大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队!
我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等!
愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路!
无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
关注我一起挣大钱!文末有惊喜哦!
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
DDD战术设计代码结构
之前讲过了如何进行领域建模,也就是将真实世界映射到业务领域中。
接下来,看一下如何将业务领域落地到代码实现里面。
只有战略设计和战术设计结合到一起,才能做好DDD,不能只注重领域建模而忽视了代码实现,也不能只注重代码实现而忽视了领域建模。
层次结构
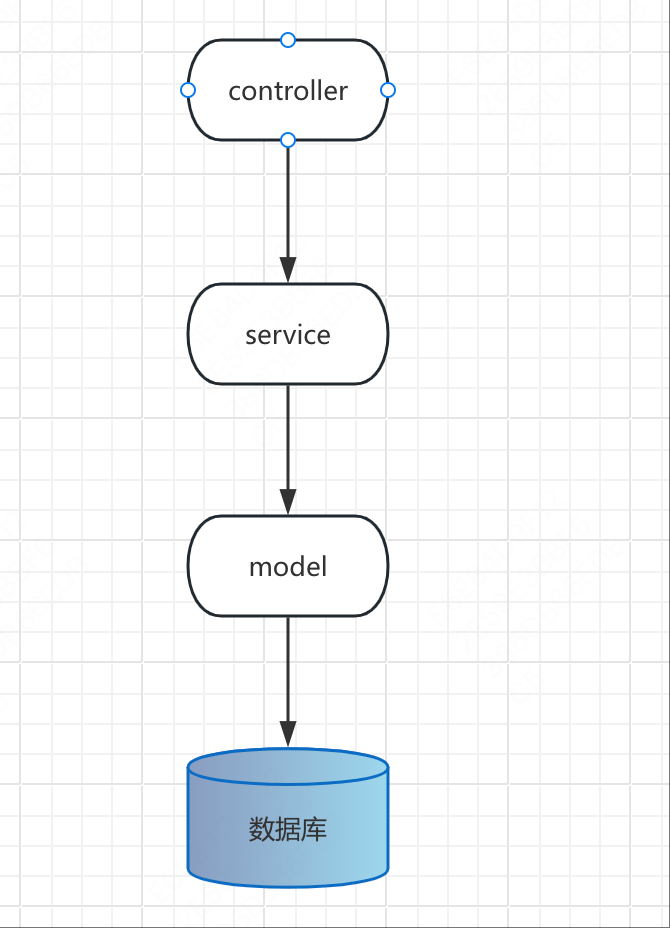
贫血三层架构
一般情况下,我们使用的是贫血三层架构。也就是
- controller:负责接收参数,参数校验,调用service处理业务逻辑。
- service:处理业务逻辑
- Model:和数据库交互,可能是Mybatics。
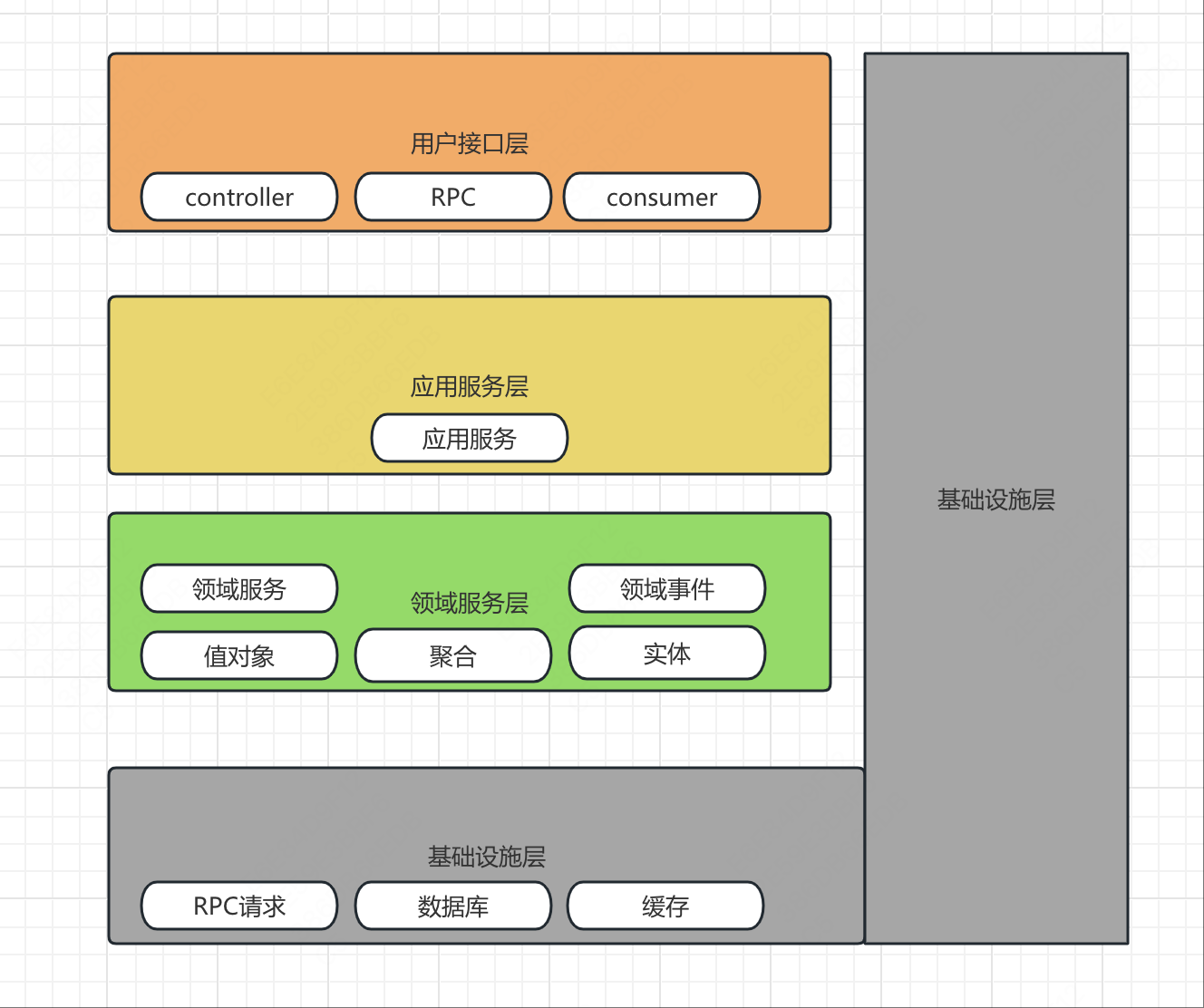
DDD四层架构
而对于DDD来说,使用的则是经典四层架构。
- 用户接口层:作为程序的入口,controller就属于这一层。
- 应用服务层:负责领域编排,不负责具体的业务逻辑处理。通过调用领域服务层来完成业务逻辑处理。
- 领域服务层:负责具体的业务逻辑处理。可以将service的业务逻辑下沉到这一层,而业务逻辑编排则放到应用服务层。
- 基础设施层:提供一些基础设施,包括数据库持久化,缓存,RPC调用等等。Model就属于这一层。
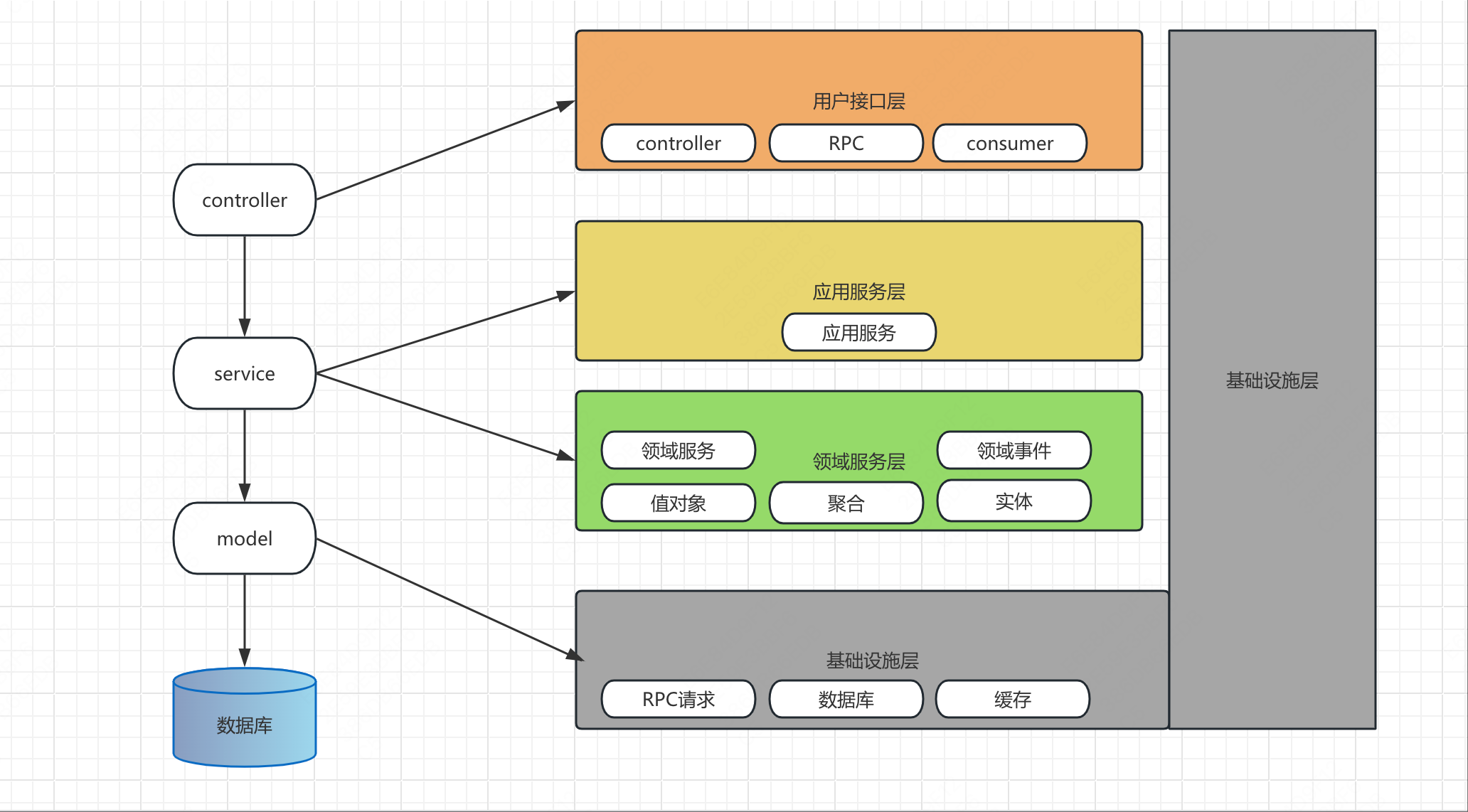
如果是重构项目的话,可以将三层架构拆解成四层架构,映射关系如下:
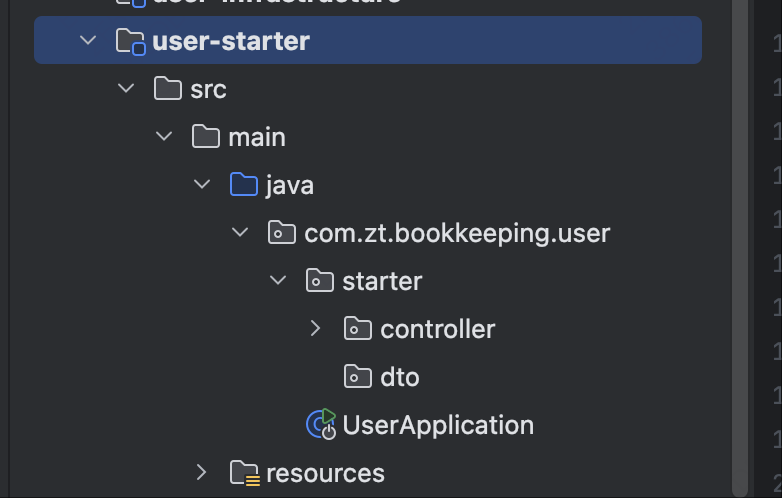
用户接口层
用户接口层的命名可以是starter或者是interface等等。
用户接口层的职责就是整个程序的入口,对外部提供接口,包括HTTP接口和RPC接口。
这一层的结构很简单:
- controller: 就是传统的controller
- dto: dto里面包括了请求参数和返回参数
- converter:负责将请求参数转换成应用服务的入参,将应用服务的出参转换成返回参数
- consumer:消费者,负责消费MQ的消息
我们还可以将这一层进一步划分为两个目录,一个是HTTP接口的starter目录,一个是RPC接口的api目录。
因为一般来说rpc会对外部提供一个包。因此可以将这两个分开。
而且对于RPC接口的包来说,consumer这个目录是没有用的,因此,只需要三个目录就可以了。
对于HTTP接口来说,因此请求和返回都是JSON格式的对象,因此,可以省略dto和converter这两个步骤。
应用服务层
应用服务的职责边界很清晰,就是调用领域服务、聚合等完成业务操作。这一层只做服务编排,而不处理具体的业务逻辑。
- 代码结构
因此,应用服务层的代码结构也很简单,可以放到目录application里面。
- service: 应用服务,应用服务不需要和领域服务一对一的关系,也不需要和controller一对一的关系。根据业务来创建即可。
- dto: 这个里面存放应用服务层的入参和出参。可以根据
CQRS规则来设置,创建、修改、删除的入参是Command。查询的入参是Query。 - event:应用服务层的事件发布。
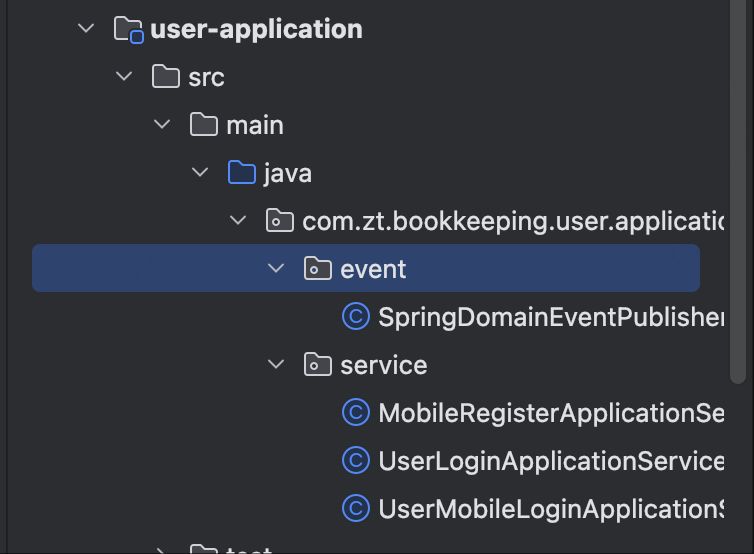
- 代码示例:
这里,用注册用户来做一个简单的示例。看一下应用服务层是如何做服务编排的。
1 |
|
领域服务层
领域服务层是DDD的核心,所有的业务逻辑都以充血模型的形式放到聚合根、实体、值对象里面。
领域服务层的入参和出参都应该是领域模型。
- 代码结构
领域服务层的代码结构相对复杂。领域服务层的代码目录首先按照聚合来区分。其次,每个聚合下面有自己的领域模型和领域服务。可以放到目录domain里面。
- 聚合
- service: 存储领域服务,领域服务的职责是编排聚合。调用聚合来完成业务逻辑。
- entity:这个目录存储所有的聚合根、实体和值对象。
- event:存放领域事件
- repository:存放仓储的接口,仓储的具体实现放在基础设施层。
- factory:存放工厂的接口,工厂的具体实现放在基础设施层。
- enums:存放一些领域层使用的枚举
- gateway:存放一些RPC请求的接口,具体实现放在基础设施层。
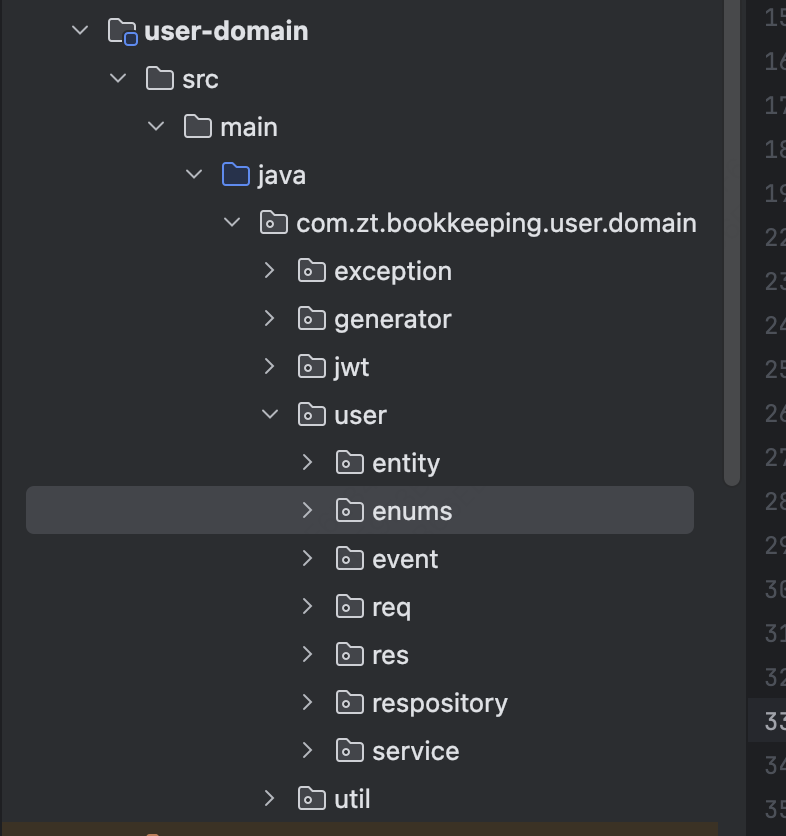
- 代码示例
可以看到领域服务里面调用了Repository来重建聚合,然后判断聚合是否存在来完成校验。
1 | public void canRegister(String mobile) { |
再来看一下判断能否登陆的方法。这里调用的是聚合的方法来校验用户状态,而不是通过领域服务来校验。这就是编排聚合。
1 | public void canLogin(UserAgg userAgg) throws UserLoginException { |
基础设施层
基础设施层为所有层提供基础的技术支持,包括但不限于数据库、缓存、队列、RPC请求、HTTP请求等等。
基础设施层有两个重要的概念
- Repository:仓储,为领域模型提供持久化的功能,入参是领域模型,将领域模型转换成数据模型,在进行持久化。至于是缓存还是数据库,是MySQL还是PostgreSQL,上层并不关心。同时,也负责从持久化中恢复领域模型。
- Factory:工厂,和工厂模式的工厂不同,这里的工厂是负责创建领域模型的。有些领域模型的创建较为复杂,可以封装到工厂里面。
- 基础设施层的目录
基础设施层的代码结构可以按照职能区分。其中Repository和聚合是一对一的关系,一个聚合有一个Repository负责持久化和恢复。可以放到目录infrastructure里面。
- config: 放置项目的配置文件。
- repository: 放仓储的具体实现类,一个仓储对应一个聚合,负责持久化聚合里面的多个表数据。
- factory: 工厂的具体实现类,负责创建领域模型。
- gateway:放对外部的请求,包括HTTP请求和RPC请求。
- util:放一些工具类
- listener: 放一些领域事件的监听者,有一些领域事件是放到队列中其他服务监听,也有一些领域事件是自己服务监听的。
- producer: 生产者,负责向队列中发送消息
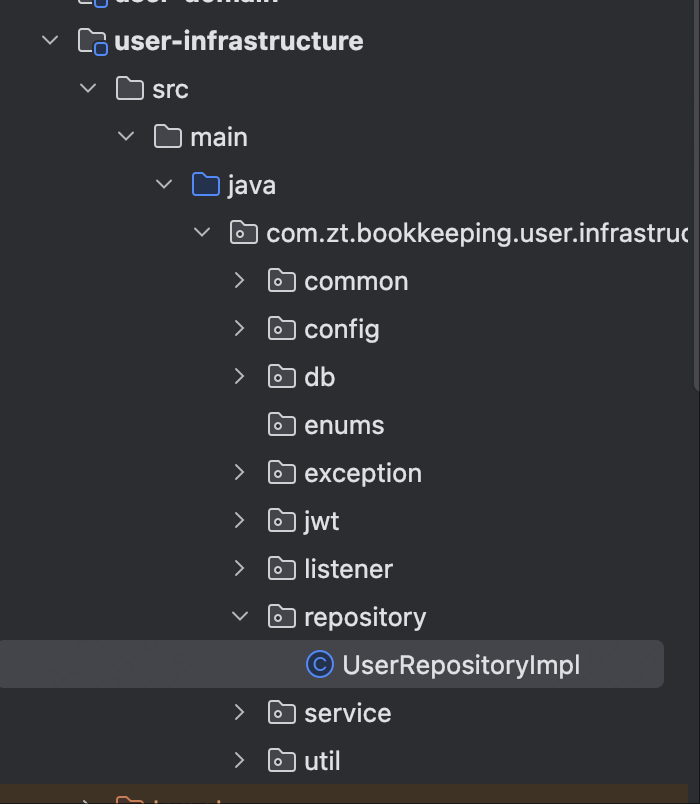
- 代码示例
以用户聚合对应的用户仓储来看,需要创建用户的时候传入用户聚合。然后转换成数据模型,当插入数据库以后会更新用户聚合的ID。
1 |
|
当需要查询数据的时候,传入查询条件,返回用户聚合。
1 |
|
四层架构之间的依赖关系
四层架构的目录结构已经出来了
- starter: 放置启动类和HTTP请求以及队列的消费者。
- api: 放置RPC接口以及外部需要使用的一些DTO。
- application:应用服务层的代码
- domain: 领域服务层的代码
- infrastructure: 基础设施层的代码
- common: 可以放置一些公共的代码,比如工具类、exception、枚举等。
总的目录结构如下,外层的user代表服务名称,这个是用户服务,也就是用户领域。
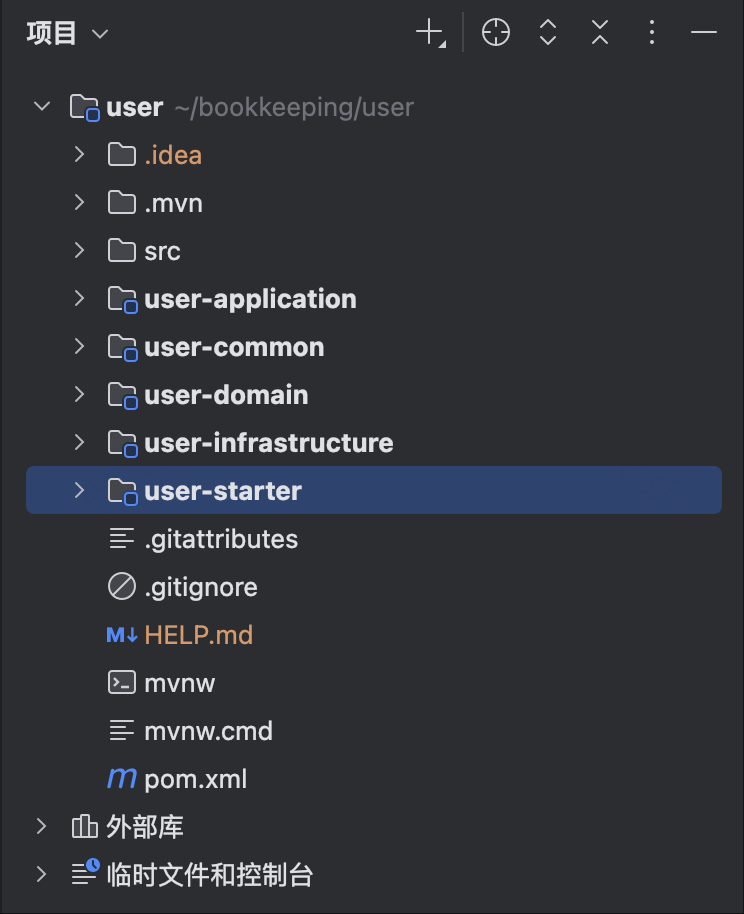
用户接口层
- 依赖应用服务层:调用应用服务实现功能。
1 | <dependency> |
应用服务层
- 依赖领域服务层:应用服务的职责就是编排领域服务和领域模型。
1 | <!-- 依赖领域层 --> |
领域服务层
- 什么也不依赖,领域服务层作为最底层的服务,什么也不依赖,如果需要使用基础设施的话,接口定义在领域层,实现放在基础设施层。
基础设施层
- 依赖领域服务层:因为接口要放在领域服务层,实现放在基础设施层
1 | <!-- 依赖领域层 --> |
整体依赖关系如下:
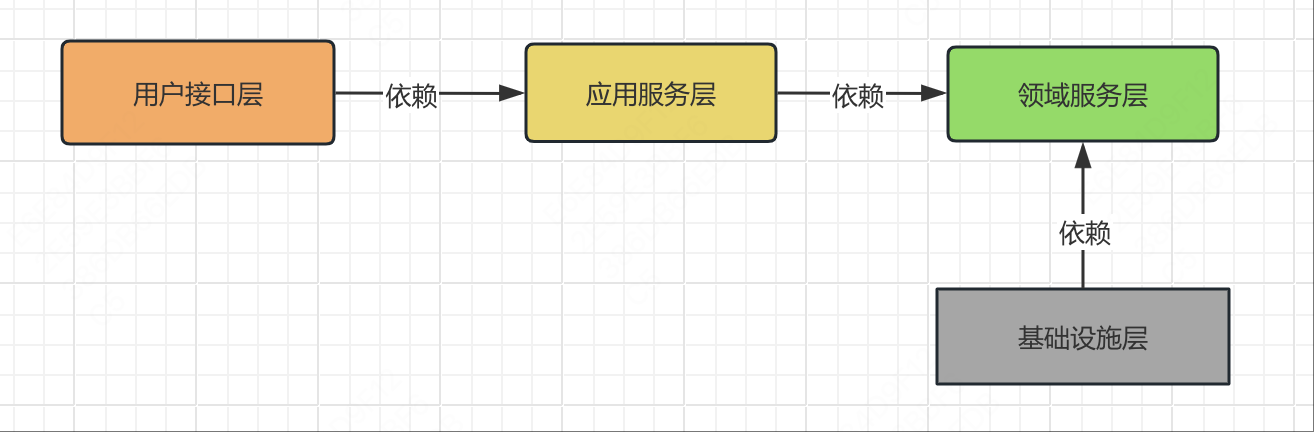
如何确定代码放在哪一层?
写代码的时候如何确定这个代码该放到哪一层呢?
如果这个代码是负责和外部交互的,那么就放到基础设施层。
如果这个代码包含业务逻辑,那么就放到领域层,将业务逻辑拆分到聚合、实体、值对象中,如果逻辑复杂,就通过领域服务进行编排。
应用层代码只编排领域服务和领域模型。
接口层代码只暴露接口给外部。
文末福利
关注我发送“MySQL知识图谱”领取完整的MySQL学习路线。
发送“电子书”即可领取价值上千的电子书资源。
发送“大厂内推”即可获取京东、美团等大厂内推信息,祝你获得高薪职位。
发送“AI”即可领取AI学习资料。
部分电子书如图所示。