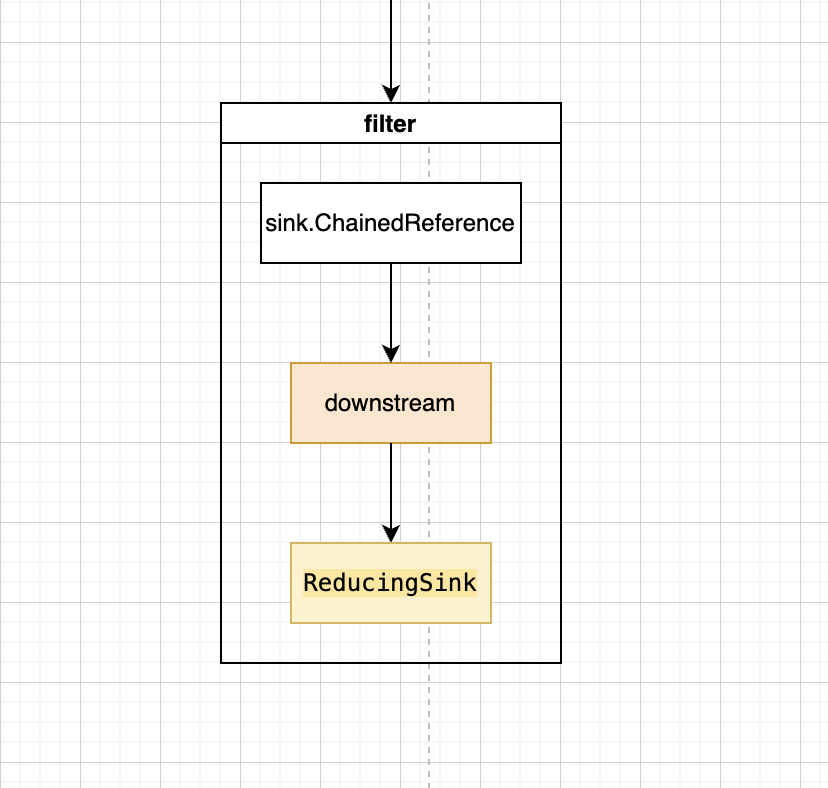
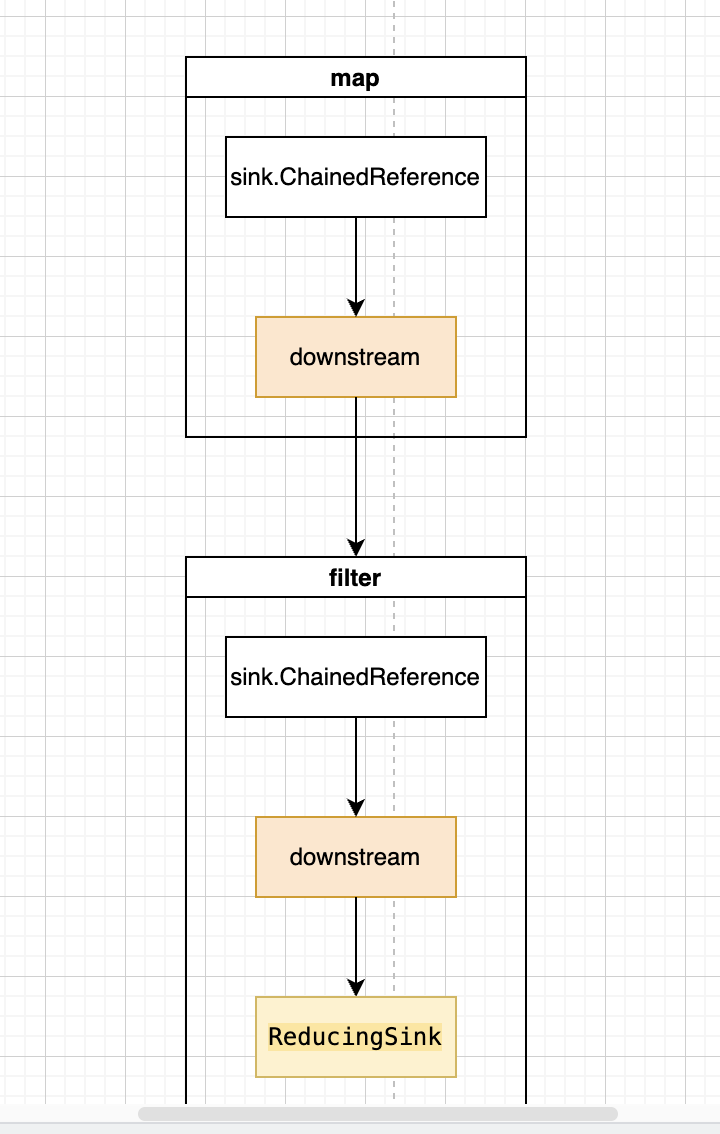
/** Constructs a TerminalOp that implements a mutable reduce on reference values. 形参: collector – a Collector defining the reduction 返回值: a ReduceOp implementing the reduction */ publicstatic <T, I> TerminalOp<T, I> makeRef(Collector<? super T, I, ?> collector) {
/** * Evaluate the pipeline with a terminal operation to produce a result. * * @param <R> the type of result * @param terminalOp the terminal operation to be applied to the pipeline. * @return the result */ //这里的参数就是上面刚生成的结果态对象。 final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) { //断言类型是否是引用类型 //getOutputShape是ReferencePipeline类的方法,直接返回的就是 REFERENCE, 刚才生成的结果态的shape也是 REFERENCE assertgetOutputShape() == terminalOp.inputShape(); //判断是否已经消费 如果已经消费了 抛出非法状态异常。 if (linkedOrConsumed) thrownewIllegalStateException(MSG_STREAM_LINKED); //标记为已消费 linkedOrConsumed = true; //如果是并行流调用结果态的并行流方法,否则调用顺序流方法。 return isParallel() ? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())) : terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags())); }
/** * Get the source spliterator for this pipeline stage. For a sequential or * stateless parallel pipeline, this is the source spliterator. For a * stateful parallel pipeline, this is a spliterator describing the results * of all computations up to and including the most recent stateful * operation. */ @SuppressWarnings("unchecked") //参数是0 private Spliterator<?> sourceSpliterator(int terminalFlags) { // Get the source spliterator of the pipeline //声明 spliterator = null Spliterator<?> spliterator = null; //判断 sourceStage指针的sourceSpliterator是否为null //sourceStage指针指向头节点,所以是判断 头节点的 sourceSpliterator是否为null。 //在最开始初始化的时候,头节点的 sourceSpliterator 指向了一个 ArrayListSpliterator 对象,所以这里不是null //不是null的话我们会取出 头节点的 sourceSpliterator if (sourceStage.sourceSpliterator != null) { // 本地变量 spliterator = 头节点的 ArrayListSpliterator 对象 里面包含我们的源数据 list。 spliterator = sourceStage.sourceSpliterator; // 删除头节点的 sourceSpliterator sourceStage.sourceSpliterator = null; } //这里在初始化的时候并没有 初始化 头节点的 sourceSupplier ,所以这里是null,并不会走到这里 elseif (sourceStage.sourceSupplier != null) { spliterator = (Spliterator<?>) sourceStage.sourceSupplier.get(); sourceStage.sourceSupplier = null; } else { thrownewIllegalStateException(MSG_CONSUMED); }
//判断是否是并行流,触发短路。 if (isParallel() && sourceStage.sourceAnyStateful) { // Adapt the source spliterator, evaluating each stateful op // in the pipeline up to and including this pipeline stage. // The depth and flags of each pipeline stage are adjusted accordingly. intdepth=1; for (@SuppressWarnings("rawtypes")AbstractPipelineu= sourceStage, p = sourceStage.nextStage, e = this; u != e; u = p, p = p.nextStage) {
intthisOpFlags= p.sourceOrOpFlags; if (p.opIsStateful()) { depth = 0;
if (StreamOpFlag.SHORT_CIRCUIT.isKnown(thisOpFlags)) { // Clear the short circuit flag for next pipeline stage // This stage encapsulates short-circuiting, the next // stage may not have any short-circuit operations, and // if so spliterator.forEachRemaining should be used // for traversal thisOpFlags = thisOpFlags & ~StreamOpFlag.IS_SHORT_CIRCUIT; }
// Inject or clear SIZED on the source pipeline stage // based on the stage's spliterator thisOpFlags = spliterator.hasCharacteristics(Spliterator.SIZED) ? (thisOpFlags & ~StreamOpFlag.NOT_SIZED) | StreamOpFlag.IS_SIZED : (thisOpFlags & ~StreamOpFlag.IS_SIZED) | StreamOpFlag.NOT_SIZED; } p.depth = depth++; p.combinedFlags = StreamOpFlag.combineOpFlags(thisOpFlags, u.combinedFlags); } }
//直接到这里,由于传进来的是0,所以直接返回了 if (terminalFlags != 0) { // Apply flags from the terminal operation to last pipeline stage // 合并结果态操作到最后一个流操作的标志 combinedFlags = StreamOpFlag.combineOpFlags(terminalFlags, combinedFlags); }