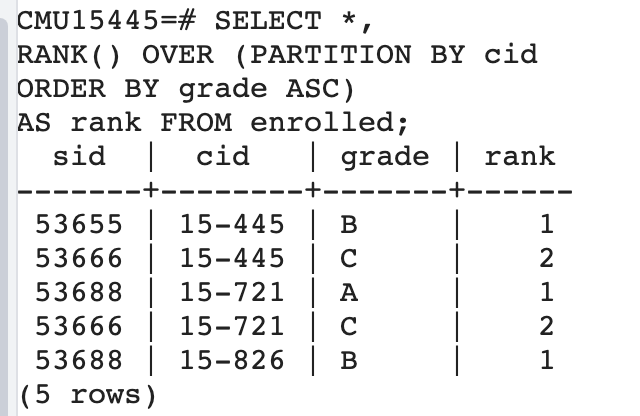
<mappernamespace="com.example.repository.mybatis.UserMapper"> <selectid="selectByUsername"resultType="com.example.repository.mybatis.UserPO"> SELECT id, username, password_hash, status FROM users WHERE username = #{username} </select> </mapper>
WITH active_users AS ( SELECT user_id FROM user_logins WHERE login_date >CURRENT_DATE-INTERVAL'30 days' ) SELECTCOUNT(*) FROM orders WHERE user_id IN (SELECT user_id FROM active_users);
多次引用中间结果,避免重复计算
如果某个子查询需要被多次引用,CTE可以定义一次,后续多次调用,避免重复书写和计算,提高效率。
1 2 3 4 5 6 7
WITH sales_summary AS ( SELECT product_id, SUM(amount) AS total_sales FROM sales GROUPBY product_id ) SELECT*FROM sales_summary WHERE total_sales >1000; -- 也可以在后续多个查询中引用 sales_summary
分步处理数据,逐步细化结果
例如,先计算每个部门的总销售额,再筛选出销售额最高的部门。
1 2 3 4 5 6 7 8 9 10 11 12
WITH dept_sales AS ( SELECT department_id, SUM(sales) AS total_sales FROM employees GROUPBY department_id ), top_dept AS ( SELECT department_id FROM dept_sales ORDERBY total_sales DESC LIMIT 1 ) SELECT*FROM employees WHERE department_id IN (SELECT department_id FROM top_dept);
数据去重和排名
CTE可以配合窗口函数实现数据去重、分组排名等需求。
1 2 3 4 5 6
WITH ranked_orders AS ( SELECT*, ROW_NUMBER() OVER (PARTITIONBY customer_id ORDERBY order_date DESC) AS rn FROM orders ) SELECT*FROM ranked_orders WHERE rn =1;
company_contract_application:公司合同申请表,字段如 application_id, contract_id, apply_time, status 等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
SELECT c.company_id, c.company_name, cc.contract_id, cc.contract_no, cca.application_id, cca.apply_time, cca.status FROM company c JOIN company_contract cc ON c.company_id = cc.company_id LEFTJOIN company_contract_application cca ON cc.contract_id = cca.contract_id AND cca.apply_time = ( SELECTMAX(apply_time) FROM company_contract_application WHERE contract_id = cc.contract_id );
WITH latest_applications AS ( SELECT application_id, contract_id, apply_time, status, ROW_NUMBER() OVER (PARTITIONBY contract_id ORDERBY apply_time DESC) AS rn FROM company_contract_application ) SELECT c.company_id, c.company_name, cc.contract_id, cc.contract_no, la.application_id, la.apply_time, la.status FROM company c JOIN company_contract cc ON c.company_id = cc.company_id LEFTJOIN latest_applications la ON cc.contract_id = la.contract_id AND la.rn =1;
CREATEFUNCTION get_employee_salary(emp_id INT) RETURNSDECIMAL(10, 2) BEGIN DECLARE emp_salary DECIMAL(10, 2); SELECT salary INTO emp_salary FROM employees WHERE id = emp_id; RETURN emp_salary; END//
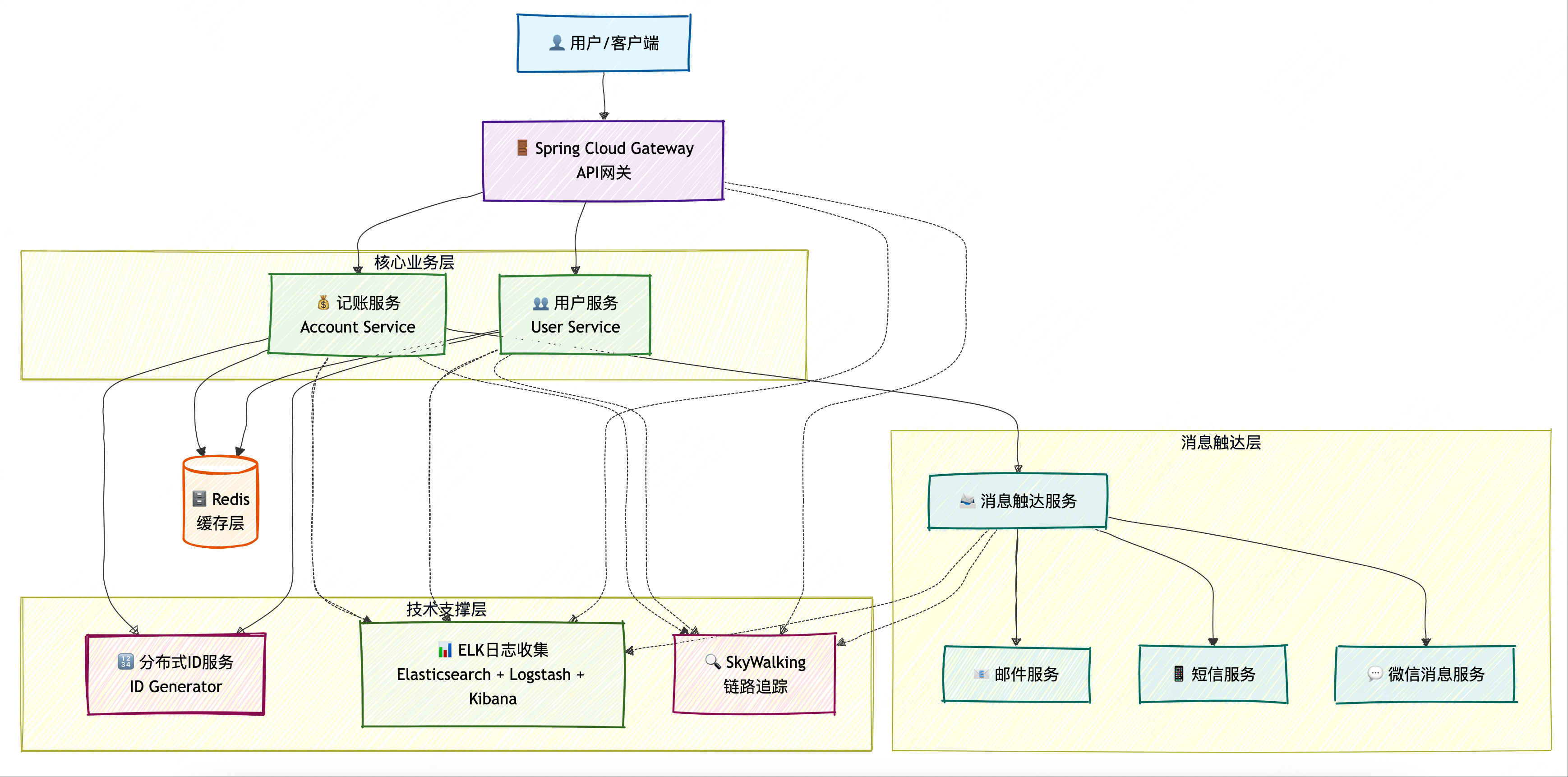
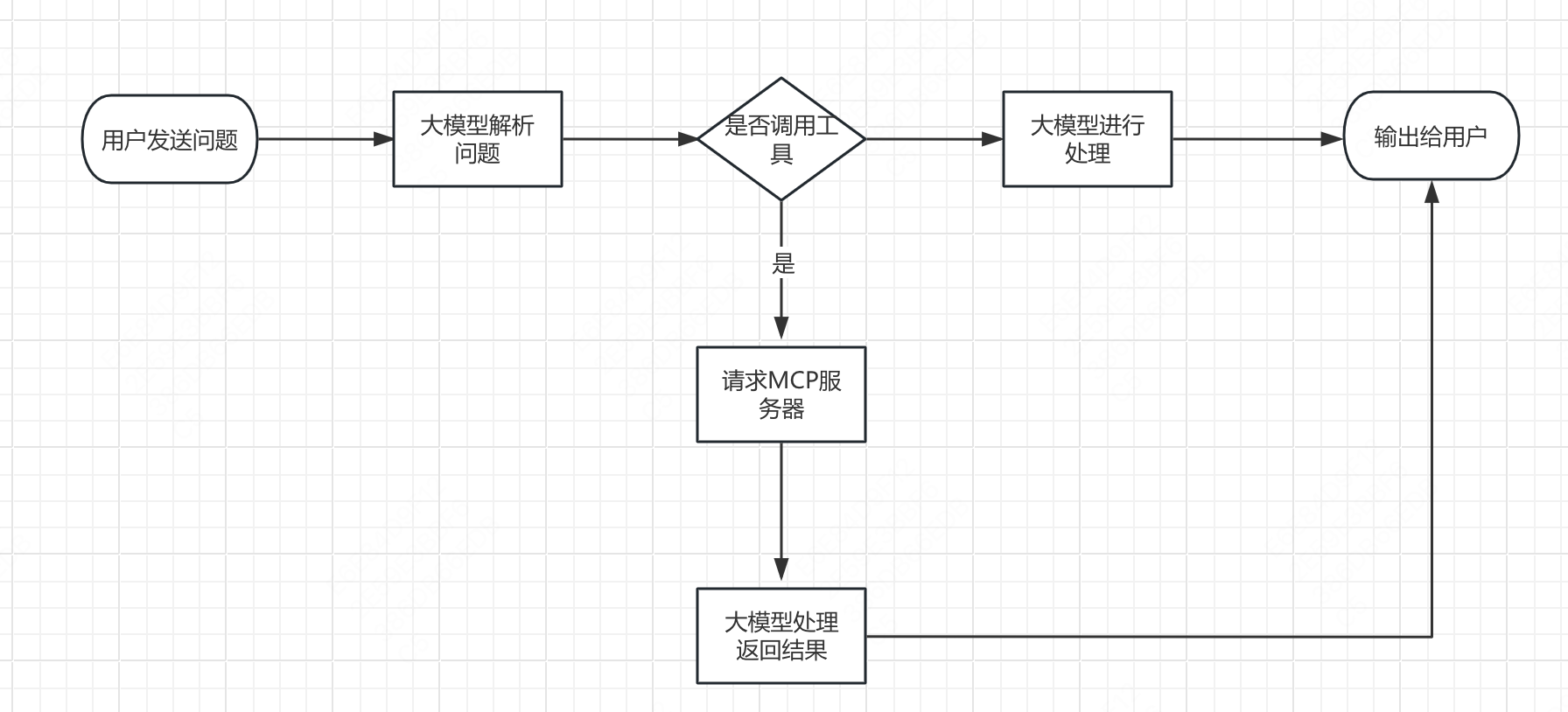
Model Context Protocol(MCP)是由Anthropic于2024年11月推出的开放标准,旨在为大型语言模型(LLM)应用提供统一的上下文交互接口,使其能够与外部数据源和工具进行无缝集成。MCP采用客户端-主机-服务器架构,基于JSON-RPC 2.0协议,支持有状态连接和功能协商,允许AI模型访问文件、执行函数和处理上下文提示。
@Tool(description = "Get weather alerts for a US state") public String getAlerts( @ToolParam(description = "Two-letter US state code (e.g. CA, NY") String state ) { // 使用 RestClient 发起 GET 请求,获取指定州的天气警报信息 Alert alert = restClient.get().uri("/alerts/active/area/{state}", state).retrieve().body(Alert.class);