stream
stream的结果态
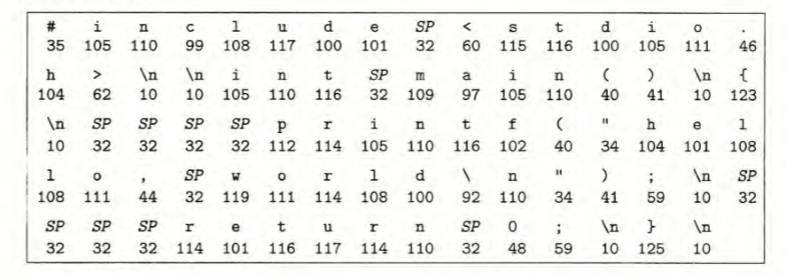
当前使用的结果态方法是collect。主要作用是收集。看一下源码。作为结果态方法,不再返回stream类型的对象。接受一个Collector类型的对象作为参数。
1 | public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) { |
先看一下ReduceOps 类的 makeRef方法。构造一个结果态对象,对引用类型的值执行可变的计算,规约。
1 |
|
看一下ReduceOp类。他根据指定的流类型创建ReduceOp对象。 使用指定的supplier创建 accumulating sinks。 对流进行预估并将结果发送至 accumulating sinks。然后执行计算操作。
1 |
|
创建完结果态对象以后,将结果态对象传入evaluate方法。预估管道的结果态操作并产生一个结果。
- container = evaluate(ReduceOps.makeRef(collector));
1 | /** |
调用顺序流处理方法之前,参数先调用了sourceSpliterator方法。而在调用sourceSpliterator之前,还调用了结果态的getOpFlags方法。
getOpFlags方法在创建结果态的时候增加的,代码在下面,一起回顾一下。这个方法很简单,就是看collector的characteristics是否无序。
- 如果无序,返回StreamOpFlag.NOT_ORDERED标志,即32
- 否则返回0
我们这里返回的是0,因为list并不需要有序。
1 |
|
接下来看sourceSpliterator方法。作用如下:
- 如果是一个顺序流或无状态并行流,返回初始化的spliterator对象。
- 如果是一个有状态并行流,返回一个spliterator对象,包含所有最近状态操作的计算结果。
1 | /** |
回到上面evaluate方法的这段代码terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
- 第一个参数是this
- 第二个参数是刚才返回的 头节点的 ArrayListSpliterator
- 复习一下ArrayListSpliterator的属性
- list = list
- index = 0
- fence = -1
- expectedModCount = 0
接下来走到了 结果态 对象的 evaluateSequential 方法。
1 |
|
看一下流的wrapAndCopyInto方法。这个方法在 AbstractPipeline 类里面。
- 第一个参数是 ReducingSink 对象
- 第二个参数是 ArrayListSpliterator 对象
1 |
|
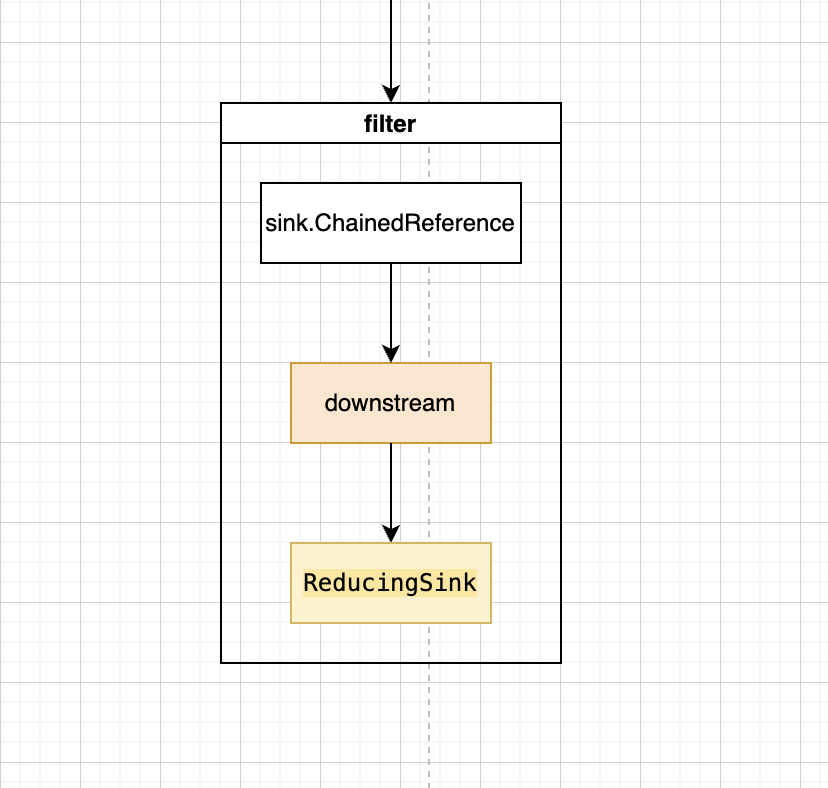
回顾一下 filter 节点的 opWrapSink 方法 。这是在中间态节点生成的时候,创建无状态对象的时候添加的。
1 | return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SIZED) { |
看一下现在的 sink 链
回顾一下 map 节点的 opWrapSink 方法 。这是在中间态节点生成的时候,创建无状态对象的时候添加的。
1 |
|
看一下现在的 sink 链。
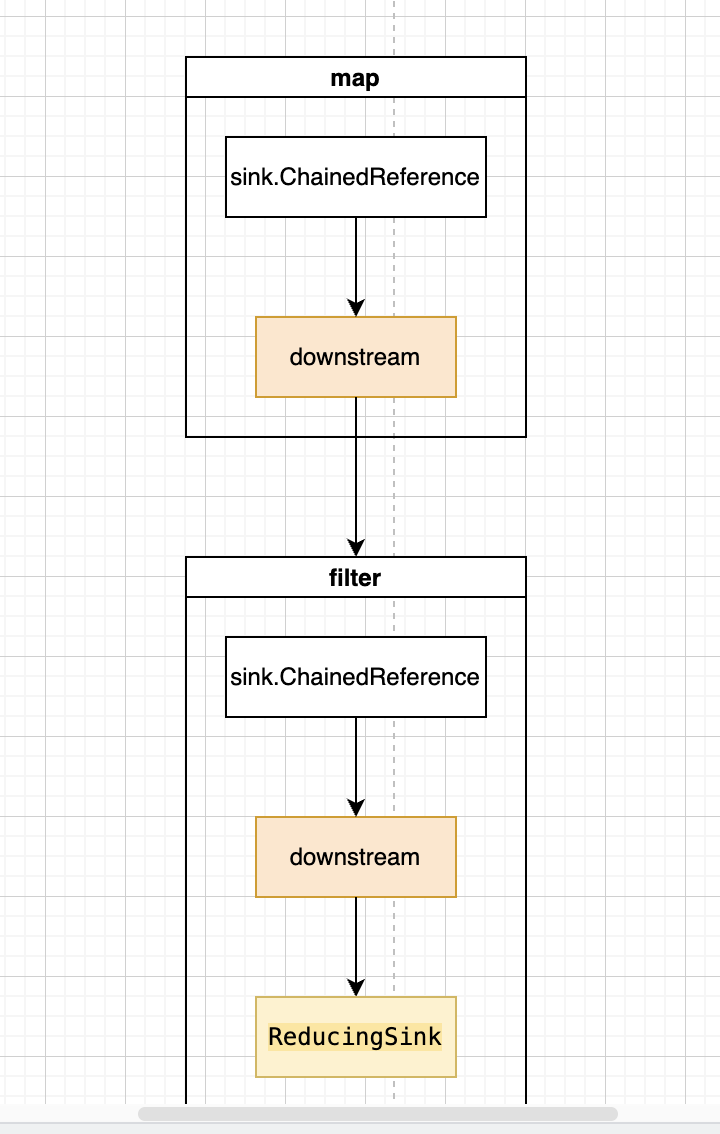
现在来到 copyInto 方法。这个方法两个参数
- 第一个是包装好的 sink 链。
- 第二个是 ArrayListSpliterator 对象
1 |
|
看循环方法
1 | public void forEachRemaining(Consumer<? super E> action) { |
最后,回到开始的collect方法中。evaluate会返回我们刚才一系列操作以后收集到的满足条件的list
1 | public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) { |