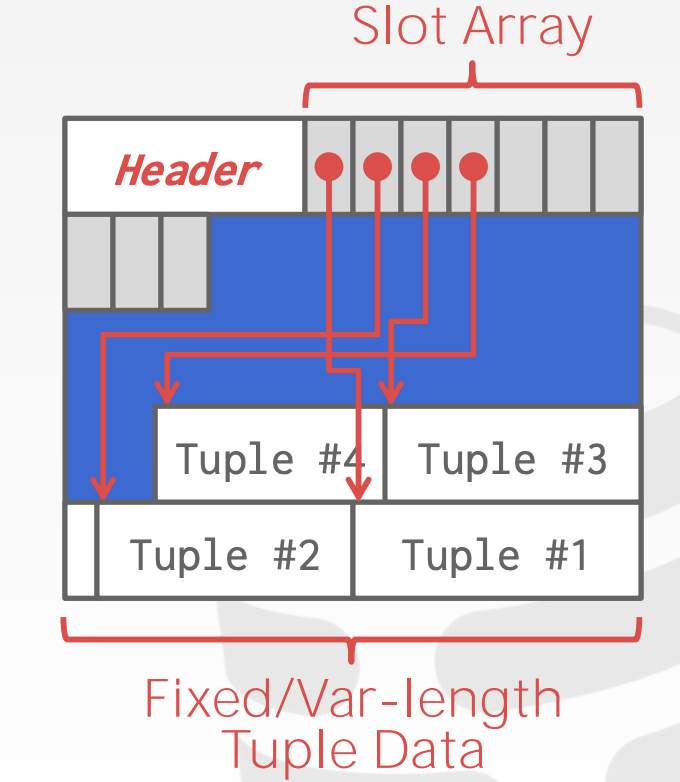
mysql innodb 压缩
innodb 在写入的时候可以不解压,但是读取的时候会先在buffer pool中解压在读取。因此Mysql innodb的压缩的好处是提升空间利用率,减少了磁盘IO,缺点是读取的时候需要解压,因此增加了这部分的时间和CPU功耗以及解压以后会占用更多的内存空间。
innodb 默认page 是 16KB,可以压缩到1/2/4/8KB。
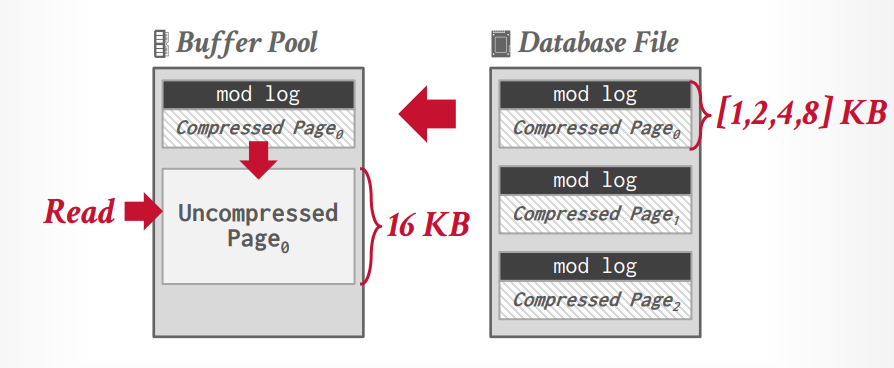
数据对齐
现代CPU是64位对齐,创建表以后,DBMS会自动的将数据进行对齐存储,不过,如果在创建表的时候考虑对齐,可以优化速度和存储空间。
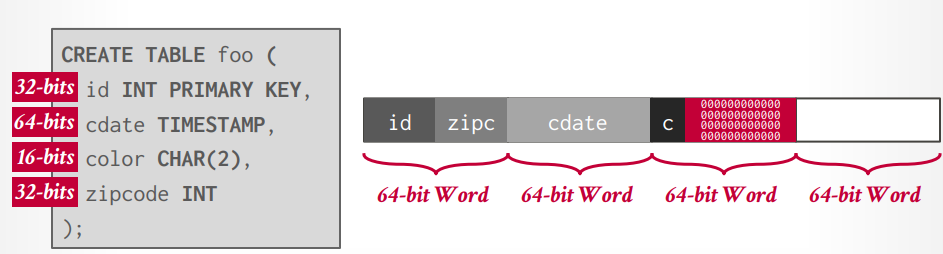
还记得我们上面说过的吗,字段的顺序也是会影响性能的,如果你的字段顺序能满足数据对齐的要求,那么就可以避免空间的浪费,同一个page里面就可以存储更多的行数据,也就意味着我们每次获取一个page的时候,能从磁盘拿到更多的数据,因此我们获取大量数据的时候,IO次数就会减少,从而起到提升性能的效果。
实战
表设计要考虑的其实是比较多的,相信你看完上面的内容,对于如何设计表,应该有了一些自己的方法论。
这里再讲一下实战中需要注意的事情吧。
再开始设计表之前,我们肯定要先分析需求,然后才能知道我们需要存储哪些数据。
比如,我们要做一个招聘网站,那么我们需要存储发布的职位信息。
职位信息都放到一个表里面吗?
职位信息其实还挺多的,不光是常见的职位名称、职位JD。还会涉及到比如职级信息、工资信息、面试轮次,是否支持视频面试、学历要求、学校要求、工作经历要求大厂等。
这里面有一个冷热数据的概念。
比如说,有一部分信息是经常要查询的,比如职位名称、学历要求、工作年限要求、工资、公司信息、招聘人头像、名称、标签等。
首先、这些数据肯定放在多个表里面的,比如招聘人头像、名称是用户表的数据、标签信息是标签表的数据、公司信息是公司表的数据。但是其中职位名称、学历要求、工作年限、工资是属于职位的基本信息。而且是在职位列表、IM聊天中的职位卡片、职位详情、职位浏览、职位收藏等多个维度高曝光的职位信息。
那么就代表这些职位信息属于热数据,会被经常一起查询。因此他们放到一个表里面是没有问题的。
剩下的职位信息我们可以分成两类。
- 在职位详情页面首屏展示的内容或者一些强依赖的内容,这些数据也可以和上面的放在一个表里面。
- 一些其他不经常查询的数据,这些数据可以放在另外一个表里面。
这样的话,每次查询热数据的时候从第一张职位信息表获取,查询到的page里面都是包含的有用的信息,就可以减少IO次数。
因此,我们可以设计两个表来存储职位信息。
- 职位信息表:存储职位的主要数据、热数据、提升查询速度。
- 职位扩展信息表:存储职位的次要数据、冷数据、只在需要的时候进行查询。
总结
授人以鱼不如授人以渔,相信经过上面的学习,你已经具备了一定的表设计的能力了。
这里讲的主要是表的设计,而不是整个数据的设计。因为还缺少了一些,比如索引该如何设计?
如何保证大量数据的查询?
其实对于MySQL来说上索引以后就可以查询百万级的数据了,但是对于非常要求速度和更高量级的数据而言。还可以使用一些其他的方法,比如使用列式数据库来进行查询。
这样的话可能还会涉及数据同步、数据清洗等等。
相信你学完我的整个系列以后、对于更高量级的数据设计也会有一定的经验的。
如果在面试中遇到类似的问题,你也可以游刃有余的回答面试官。
在学习的过程中,我们也要做到知其然也知其所以然。
文末福利
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
部分电子书如图所示。