大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等!
愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路!
无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
关注我一起挣大钱!文末有惊喜哦!
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
MySQL零基础教程
本教程为零基础教程,零基础小白也可以直接学习,有基础的可以跳到后面的原理篇学习。
基础概念和SQL已经更新完成。
接下来是应用篇,应用篇的内容大致如下图所示。
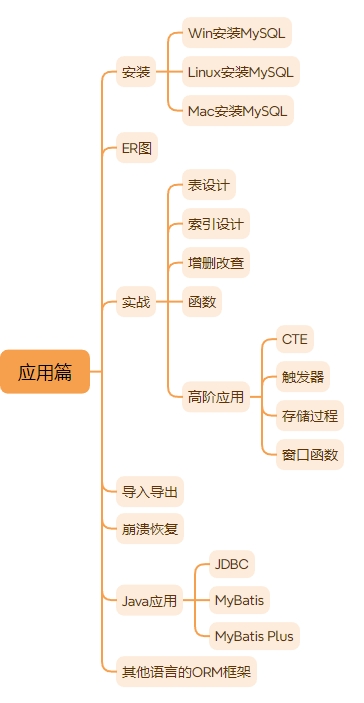
MySQL零基础教程导入导出
数据库的角色一般是用来做数据持久化的。既然我们把数据持久化到了磁盘中,那么当我们需要将数据迁移、转移、备份的时候,我们就需要将数据导出出来,并导入到其他的持久化地方。
导入的可能是另一个MySQL数据库,也可能是其他的数据库。
因此我们要学习如何对MySQL进行导入导出操作。
导出
MySQL提供了多种数据导出方式,每种方式都有其优缺点和适用场景。以下是常见的MySQL数据导出方式及其示例:
- 使用 mysqldump 工具
优点:
- 灵活性高:支持导出整个数据库、单个表或部分数据。
- 格式支持:可以导出为SQL文件,便于备份和迁移。
- 广泛使用:是MySQL官方提供的工具,支持多种选项和参数。
缺点:
- 速度较慢:对于大型数据库,导出速度可能较慢。
- 资源消耗:导出过程中可能会占用较多的系统资源。
示例:
1 | 导出整个数据库 |
使用场景:
小李今天接到领导要求:我们要进行数据库版本升级,从5.7升级到8.0。现在需要将数据从老数据库迁移到新数据库。因此需要导出整个数据库的数据到一个SQL文件里面,并导入到新数据库中。
小王接到领导要求:我们要进行数据库备份,每天备份一次,因此,需要导出数据库信息并留存。
- 使用 SQL 查询导出数据
优点:
- 简单直接:可以使用常规的SQL查询导出数据。
- 灵活性:可以导出特定的数据集,支持复杂查询条件。
缺点
- 格式有限:通常导出为文本格式,需后续处理。
- 适用性:不适合导出整个数据库或复杂结构。
示例:
1 | # 导出到CSV文件 |
使用场景:
小靳今天接到了一个任务,有一个运营需要导出一批用户行为数据做观察,因此使用这个命令直接导出为CSV文件,并交给运营。
- 使用 MySQL Workbench 导出
出来MySQL Workbench以外,还可以使用其他的图形化工具,比如Navicat等。
MySQL workbench是免费开源的,但是Navicat则需要花钱,因此我们使用MySQL workbench作为示例。
优点:
- 用户友好:图形化界面,易于操作。
- 功能丰富:支持导出为SQL文件、CSV等多种格式。
缺点
- 依赖图形界面:需要安装MySQL Workbench,适合小型数据集。
- 灵活性较低:对于复杂需求,可能需要手动调整。
示例
在MySQL Workbench中,选择数据库或表,右键点击选择“导出数据”。
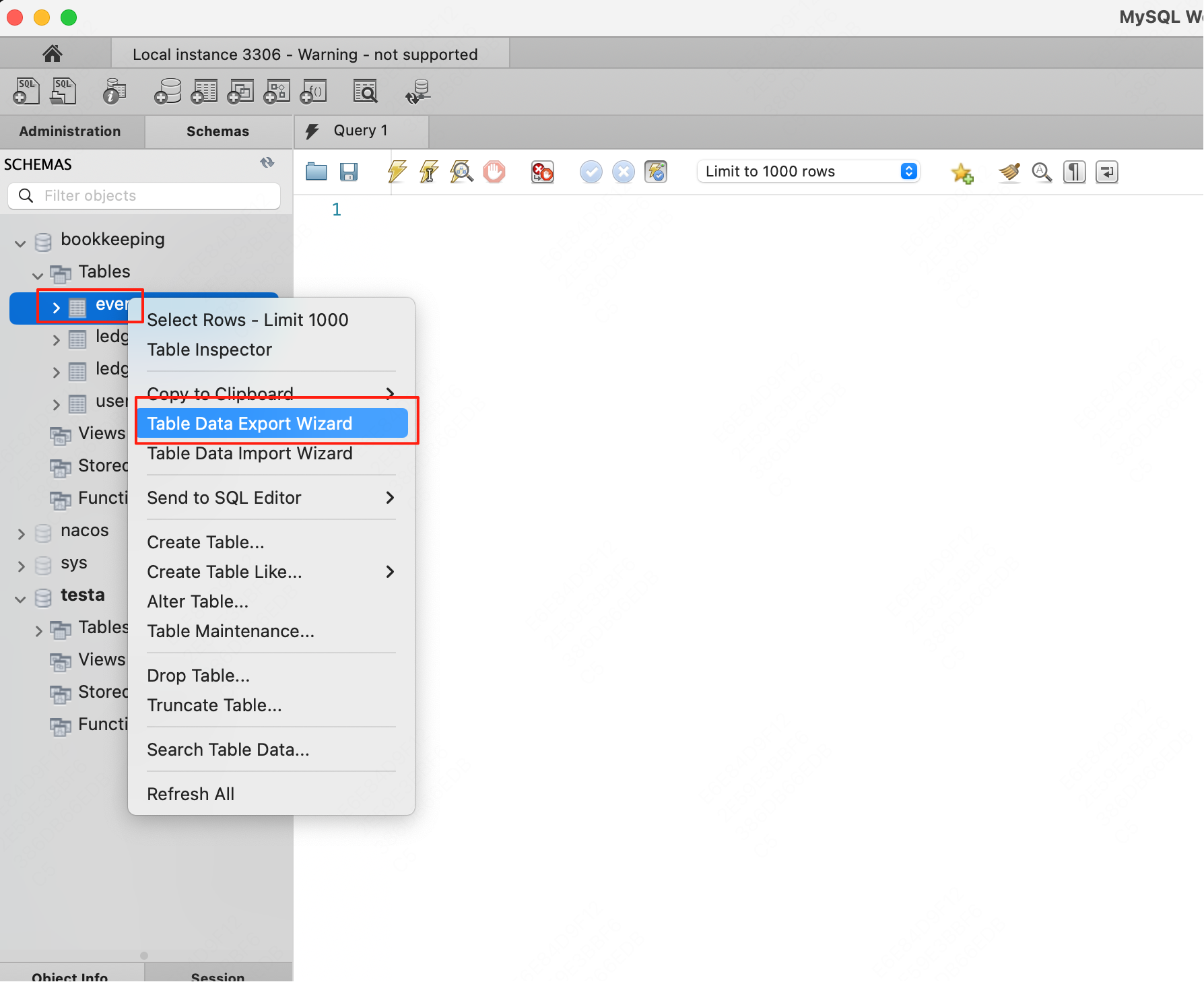
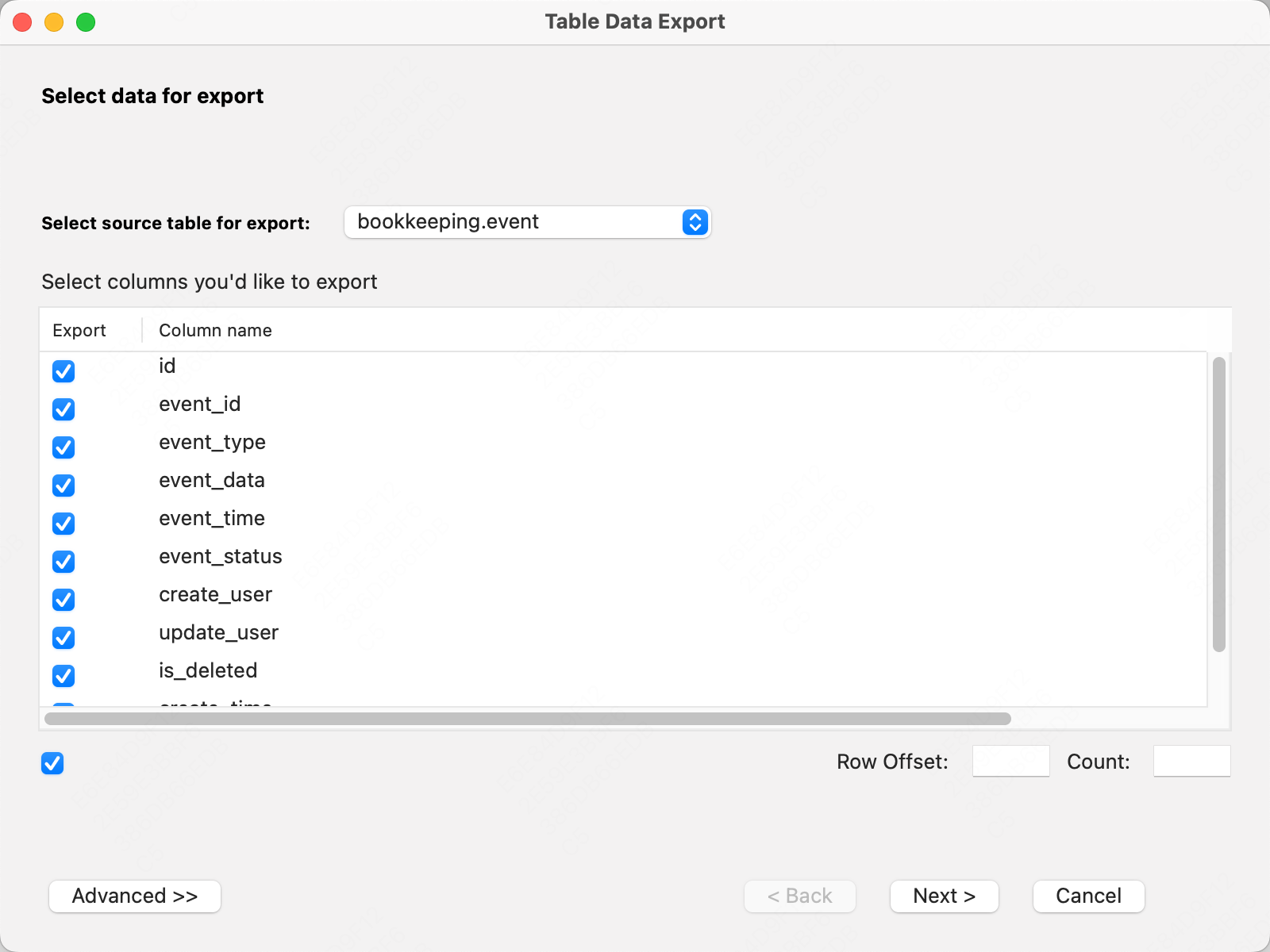
选择要导出的列,点击Next。
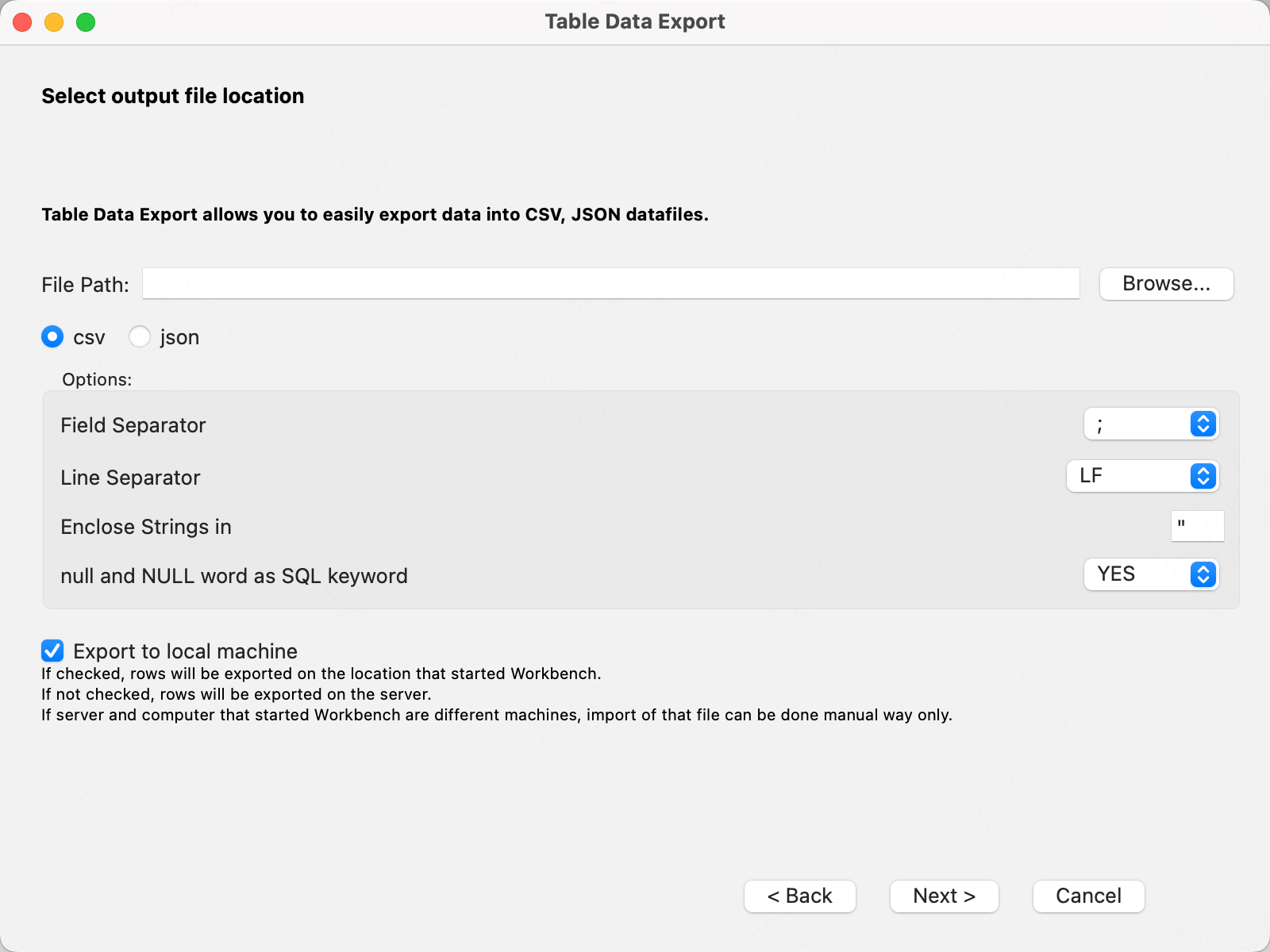
选择导出格式和路径,点击确认即可完成导出。
选择建议
根据具体需求选择合适的导出方式:
mysqldump:适合备份和迁移整个数据库或表。
SQL查询导出:适合导出特定数据集或简单数据。
MySQL Workbench:适合小型数据集的用户友好导出。
选择时需考虑数据规模、格式要求、系统资源和权限限制等因素。
导入
MySQL提供了多种数据导入方式,跟上面的导出对应,也有几种方式,每种方式都有其优缺点和适用场景。以下是常见的MySQL数据导入方式及其示例:
- 使用
mysqlimport工具
优点:
- 简单易用:命令行工具,适合批量导入。
- 格式支持:支持CSV、TSV等文本格式。
缺点:
- 权限要求:需要文件系统权限。
- 依赖命令行:需要在服务器上运行命令行工具。
1 | mysqlimport --local -u username -p database_name /path/to/file.csv |
- 使用
LOAD DATA INFILE
优点:
- 速度快:可以批量导入大量数据,性能较高。
- 灵活性:支持多种文件格式和字段选项。
缺点:
- 权限要求:需要文件系统权限和secure-file-priv设置。
- 格式限制:主要适用于文本文件(如CSV)。
1 | LOAD DATA INFILE '/path/to/file.csv' |
- 使用 MySQL Workbench 导入
优点
- 用户友好:图形化界面,易于操作。
- 功能丰富:支持导入CSV、SQL等多种格式。
缺点
- 依赖图形界面:需要安装MySQL Workbench,适合小型数据集。
- 灵活性较低:对于复杂需求,可能需要手动调整。
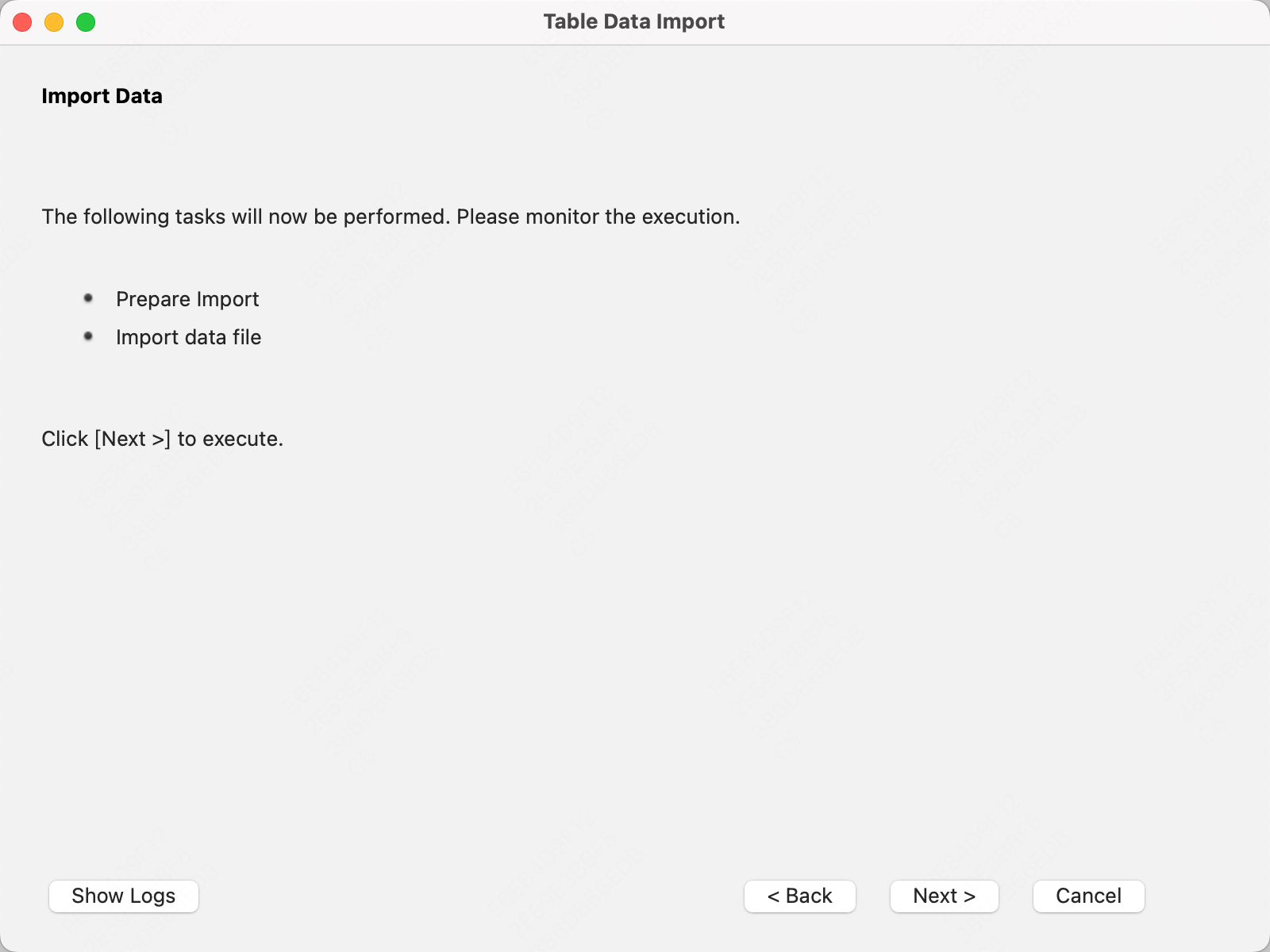
在MySQL Workbench中,选择数据库或表,右键点击选择“导入数据”。
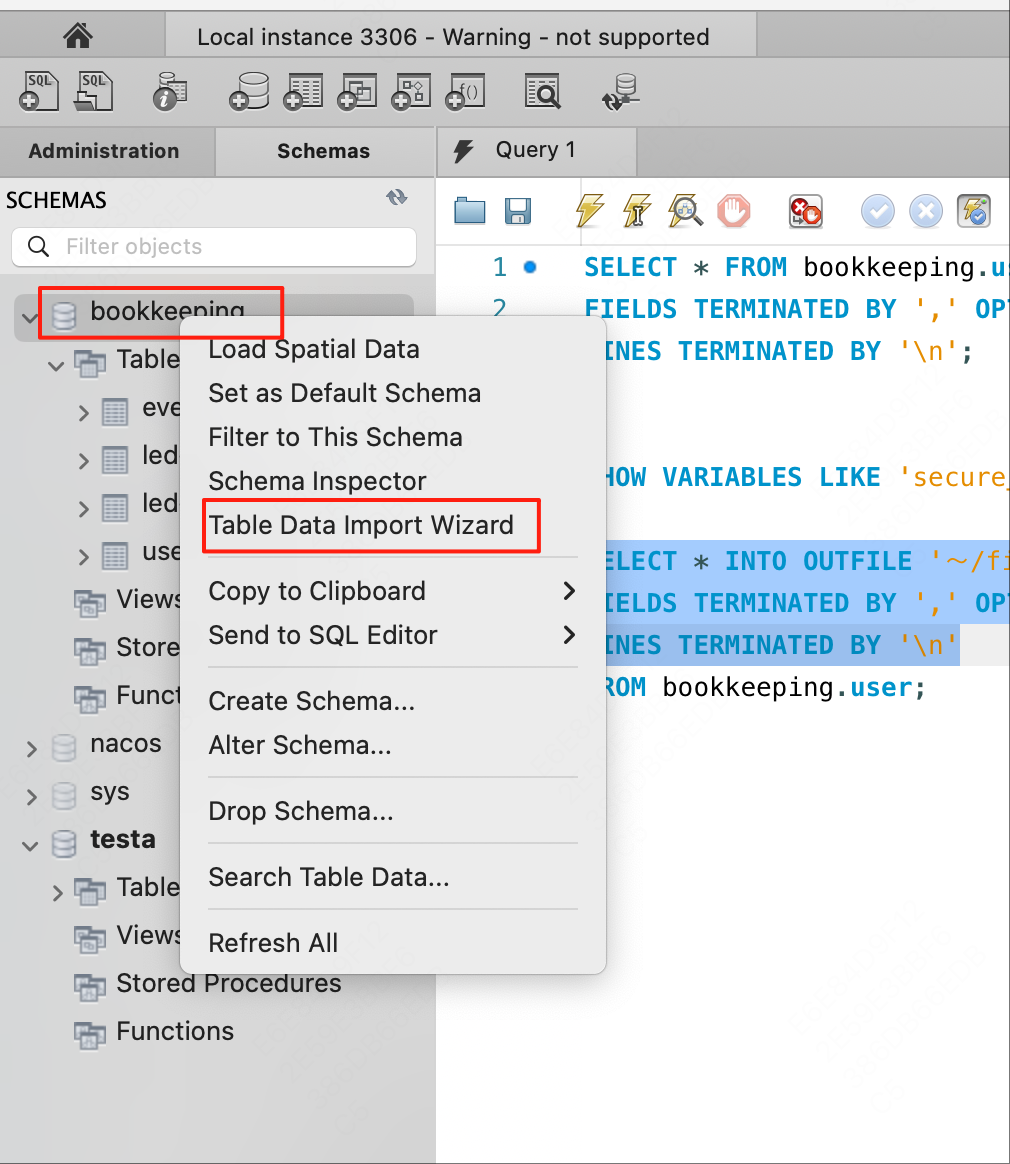
选择要导入的文件,点击Next
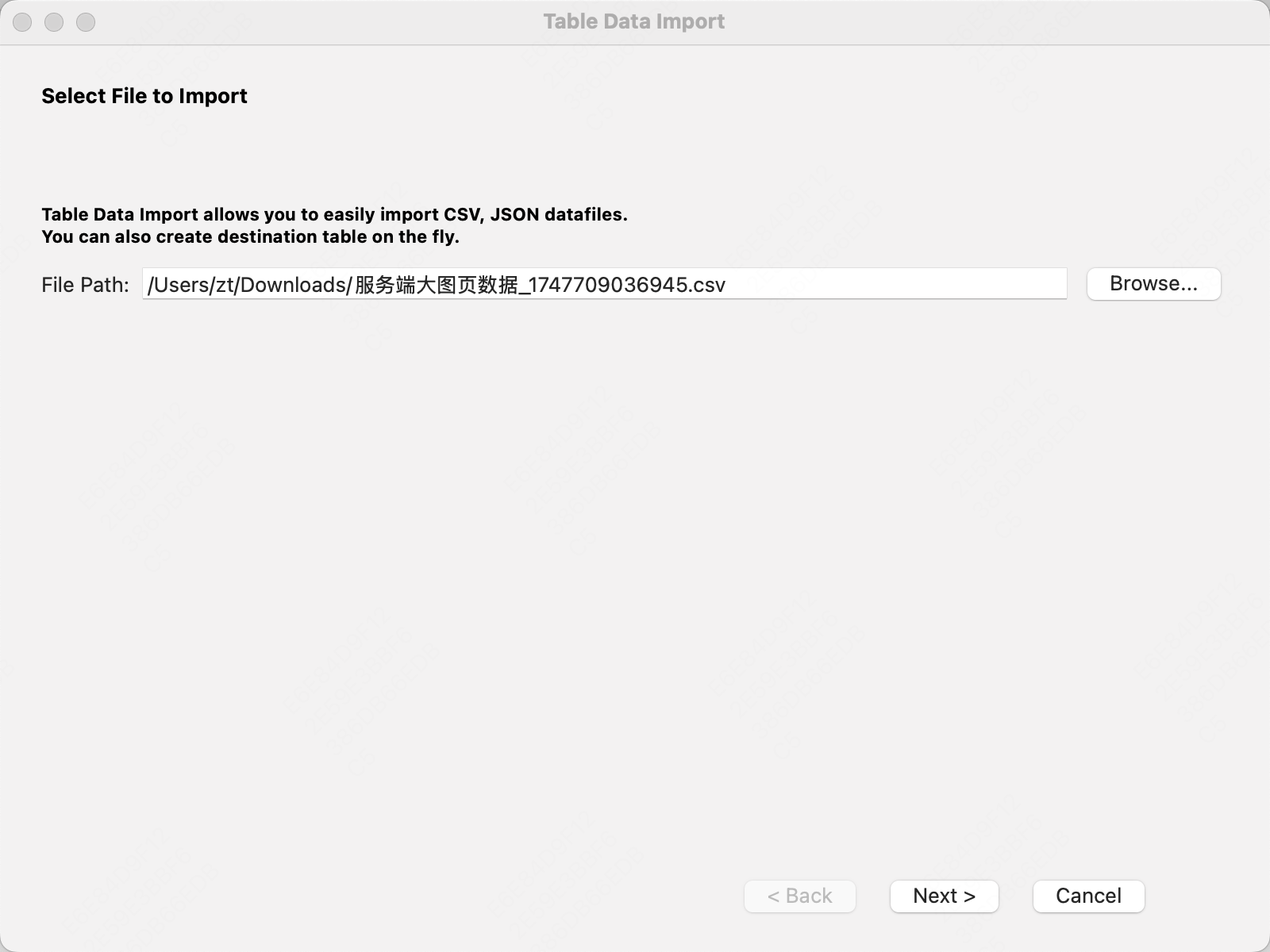
选择现有的数据表,还是创建新的数据表
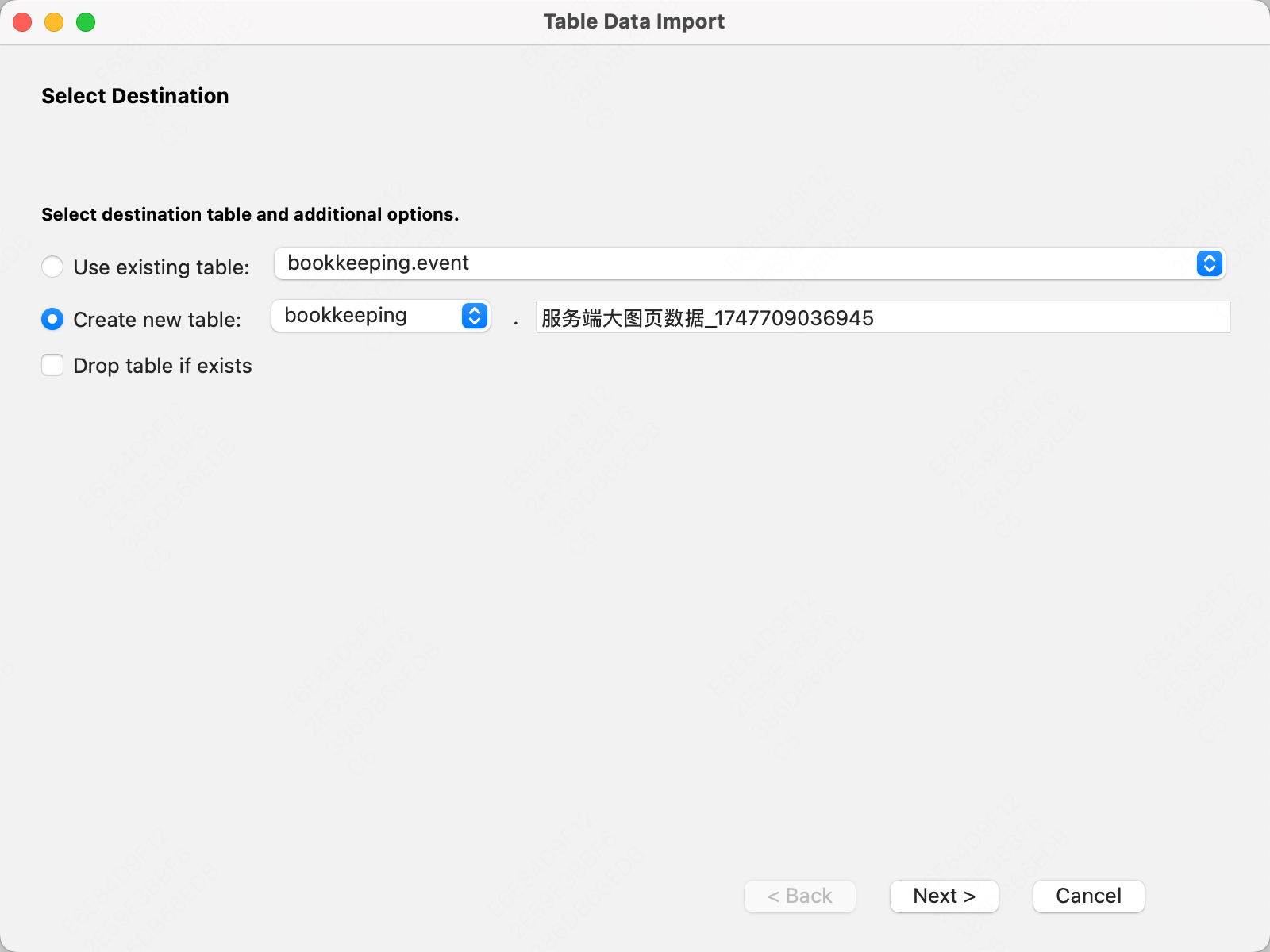
选择要导入的列信息
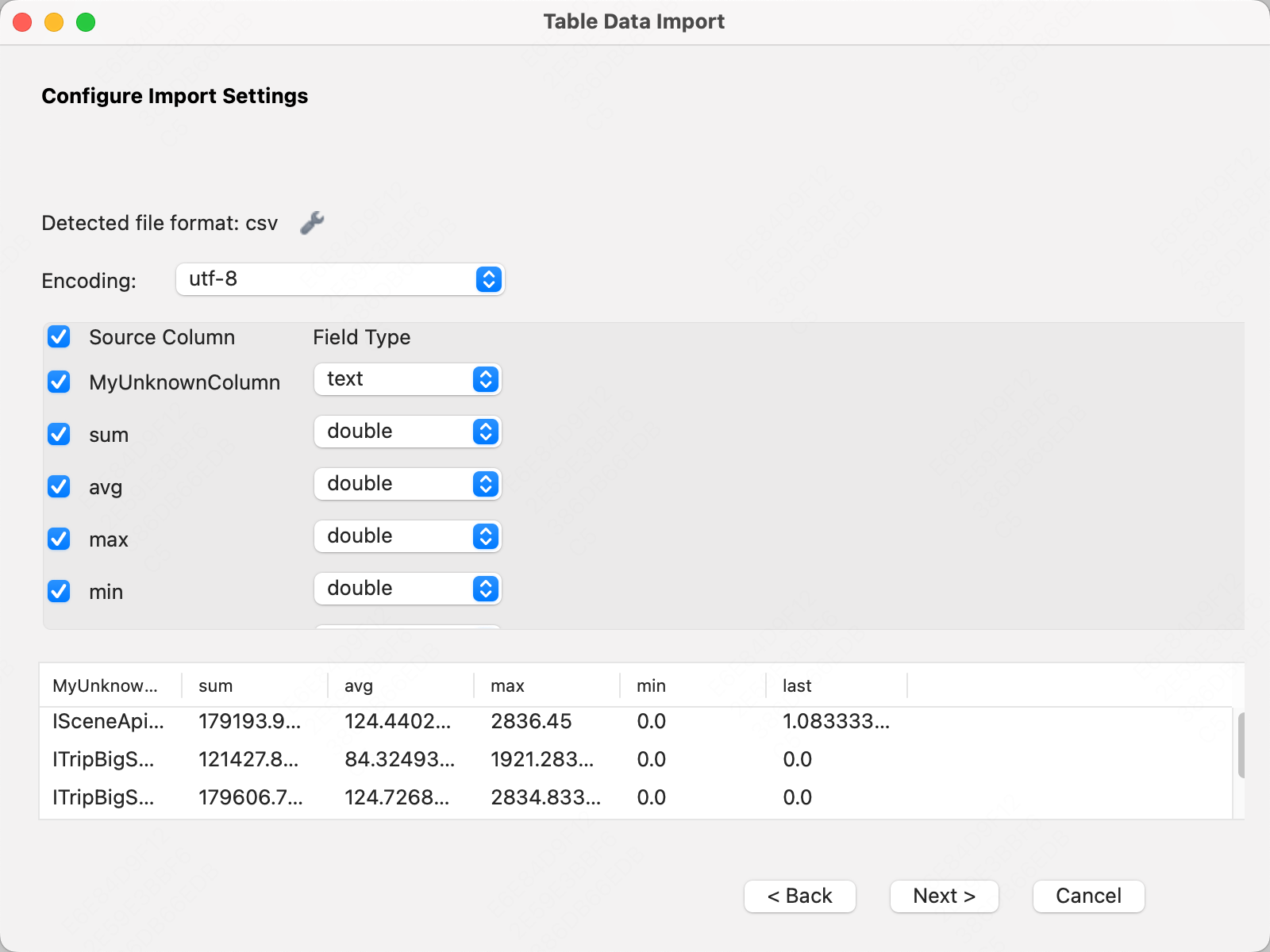
确认信息,点击Next即可执行导入
总结
本次讲解了MySQL的导入导出,讲解了几种方式,以及各自的优缺点、使用场景。并且通过MySQL Workbench做了示例。
文末福利
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
部分电子书如图所示。