大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等!
愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路!
无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
关注我一起挣大钱!文末有惊喜哦!
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
MySQL零基础教程
本教程为零基础教程,零基础小白也可以直接学习,有基础的可以跳到后面的原理篇学习。
基础概念和SQL已经更新完成。
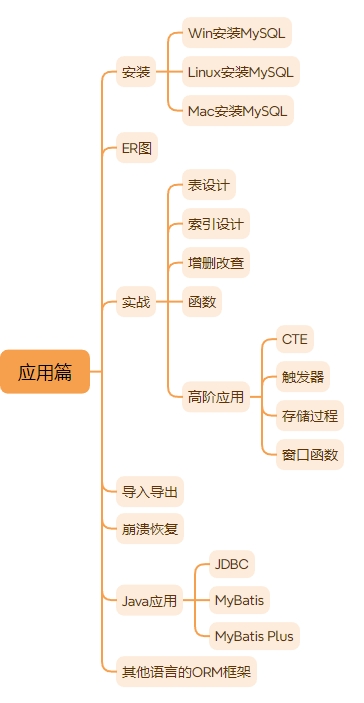
接下来是应用篇,应用篇的内容大致如下图所示。
索引设计
之前已经讲过表设计了,这次来说说索引设计。
索引设计也是一个比较重要的东西,可谓是重中之重。想要学好,很难。也是面试的常见问题。
在MySQL数据库中,索引是提升查询效率的核心工具。没有索引的查询,就像是在浩瀚的书海中翻书,效率低下。而良好的索引设计,则能帮助我们高效地找到我们需要的信息,避免无谓的资源浪费。因此,理解索引的原理、种类以及如何设计索引是每个开发者必须掌握的基础技能。
索引是什么?
索引是一种数据结构,它通过特定的方式排列数据,以便于快速查询。可以把索引想象成一本书的目录,通过目录可以快速找到你想要的章节,而不用从头到尾翻书。
在MySQL中,索引通常是通过B树或B+树等数据结构实现的,数据库查询引擎可以利用这些结构快速查找数据。
我们先看一下索引都有哪些类型,最常用的当然是b+树索引啦
- B+树索引:B+树是一种多路自平衡的树结构,所有的叶子节点都在同一层,并且叶子节点通过链表连接。它是MySQL中最常用的索引类型,支持范围查询、精确查找等操作。
- 哈希索引:哈希索引基于哈希表的原理,通过哈希函数对索引列进行计算,得到一个哈希值,哈希值对应的桶中存储数据的指针。
- 全文索引:全文索引是专门用于文本检索的索引结构,通常用于
TEXT类型的数据。MySQL会将文本字段中的每个单词进行索引,创建倒排索引,以提高文本搜索的效率。 - 空间索引: 空间索引是用于地理空间数据类型(如
POINT、LINESTRING、POLYGON)的索引结构,通常使用R树(或改进版的R+树)来存储和查询空间数据。 - 倒排索引:倒排索引主要用于文本搜索。它将文档中每个词的出现位置存储在一个列表中,从而支持高效的文本检索。
- 位图索引:位图索引使用位图(bitmap)来表示数据列中各个值的存在情况。例如,假设某一列有3个不同的值,可以用3个位来表示每个值的出现情况。
这些主要是根据索引结构来划分的。接下来详细看一下各个结构的优缺点,这样我们才能更好的进行选择。
B+树索引(B+ Tree Index)
结构:
- B+树是一种多路自平衡的树结构,所有的叶子节点都在同一层,并且叶子节点通过链表连接。
- 它是MySQL中最常用的索引类型,支持范围查询、精确查找等操作。
优点:
- 高效的范围查询:由于B+树是顺序存储的,支持范围查询,查询某个区间的数据时非常高效。
- 高效的精确查询:B+树通过逐层查找,可以快速定位到数据行。
- 支持排序:由于叶子节点按顺序排列,B+树非常适合用于
ORDER BY、GROUP BY等操作。 - 空间利用高:每个非叶子节点仅包含键,而不包含数据,可以节省存储空间。
缺点:
- 性能受页大小影响:B+树的性能与页的大小(每页存储的记录数)密切相关,过小的页会导致频繁的I/O操作,过大的页则会浪费内存。
- 写入性能较低:对于频繁插入、删除操作的场景,B+树索引的维护成本较高,可能导致性能下降。
应用场景:
- 最常用于主键索引、普通索引和唯一索引。尤其适用于需要进行范围查询、排序的场景。
特点:
b+ tree删除和插入的复杂度都是O(log n), b 是balance (平衡),推荐阅读paper:the ubiquitous B-treeb+ tree,保证每个节点都必须是半满的,对于存放在节点中的key数量来说,key数量至少为M/2 - 1个,M为树的高度,key的数量必须小于M - 1,如果当删除数据以后导致key数量小于M/2 - 1个,就会进行平衡,使他满足M/2 - 1个。M/2 - 1 ≤ key数量 ≤ M - 1
- 如果一个中间节点有k个key,那你就会有k+1个非空孩子节点,也就是k+1个指向下方节点的指针。每个节点的内容是一个
指针和一个key - 叶子节点之间有连接叶子节点的兄弟指针,这个想法来源于
b link tree。每个节点的内容是一个数据和一个key,数据可以是一个record id也可以是一个tuple - b+ tree 标准填充容量大概是67% - 69%,对于一个大小是8kb的page来说,如果高度为4,大约能记录
30 0000个键值对。 - b+ tree的节点大小,机械硬盘的大小最好在1M,ssd的大小在10KB
b tree 和 b+ tree 的区别
- b tree的中间节点也可以存数据,所以key是不重复的
- b+ tree的中间节点没有数据,所有数据都在叶子节点,所以key有可能既存在中间节点也存在叶子节点。会重复
- b tree的性能在并行处理上更差,因为修改以后需要向上传播也需要向下传播修改,这个时候两边都要增加锁
- b+ tree的性能更好,因为只修改叶子节点,所以只需要向上传播,只需要增加一个锁
b+ tree 插入
- 向下扫描,找到对应的叶子节点
- 如果可以插入就直接插入
- 如果不可以插入,那么从中间分开,变成两个叶子节点,并将中间的key传递给父节点,插入父节点。
- 如果父节点可以插入就直接插入并分出一个指针指向新的叶子节点
- 如果父节点不可以插入重复上述操作3
b+ tree 删除
- 向下扫描,找到对应的叶子节点,这个时候就会增加
latch,因为不知道需不需要合并,操作以后才会释放 - 如果可以删除就直接删除
- 如果删除后导致key数量 <
M/2 - 1,那么就会出发合并,因为不满足key数量啦 - 进行合并的时候删除这个key,然后先查看左右的兄弟节点,是否能直接把数据插入过来,如果可以的话就掠夺一个key过来,然后向上传播
- 如果不能掠夺,那么就合并到兄弟节点,然后向上传播。
b+ tree的查找
- 对于<a,b,c>,查找a=5 and b=3也是可以走索引的,但是hash索引就不行,有些数据库还支持b=3的搜索走索引,比如oracle和sql server
推荐书籍 Modern B-Tree Techniques
哈希索引(Hash Index)
结构:
- 哈希索引基于哈希表的原理,通过哈希函数对索引列进行计算,得到一个哈希值,哈希值对应的桶中存储数据的指针。
优点:
- 非常高效的等值查询:哈希索引的查找时间复杂度是O(1),因此对于精确查找(=)非常高效。
- 查询速度快:对于大量的数据,哈希索引可以快速找到对应的记录。
缺点:
- 不支持范围查询:由于哈希是通过哈希值计算的,哈希索引不支持范围查询(BETWEEN、>、<等)。
- 空间浪费:哈希表可能会出现哈希冲突,造成空间浪费和性能下降。
- 不支持排序:哈希索引无法用于ORDER BY、GROUP BY等排序操作。
应用场景:
- 适合用于精确查找,但不适合范围查询和排序操作。MySQL中内存表(MEMORY存储引擎)默认使用哈希索引。
哈希索引的应用场景有限,因此实际工作中使用较少。
哈希分为静态hash实现和动态hash实现。
静态hash
- liner probe hashing
- 如果要插入的位置有值了,就往下扫描,扫描到空的位置插入
- 删除的时候可以增加一个
墓碑标记,这样就知道这里是有数据的不是空,查找的时候就会继续往下扫描而不会是没找到 - 删除的时候还可以把后面的数据往前移动,但是这样有的数据就不再原来的位置了,就找不到了。因为只会往下扫描不会往上扫描
- robin hood hashing
- 记录
距离数,表示插入的位置和应该插入的位置的距离。从0开始。 - 插入的时候判断距离数,进行
劫富济贫,如果你向下扫描到距离数为3的地方插入,而在距离数为2的地方的数据x,x的距离数比你小,比如是0,1.那么你就占据这里,你插入距离数为2的地方,而将x插入你下面,x的距离数会+1. - 从整体来看,这个方法牺牲了插入的效率,将数据的距离数变得更加平均
- 记录
- cuckoo hashing
- 该方法使用两个或多个
hash table来记录数据,对A进行两次hash,得出两个hash table中的插入位置,随机选择一个进行插入 - 如果选择的插入位置已经有数据了,就选择另一个插入
- 如果两个都有数据了,就占据一个,然后对这个位置上之前的数据B再次hash选择其余位置。
- 该方法使用两个或多个
动态hash
- chained hashing
- 把所有相同hash的组成一个bucket链表,然后一直往后面增加
- java的hash table默认就是这样的
- extendible hashing
- 对 chained hashing 的扩展
- 有一个slot array,在slot array上有一个 counter, 如果counter = 2,代表看hash以后的数字的前两个bit,slot array就有4个位置,分别是00,01,10,11
- 每个slot指向一个bucket
- hash以后找到前两位对应的slot指向的bucket,将数据放进去,如果满了,放不下了就进行拆分
- 将slot array的counter扩容为3,看前3个bit,slot array变成了8个位置
- 只将这个满了的bucket拆分成2个,其余的不变,重新进行slot的映射
- 再次hash这个值,看前3个bit找到对应的slot,在找到对应的bucket,然后插入进去
- linear hashing
- 对 extendible hashing 的扩展
- 去掉了 conter,因为他每次加1,都会扩容一倍
- 增加了
split point,一开始指向0,然后每次overflow需要拆分的时候就拆分split point指向的那个bucket,然后slot array只扩容一个,这个时候出现第二个hash函数并将split point+1 - 查询的时候如果slot array的位置小于split point,就使用第二个hash函数,因为被拆分了
- 如果大于等于split point,就使用第一个hash函数
全文索引(Full-text Index)
结构:
- 全文索引是专门用于文本检索的索引结构,通常用于TEXT类型的数据。
- MySQL会将文本字段中的每个单词进行索引,创建倒排索引,以提高文本搜索的效率。
优点:
- 高效的全文搜索:可以用于模糊匹配、大规模文本数据的快速搜索,支持MATCH…AGAINST查询。
- 支持复杂查询:全文索引不仅支持简单的文本搜索,还可以支持布尔模式、自然语言模式等复杂的文本搜索。
缺点:
- 只适用于TEXT字段:全文索引主要用于大文本字段,如TEXT、LONGTEXT等。
- 更新开销大:对于频繁更新的表,全文索引的更新性能较差。
- 无法使用普通的LIKE查询:只能通过MATCH…AGAINST进行查询。
应用场景:
- 适用于需要进行全文搜索的场景,如文章搜索、日志分析等。
数据库全文索引适用于某个字段需要支持全文搜索。且不想进行大的改造。也没有太多的后续扩展需求。
如果对于全文搜索的要求比较高的话,还是推荐使用ES等搜索引擎进行改造的。
空间索引(Spatial Index)
结构:
- 空间索引是用于地理空间数据类型(如POINT、LINESTRING、POLYGON)的索引结构,通常使用R树(或改进版的R+树)来存储和查询空间数据。
优点:
- 高效的空间查询:能够高效地查询空间数据,支持ST_Within、ST_Intersects等空间查询操作。
- 支持多维数据:可以存储和查询多维数据,如经纬度、位置坐标等。
缺点:
- 空间数据类型限制:只适用于空间数据类型(如GEOMETRY、POINT等)。
- 查询性能受数据分布影响:空间索引的性能受空间数据的分布和密度影响,密集区域查询可能性能不佳。
应用场景:
- 适用于地理信息系统(GIS)等需要进行空间数据查询的应用场景,如地图服务、定位服务等。
倒排索引(Inverted Index)
结构:
- 倒排索引主要用于文本搜索。它将文档中每个词的出现位置存储在一个列表中,从而支持高效的文本检索。
优点:
- 高效的关键词检索:倒排索引非常适合处理大量文本数据,可以通过关键词快速查找相关文档。
- 支持复杂查询:可以支持基于关键词的复杂查询,如布尔查询、短语查询等。
缺点:
- 只适用于文本数据:倒排索引主要用于文本搜索,不能像B+树一样处理范围查询。
- 内存消耗大:倒排索引需要占用较大的内存空间,尤其是在数据量较大时。
应用场景:
- 主要应用于搜索引擎、内容管理系统、文档管理系统等需要高效检索文本内容的场景。
位图索引(Bitmap Index)
结构:
- 位图索引使用位图(bitmap)来表示数据列中各个值的存在情况。例如,假设某一列有3个不同的值,可以用3个位来表示每个值的出现情况。
优点:
- 适用于低基数数据:当字段的可能值较少(如性别、状态等字段)时,位图索引可以节省大量的存储空间。
- 查询效率高:位图索引非常适合多条件组合查询,尤其是当查询涉及多个低基数列时。
缺点:
- 适用范围有限:位图索引不适用于高基数的字段(如年龄、收入等),因为位图的大小随着基数增加会急剧增加,导致空间浪费。
- 更新成本高:每次更新时,需要修改位图,更新开销较大。
应用场景:
- 适用于低基数的字段,特别是用于多条件组合查询时。
索引的作用
- 加速查询:索引最主要的作用就是提高查询速度。通过索引,MySQL可以直接定位到目标数据行,而不是扫描整个表。
- 提高排序效率:在使用
ORDER BY或GROUP BY时,索引可以帮助MySQL高效地进行排序。 - 优化连接操作:当查询涉及多个表的连接时,索引可以加速连接的过程。
- 减少数据扫描量:在进行范围查询、匹配查询等操作时,索引可以大幅减少需要扫描的记录数。
索引的种类
上面已经介绍了索引的结构了,接下来看一下索引的类型,这些类型是逻辑上的。而结构则是物理上的。
这些索引类型下面都可以支持不同的索引结构,进行组合。
主键索引(Primary Key Index)
特点:主键索引是唯一的,且不允许NULL值。每个表只能有一个主键索引。
应用场景:主键索引用于表中唯一标识记录的字段。通常选择业务中最重要且唯一的字段作为主键,如id。
主键索引一般使用自增ID或者使用雪花算法,主要保证自增即可。
唯一索引(Unique Index)
- 特点:唯一索引保证索引列的值唯一,但允许NULL值。
- 应用场景:当某一列的值需要保证唯一性时,使用唯一索引。例如,邮箱、用户名等字段。
唯一索引的唯一约束是由数据库来保证的。
这样的好处是保证了数据的绝对唯一。并且加速了一些查询。比如手机号上有唯一索引,那么查询手机号=xxx这个条件的时候,找到一个就会停止继续扫描了。如果没有唯一索引,那么会继续扫描。
不好的地方在于减慢了插入、更新操作的速度。因为每次插入的时候数据库都需要判断唯一性。
具体使用就需要个人来权衡了。
普通索引(Index)
特点:普通索引没有唯一性要求。它主要用于提高查询效率。
应用场景:当我们需要查询某些列的数据时,且这些列没有唯一性要求,使用普通索引就能提高查询性能。
全文索引(Fulltext Index)
特点:全文索引适用于文本数据的快速搜索,尤其在TEXT类型的列中非常有效。
应用场景:当需要对大量文本数据进行搜索(如文章内容搜索)时,使用全文索引。
联合索引(Composite Index)
特点:联合索引是由多个列组成的索引。MySQL通过联合索引来优化涉及多个列的查询。
应用场景:当查询经常涉及多个列的条件时,使用联合索引可以提高查询效率。
如果涉及多个列的查询,可以不用设置多个索引,而是设置一个联合索引。
index merge 优化
index merge就是多个索引并发扫描,再将扫描结果合并
索引合并不适用于全文索引。
索引合并访问方法检索具有多个范围扫描的行,并将其结果合并为一个。此访问方法只合并单个表的索引扫描,而不合并多个表的扫描。合并可以产生其底层扫描的并集、交集或交集的并集。
可以使用索引合并的查询示例:
1 | SELECT * FROM tbl_name WHERE key1 = 10 OR key2 = 20; |
如果你的查询有一个带有深度AND/OR嵌套的复杂WHERE子句,并且MySQL没有选择最佳计划,请尝试使用以下恒等转换来分发术语:
1 | (x AND y) OR z => (x OR z) AND (y OR z) |
在EXPLAIN输出中,Index Merge方法在type列中显示为index_merge。在本例中,key列包含使用的索引列表,key_len包含这些索引的最长键部分列表。
索引合并访问方法有几种算法,它们显示在EXPLAIN输出的Extra字段中:
- intersect:对多个and条件生效
- union:对多个or条件生效
- sort_union:sort-union算法和union算法之间的区别在于,sort-union算法必须首先获取所有行的行ID,并在返回任何行之前对其进行排序。
索引合并的使用取决于optimizer_switch系统变量的index_merge、index_merge_intersection、index_merge_union和index_merge_sort_union标志的值。默认情况下,所有这些标志都是打开的。
如何设计索引?
设计索引不仅仅是为每个字段都加上索引,而是要根据查询的特点来合理选择索引。以下是一些常见的索引设计思路:
优先选择经常作为查询条件的字段
在WHERE子句中频繁使用的字段,通常应该创建索引。
经常用来连接(JOIN)的字段也应该加索引。
如果某个字段的值具有较高的唯一性(如id、手机号等),它是理想的索引候选。
合理选择索引的顺序
对于联合索引,列的顺序非常重要。MySQL通过最左前缀匹配原则来匹配索引,因此选择索引列的顺序时要考虑到查询的条件顺序。
例如,在查询WHERE name='John' AND age>25时,若创建了(name, age)的联合索引,那么查询会使用该索引。如果把age放在前面,查询可能无法利用该索引。
不要过度使用索引
索引虽然提高了查询效率,但也带来了一些负担。每次插入、更新、删除数据时,索引都会被更新。过多的索引会导致写操作的性能下降。因此,应当只为常用的查询字段建立索引,避免为每个字段都加索引。
避免在频繁更新的字段上创建索引
对于一些经常进行更新操作的字段,不建议创建索引,因为每次更新时都会重新计算索引,这会影响性能。
使用覆盖索引(Covering Index)
覆盖索引是一种特殊的索引,它能满足查询的所有需求,即查询字段完全在索引中,可以避免访问数据表的操作。通过合理设计索引列,尽量使查询能够通过索引完成。
例如,查询SELECT id, name FROM users WHERE age > 30时,可以创建一个包含id、name和age的联合索引,这样查询就可以直接通过索引返回结果。
索引优化案例
案例1:快速查找用户信息
假设有一个users表,结构如下:
1 | CREATE TABLE users ( |
如果我们经常需要查询某个email对应的用户,可以为email列添加一个唯一索引:
1 | CREATE UNIQUE INDEX idx_email ON users(email); |
这样,查询SELECT * FROM users WHERE email='test@example.com';时,就能迅速找到对应的记录。
优化多条件查询
假设我们有一个orders表,用于记录订单信息,查询经常会使用status和order_date这两个字段。如果我们创建一个联合索引:
1 | CREATE INDEX idx_status_date ON orders(status, order_date); |
这样,查询SELECT * FROM orders WHERE status='shipped' AND order_date='2025-06-30';时,MySQL会利用该索引提高查询效率。
案例3:避免全表扫描
假设我们有一个大表products,其中包含了成千上万的商品信息。如果我们需要根据name来查询某个商品,通过给name字段创建索引:
1 | CREATE INDEX idx_name ON products(name); |
查询时,MySQL就能通过该索引快速定位到商品,而不是扫描整个表。
总结
索引设计是MySQL数据库优化的核心技术之一。通过合理的索引设计,我们可以极大地提高查询性能,但过多或不恰当的索引设计可能带来负面影响。掌握索引的基本原理与设计策略,将帮助你在MySQL数据库的应用中更加高效地管理和优化数据查询。
文末福利
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
部分电子书如图所示。