大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等!
愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路!
无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
关注我一起挣大钱!文末有惊喜哦!
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
MySQL零基础教程
本教程为零基础教程,零基础小白也可以直接学习。
基础篇和应用篇已经更新完成。
接下来是原理篇,原理篇的内容大致如下图所示。
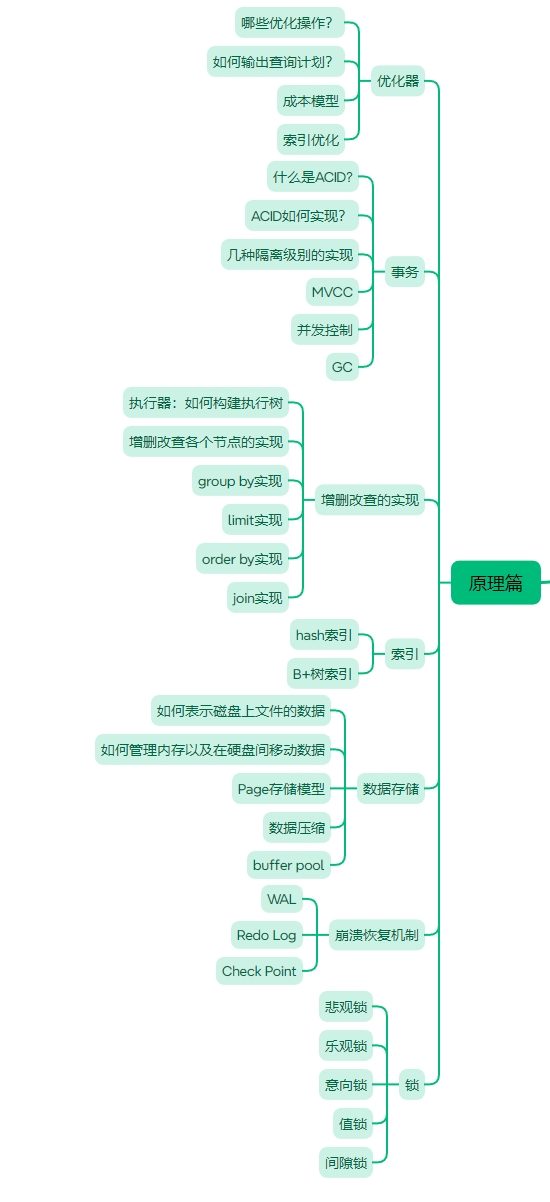
零基础MySQL教程原理篇之优化器原理解析
MySQL优化应该是一个面试必考的问题了,也是一个老生常谈的问题。
10个面试里面至少有9个面试会问你,你怎么优化SQL性能?
本文将从MySQL原理层面出发,告诉你如何优化,为何要这么做。
查询计划
假设有以下sql,其中Emp表有10000个records, 1000个pages, Dept表有500个records, 50个pages
- 对于Emp表来说,代表一个page里面有10行记录
- 对于Dept表来说,也同样一个page里面有10行记录
1 | select distinct ename from Emp E join Dept D on E.did = D.did where D.dname = 'Toy' |
这个SQL的功能相信都知道,就是一个简单的连表查询,那么想要优化,我们首先要知道,这个SQL会怎么执行呢?
数据库实际上会构建出一个执行树,按照这个执行树来执行。他还有另一个名字,也就是查询计划。
查询计划实际上就是会输出这个执行树。
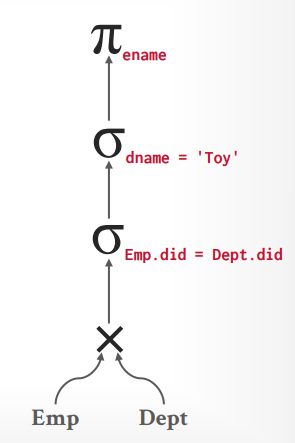
每个DBMS的输出都不太一样,比如MySQL的查询计划其实和树很难联系起来。
但是如果你使用PostgreSQL的话,就能明显看出来了。
如果按照上述的执行树来执行,步骤如下:
- 先关联Emp表和Dept表进行查询,这一步对于两个表都是全表扫描,大约产生(50 + 50000)个读IO和
1000000个写IO - 执行
on E.did = D.did,这一步会筛选出符合这个条件的数据,大约产生1000000个读IO和2000个写入IO - 执行
where D.dname = 'Toy',这一步会筛选出Dept表中dname字段是Toy的数据,大约产生2000个读IO和4个写入IO - 最后执行
select distinct ename,取出每一行中的ename字段并且去重,产生4个读IO和1个写入IO
好了,到这里,MySQL就执行结束了,这时候就会输出最终结果了。
可以看到,IO次数非常多,大家都知道,磁盘IO是一个非常慢的操作,这么多次IO,这个SQL怎么会快呢?
上面使用的JOIN方式比较简单粗暴,因此,我们可以将这个替换成另外一个执行方式.
上面是笛卡尔积的执行方式,我们可以换成JOIN代数的方式。
对于我们的SQL来说,是没有变化的,但是对于MySQL的执行方式来说,是不一样的。
为什么JOIN代数比笛卡尔积快呢?因为JOIN是把第1-2两步合并到一起执行了,因此执行速度要快的多。

对于JOIN来说,其实是有不同的执行算法在里面的,具体的执行算法,在原理篇中也会讲到。
结论
掌握MySQL崩溃恢复不仅能提高您的数据库管理技能,还能为您的职业发展提供坚实的基础。希望这篇文章能帮助您在面对数据库崩溃时保持冷静,并迅速恢复数据。记住,数据安全是数据库管理的核心,定期备份和监控是确保数据安全的重要手段。
文末福利
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
部分电子书如图所示。