大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等!
愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路!
无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
关注我一起挣大钱!文末有惊喜哦!
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
MySQL零基础教程
本教程为零基础教程,零基础小白也可以直接学习。
基础篇和应用篇已经更新完成。
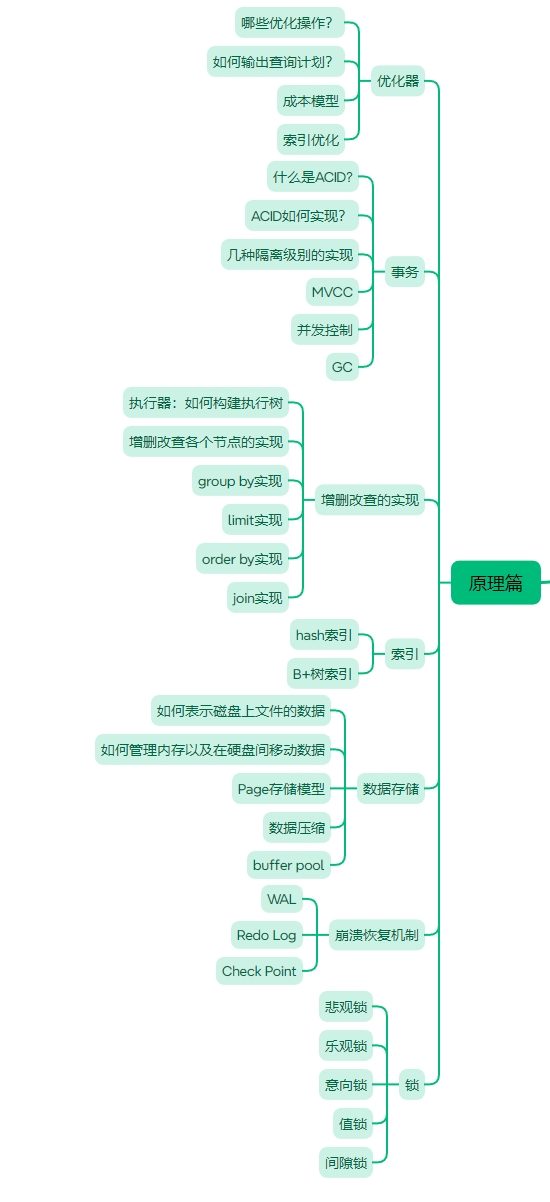
接下来是原理篇,原理篇的内容大致如下图所示。
零基础MySQL教程原理篇之缓冲池实现
MySQL中的buffer pool(缓冲池)是InnoDB存储引擎的重要组件,它负责在内存中管理数据库中的数据和索引的缓存。
它加速了数据库的运行速度,是数据库和磁盘之间的一个中间层。如果没有缓冲池,那么所有的数据库操作都需要进行磁盘IO,有了缓冲池,就不需要频繁的IO操作了。
本次我们的目标是使用C++实现一个缓冲池,这也是CMU15445这门课的Project1。
基于BusTub学术数据库管理系统构建一个面向磁盘的存储管理器。在这样的存储管理器中,数据库的主要存储位置在磁盘。
缓冲池负责在主内存和磁盘之间来回移动物理页面。它允许数据库管理系统支持比系统可用内存量更大的数据库。缓冲池的操作对系统其他部分是透明的。
例如,系统使用其唯一标识符 ( page_id_t )向缓冲池请求一个页面,它不知道这个页面是否已经在内存中,或者系统是否需要从磁盘中检索它。
实现需要是线程安全的。多个线程将并发访问内部数据结构,并且必须确保它们的临界区受到latches的保护(在操作系统中这些被称为“锁”)。
实现总共分为三个部分:
- 实现LRU-K淘汰策略
- 实现磁盘调度程序
- 实现缓冲池管理器
实现LRU-K淘汰策略
关于LRU-K淘汰策略的一些信息可以看上一篇文章零基础MySQL教程原理篇之缓冲池原理及实现
本次实现主要都在这两个文件中:
- 头文件
src/include/buffer/lru_k_replacer.h - 实现文件
src/buffer/lru_k_replacer.cpp
LRU-K 算法会淘汰替换器中反向 k 距离最大的页帧。反向 k 距离是指当前时间戳与第 k 次先前访问的时间戳之间的时间差。少于 k 次历史访问的页帧其反向 k 距离被赋予+inf。当多个页帧具有+inf 反向 k 距离时,替换器会淘汰具有最早整体时间戳的页帧(即记录访问最久远的页帧,在所有页帧中整体上最不常被访问的页帧)。
LRUKReplacer 的最大大小与缓冲池的大小相同,因为它包含了 BufferPoolManager 中所有页帧的占位符。然而,在任意时刻,替换器中的所有页帧并非都被视为可被淘汰。 LRUKReplacer 的大小由可被淘汰页帧的数量表示。 LRUKReplacer 被初始化为空。只有当页帧被标记为可被淘汰时,替换器的大小才会增加。
总共要实现以下方法:
- Evict(frame_id_t* frame_id):将与所有其他被跟踪的可淘汰帧相比具有最大向后k距离的帧驱逐。将
帧id存储在输出参数中并返回 True 。如果没有可淘汰帧,则返回 False 。 - RecordAccess(frame_id_t frame_id):记录给定帧 id 在当前时间戳被访问。此方法应在页面被固定在
BufferPoolManager后调用。 - Remove(frame_id_t frame_id):清除与帧关联的所有访问历史。此方法仅在页面被删除在
BufferPoolManager时调用。 - SetEvictable(frame_id_t frame_id, bool set_evictable): 此方法控制帧是否可被淘汰。它还控制
LRUKReplacer的大小。当您实现BufferPoolManager时,您将知道何时调用此函数。具体来说,当页面的固定计数达到 0 时,其对应的帧被标记为可淘汰,并且替换器的大小增加。 - Size():该方法返回当前在
LRUKReplacer中的可淘汰帧数。
你可以假设不会内存耗尽,但你必须确保你的实现是线程安全的。
以上是实现要求.
接下来讨论一下实现的思路。关于LRU-K在数据库中的实现有一篇论文可以参考一下LRU-K
先来看RecordAccess方法吧,这个方法算是比较简单的了,也是整个LRU-K算法的入口方法,因为每次访问一个page,都需要调用该方法。
首先,我们可以看到在头文件中有LRUKNode的一个类型定义:
1 | class LRUKNode { |
在这里我们有一个List类型的history_用来记录这个Node的访问历史。k_distance_用来计算k距离。fid_表示这个Node的帧id,也就是frame id,is_evictable_代表是否可以被淘汰掉。
因此,在我们的LRUK算法中,需要有一个地方存储这些Node,这里第一个想到的是用一个List来存储,但是,这样每次查找Node都不方便,因此,可以使用一个HashMap来存储,定义一个node_store_来进行存储,这个map的key是frame id,value是一个LRUKNode。我们还需要记录两个大小,一个是LRU淘汰器里面可淘汰的大小,一个是最大的大小。还有最关键的两个数据结构,我们采用两个queue来实现真个LRUK算法,一个lru_node_queue_来存储没有到达K次的节点,一个lru_k_queue_来存储已经到达K次的节点。
因此,在RecordAccess方法中,我们的实现思路就是:
- 给定一个frame id
- 从node_store_中获取这个frame id对应的节点信息
- 如果是第一次访问,继续往下。如果不是,跳到8处
- 首先,我们需要为这个帧创建一个
LRUKNode - 将这个节点插入node_store_中
- 记录本次对于这个新创建LRUKNode的访问历史
- 根据访问次数决定放入的队列,如果小于K次,放入lru_node_queue_,否则放入lru_k_queue_
- 如果node_store_中有这个帧,代表曾经访问过,不需要创建LRUKNode了
- 从node_store_中取出这个LRUKNode,并记录访问历史
- 根据访问次数决定放入的队列,如果小于K次,放入lru_node_queue_,否则放入lru_k_queue_
这里面有一个公共的点在于,6、7步骤和9、10步骤,因此可以把这两个步骤抽取出来一个公共方法,我们暂时命名为RecordHelper方法。
接下来看SetEvictable这个方法,这个方法比较简单,因为只是简单的设置一个LRUKNode的状态为可以被淘汰。
同样的,给定一个frame id,我们需要先从node_store_中进行查询。
- 给定一个frame id
- 从node_store_中获取这个frame id对应的节点信息
- 如果没有查询到,说明不在淘汰器中,因此直接返回错误或者不处理即可。
- 如果查询到一个LRUKNode,从 node_store_ 中取出这个节点
- 修改这个LRUKNode的状态
- 更新可淘汰数量
对于Size方法是最简单的,直接返回可淘汰数量即可。
对于Remove方法,是要将一个节点从淘汰器中删除。
- 给定一个frame id
- 从node_store_中获取这个frame id对应的节点信息
- 如果没有查询到,说明不在淘汰器中,因此直接返回错误或者不处理即可。
- 如果查询到一个LRUKNode,从 node_store_ 中取出这个节点
- 从 node_store_ 中删除这个节点
- 因为我们维护了两个队列,因此这里要判断一下节点的K次,来决定从哪个队列中删除这个节点。
最重要的实现就是Evict方法了,这个是整个算法的核心实现。实现思路如下:
- 优先从 lru_node_queue_ 中淘汰
- 如果在 lru_node_queue_ 中,则将该节点从 lru_node_queue_ 中删除,并从 node_store_ 中删除
- 如果 lru_node_queue_ 中没有符合条件的,再从 lru_k_queue_ 中寻找
- 如果在 lru_k_queue_ 中,则将该节点从 lru_k_queue_ 中删除,并从 node_store_ 中删除。
- 如果两个队列中都没有可淘汰的页面,则返回 false
实现磁盘调度程序
磁盘调度程序负责读写磁盘IO,我们需要实现下面两个文件:
- src/include/storage/disk/disk_scheduler.h
- src/storage/disk/disk_scheduler.cpp
磁盘调度器可以被其他组件(在此情况下,任务#3 中的 缓冲池管理器 )用来排队磁盘请求,这些请求由 DiskRequest 结构体表示(已在 src/include/storage/disk/disk_scheduler.h 中定义)。磁盘调度器将维护一个后台工作线程,负责处理已排队的请求。
磁盘调度器将使用一个共享队列来调度和处理 DiskRequests。一个线程会将请求添加到队列中,而磁盘调度器的工作线程会处理队列中的请求。我们在 src/include/common/channel.h 中提供了一个 Channel 类来促进线程间数据的安全共享,但如果你认为有必要,也可以使用自己的实现。
DiskScheduler 的构造函数和析构函数已经实现,它们负责创建和加入后台工作线程。你只需要实现以下方法:
- Schedule(DiskRequest r) : 安排
DiskManager执行请求。DiskRequest结构体指定请求是读/写操作,数据应写入/读取的位置,以及操作的page ID。DiskRequest还包括一个std::promise,其值应在请求处理完成后设置为 true。 - StartWorkerThread() : 启动后台工作线程的方法,该方法处理计划中的请求。工作线程在
DiskScheduler构造函数中创建,并调用此方法。此方法负责获取排队中的请求并将它们分派到DiskManager。记得在DiskRequest的回调中设置值,以通知请求发起人请求已完成。此方法不应在DiskScheduler的析构函数被调用之前返回。
最后, DiskRequest 中的一个字段是一个 std::promise 。如果你不熟悉 C++ 的 promise 和 future,可以查看它们的文档。在这个项目中,它们基本上为线程提供了一个回调机制,以便线程知道它们的计划请求何时完成。要查看它们可能的使用示例,可以查看 disk_scheduler_test.cpp 。
磁盘管理器类( src/include/storage/disk/disk_manager.h )负责从磁盘读取和写入页面数据。当磁盘调度器处理读或写请求时,会使用 DiskManager::ReadPage() 和 DiskManager::WritePage() 。
在头文件中,已经给我们定义了一个request_queue_属性,这个队列是一个Channel类型的,是一个并发安全的类型,可以简单理解为go中的Channel或者是一个并发安全的队列。
因此,对于Schedule(DiskRequest r)方法,最简单的一个做法就是我们接收到请求以后直接放入这个Channel中。
- 直接放入
request_queue_中
主要的处理逻辑全部放在StartWorkerThread这个方法里面。这里我们首先定一个变量stop_pool_来表示磁盘调度程序是否可以结束,如果不结束,我们就一直循环处理即可。
- 判断stop_pool_是否结束
- 不结束,我们从request_queue_中获取一个要处理的请求。
- 判断该请求是否有效
- 判断请求是写请求还是读请求
- 如果是写请求,调用
disk manager进行写入 - 如果是读请求,调用
disk manager进行读取 - 设置返回值true
实现缓冲池管理器
这是最核心的一个功能了,那就是缓冲池的实现。
缓冲池会调用磁盘调度程序来完成磁盘读写请求。当被明确指示执行或需要淘汰Page以腾出空间给新Page时, 缓冲池 还可以安排脏页写入磁盘。
系统中的所有内存页都由 Page 对象表示。 BufferPoolManager 不需要理解这些页面的内容。
但对于作为系统开发者的你来说,重要的是要理解 Page 对象只是缓冲池中内存的容器,因此它们并不特定于某个唯一页面。也就是说,每个 Page 对象包含一个内存块, DiskManager 将使用这个内存块作为位置来复制它从磁盘读取的物理页面的内容。当 BufferPoolManager 在磁盘之间来回移动时,它会重用同一个 Page 对象来存储数据。这意味着在系统的整个生命周期中,同一个 Page 对象可能包含不同的物理页面。 Page 对象的标识符( page_id )会跟踪它包含的物理页面;如果 Page 对象不包含物理页面,那么它的 page_id 必须设置为 INVALID_PAGE_ID 。
每个 Page 对象还维护一个计数器,用于记录有多少线程“固定”了该页。你的 BufferPoolManager 不允许释放被固定的 Page 。每个 Page 对象还跟踪它是否已变脏。在页被取消固定之前,你的工作是要记录该页是否已被修改。你的 BufferPoolManager 必须在对象被重用之前,将脏 Page 的内容写回磁盘。
你的 BufferPoolManager 实现将使用在本次作业前几步中创建的 LRUKReplacer 和 DiskScheduler 类。 LRUKReplacer 将跟踪 Page 对象何时被访问,以便在必须释放一个帧以从磁盘复制新的物理页时决定要驱逐哪一个。在 BufferPoolManager 中将 page_id 映射到 frame_id 时,再次警告:STL 容器不是线程安全的。 DiskScheduler 将在 DiskManager 上调度对磁盘的读写。
该实现涉及到两个文件:
- src/include/buffer/buffer_pool_manager.h
- src/buffer/buffer_pool_manager.cpp
我们需要实现下面的几个方法:
- FetchPage(page_id_t page_id):如果没有空闲页且所有其他页都被固定,应返回 nullptr。 FlushPage 应无条件刷新页面,无论其固定状态如何。
- UnpinPage(page_id_t page_id, bool is_dirty): is_dirty 参数用于跟踪页面在固定期间是否被修改。
- FlushPage(page_id_t page_id)
- NewPage(page_id_t* page_id)
- DeletePage(page_id_t page_id)
- FlushAllPages()
这些方法的实现依赖上面的方法,建议上面的方法首先通过测试,再继续这几个方法的实现
初始化
在之前讲过了,我们缓冲池的查找是根据page table来查找的,因此,我们的缓冲池管理器中,需要定义一个page table变量,类型是一个map,key是一个page id,value是一个frame id,这样,我们就可以通过page id来找到对应的帧信息。
同样的,在缓冲池管理中,我们还需要定义一个page list来存放所有内存中的page信息,在c++中,这通常是一个指针类型,代码中已经给出了这个变量Page *pages_。
我们还需要使用一个list来告诉我们有哪些空闲空间。我们使用变量free_list来表示。
在初始化的时候,假设我们有5个page的内存可以进行缓冲。那么free_list里面有5个大小,代表有5个page的空间,pages为空,代表这些空间没有page,page table为空。
FetchPage
这个方法的入参是一个page id,因此,我们的第一步就是通过page id来找到frame id。
如果找到了,代表这个page已经在我们内存中,不需要进行磁盘IO,直接返回即可。这里如何取到Page呢,通过Pages这个数组就可以拿到了,下标是我们frame id。即pages_[frame id]就可以获取到内存中的page信息了。
注意:在Page信息中,有一个Pin的概念,pin住也就是固定住的意思是,当前这个page有一个上层的应用在使用,也就意味着我们不能将这个page页面淘汰出内存。
因此,在返回page之前,我们需要pin住这个page,可以通过Page里面的pin_count来完成。
在pin住这个page以后,需要调用第一个LRU-K淘汰策略,这里需要调用两个方法SetEvictable告诉淘汰器我们pin住了这个页面,你不能淘汰它了。RecordAccess告诉淘汰器,我们使用了这个页面,请你更新它的淘汰距离。
如果没有从page table中查找到对应的信息,说明这个page还在磁盘中,我们需要将它从磁盘中,读取到内存。
首先,我们需要知道现在内存中,是否还有空间来存放page,如果没有空间了,就需要淘汰出一个空间。
通过free_list可以看到是否有空间,如果不为空,代表还有空闲的空间。那么就好办了。我们取出free list中第一个空闲空间来进行存放,取出来是一个frame id
如果没有空闲的空间了,首先,要通过page table来检查,是否所有的页面都pin住了,如果是,那么则只能返回nullptr,代表没有空间可以使用了,相当于内存耗尽。
如果有页面没有被pin住,那么我们可以淘汰出一个页面,通过LRU-K算法的Evict方法,会告诉我们有哪个页面可以被淘汰,如果没有可以淘汰的,同样返回nullptr。
接下来,我们已经拿到了一个可以使用的frame id,不管是从空闲空间,还是淘汰出来的。
我们通过pages_[frame id]拿到对应的page页面,这个页面可能是一个空的,也可能是一个淘汰出来的有信息的页面。
我们首先,重置page table,因为所有的信息都需要经过page table获取,我们要告诉page table,当前这个page id对应的frame id已经改变了。
接下来,pin住这个页面,因为上层会使用,然后判断这个page是否有被更新,如果有,那么需要写入磁盘。
接下来,更新内存中page的一些元信息,比如清空数据,设置page id,并从磁盘读取新的数据放到这个page中。
最后,返回page信息。
总结一下:
- 通过page table使用
page id来找到frame id
- 找到以后pin住,返回。
- 通过free list找到空闲的空间,如果有,转到5
- 没有,检查是否所有页面都pin住,如果是,那么返回nullptr
- 通过LRU-K算法淘汰出一个page以使用。
- 修改page table
- pin住页面
- 是否脏page,是的话写入磁盘
- 更新元数据并从磁盘读取新的数据放入page
- 返回page
NewPage
这个方法和上面的方法几乎一样,不同之出在于这个方法是创建一个page空间供使用,因此不需要从磁盘加载数据,也不需要查看page table,因为page table一定没有。
因此步骤如下:
- 通过free list找到空闲的空间,如果有,转到5
- 没有,检查是否所有页面都pin住,如果是,那么返回nullptr
- 通过LRU-K算法淘汰出一个page以使用。
- 修改page table
- pin住页面
- 是否脏page,是的话写入磁盘
- 更新元数据
- 返回page
UnpinPage
这个方法主要是为了解除固定,告诉缓冲池,这个页面上层不再使用了。以后你可以淘汰它了。
这个方法的入参是一个page id,因此,我们的第一步就是通过page id来找到frame id。
和上面不同的在于,如果没有找到,那么直接返回false就可以了,毕竟这个页面不在内存中,没有必要继续了。
如果找到了,通过pages来获取具体的page信息,然后检查,是否pin住,如果没有被pin住,也没有必要继续了。
接下来,对page的pin_count减1,如果只有1个上层使用它,那么减1后会变成0,代表可以淘汰,通知LRU-K算法可以淘汰它。
如果有更新的话,修改page的is_dirty,这样的话,淘汰的时候就会写入磁盘了。
总结步骤如下:
- 通过page table查询,如果没有,返回false
- 获取page具体信息
- 查看page是否pin住,如果没有,返回false
- pin_count–
- 如果pin count是0代表没有上层应用使用,通知LRU-K算法可以淘汰
- 如果有更新,更新page的is_dirty
FlushPage
FlushPage方法的主要作用在于将当前内存中的数据,强制输入磁盘,和淘汰的时候写入磁盘不同,这个是强制写入磁盘。或者说主动写入磁盘。
同样的,如果在page table中没有查到,说明不存在内存中,直接返回false。
如果查到了,那么加载page信息,调用磁盘调度来写入磁盘
FlushAllPages
这个方法不多说了,很简单,批量写入磁盘,你想的没错,你太聪明了,就是批量调用FlushPage即可。
DeletePage
DeletePage方法的主要作用在于删除这个内存中的页面。
首先,同样是查找page table,如果不在内存,返回false
找到了以后,需要加载page信息,查看是否pin住,如果有程序在使用这个page,那么不能删除。
如果没有pin住,那么可以进行删除了。
删除分成几步:
- 从page table删除
- 放入free list
- 从LRU-K淘汰器删除
- 重置page内存信息
- 释放内存空间
结论
本次我们完成了CMU15445课程的Lab1,实现了一个数据库的缓冲管理器,其实这个管理器真正实现起来非常难,我这里没有说详细的锁信息,如何防止并发,如何细粒度的加锁,可以给出一些我的锁参考。
最简单的当然是一个大锁锁天下,但是这样会影响性能。
我划分了下面几个锁:
- PageTableLock 用来锁住page table的所有操作
- FreeLock 用来锁住free list的所有操作
- PageLock 用来锁住所有page内存的操作
这三个锁之间是有一些嵌套关系的,整体通过两阶段锁协议来实现,来保证锁的安全性。以防止死锁发生。
使用细粒度的锁进行性能优化以后,我在这个项目的排行榜中获得了53的名次。
因为教授说过不要看别人的代码,因此我这里给出的是比较详细的实现思路。如果有同学在实现,有一些问题的话可以留言或者私信我一起讨论哦~
文末福利
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
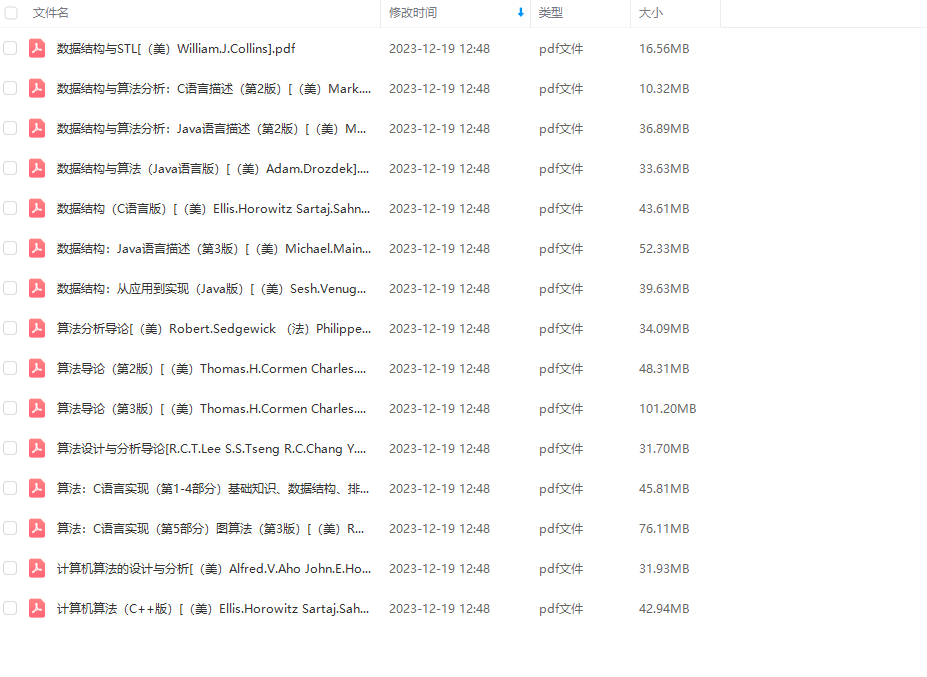
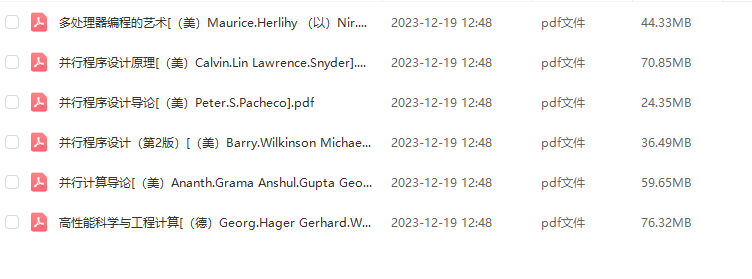
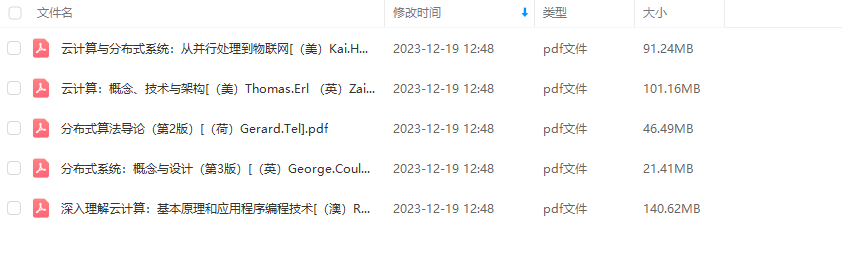
部分电子书如图所示。