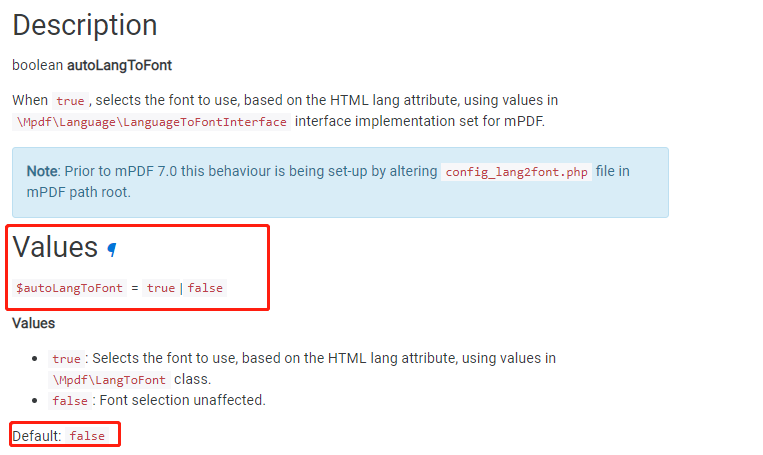
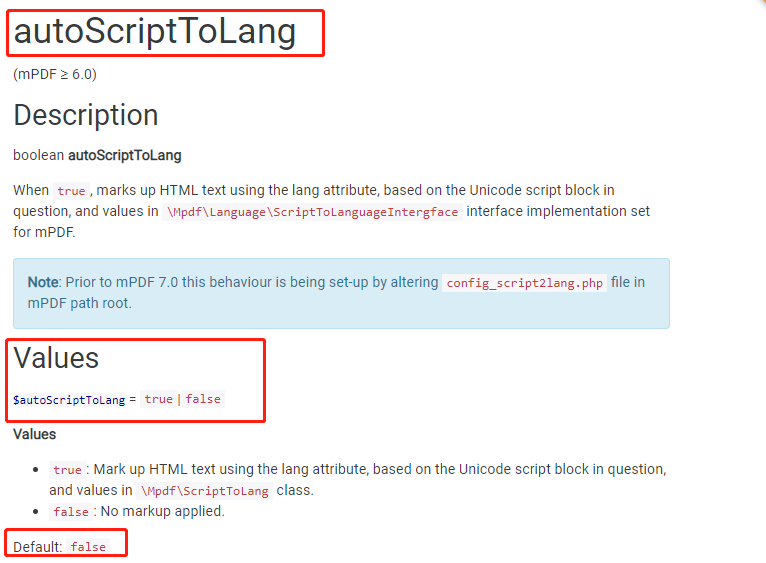
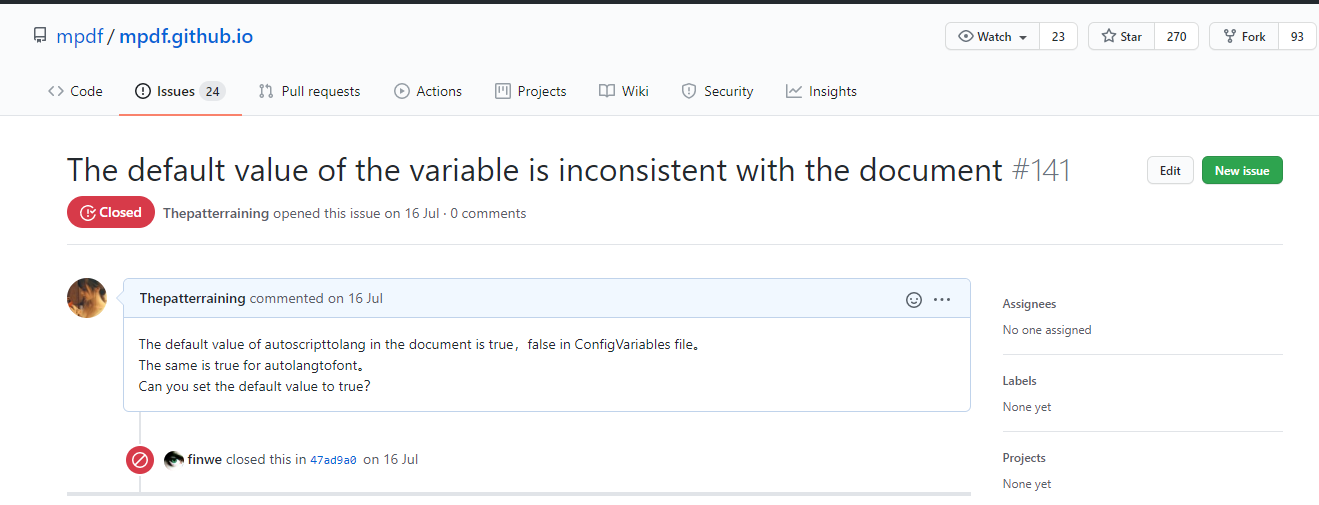
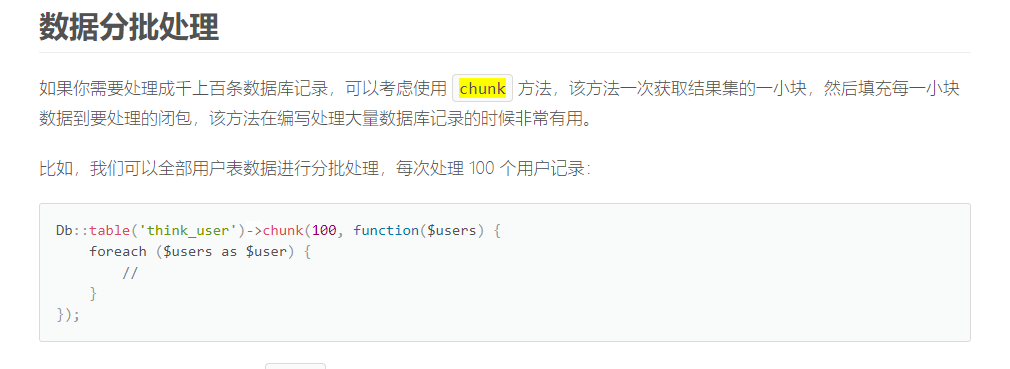
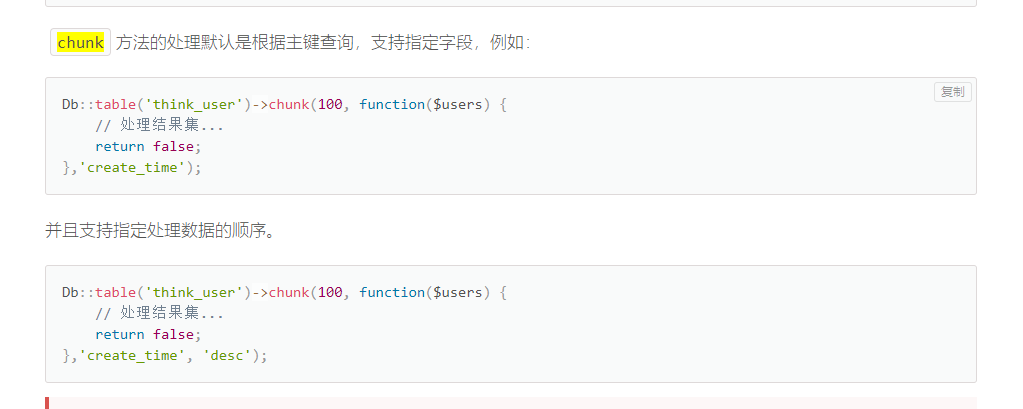
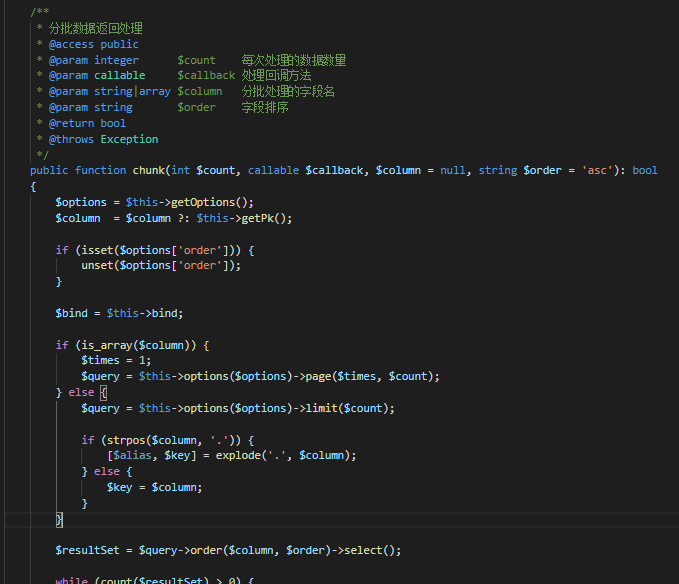
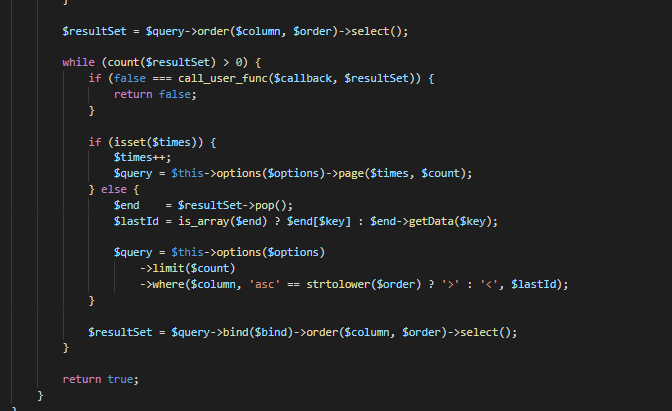
网络原理自顶向下三可靠数据传输原理实现停等协议
这里仅考虑单向可靠数据传输。而不是双向可靠数据传输。
构造可靠数据传输协议
经完全可靠信道的可靠数据传输 rdt1.0版本
首先考虑最简单的版本,底层信道完全可靠。
发送端
发送端应用层只需要调用rdt_send函数。网络层提供了一个函数udt_send来给运输层调用。现在假设udt_send是可靠的。
1 | function rdt_send($data) { |
接收端
接收端网络层只需要调用rdt_rev函数。应用层提供了一个deliver_data函数来接受运输层的数据。
1 | function rdt_rev($packet) { |
有限状态机
再来画一下对应的有限状态机(FSM).
发送端只有一个状态,等待调用。
接收端也只有一个状态,等待调用。
经比特差错信道的可靠数据传输rdt2.0
现在底层信道有可能造成比特的错误。
回想一下打电话的时候,如果我们说的话对方没听清,会怎么样。会再说一遍也就是重传。
那么什么情况下会重传。当接收方说我没听清的时候。
所以在rdt2.0里面我们让接收方接受完信息后回传一个标志,告诉我们正确还是错误。
如果正确,那么我们继续等待调用。
如果错误,那么我们重传。
基于这样重传机制的可靠数据传输协议称为自动重传请求协议(Automatic Repeat reQuest)ARQ,需要下面三个功能
- 差错检测
- 接收方回传ack或者nak
- 重传
发送端
看一下发送端的简单实现
1 | function rdt_send($data) { |
接收端
1 | function rdt_rev($packet) { |
状态机
现在发送端有两个状态
- 等待调用
- 等待返回ack或nak
接收端还是一个状态
- 等待调用
rdt2.0也被称为停等协议。因为发送端处于等待ack状态是不能被上层调用的。
ack受损rdt2.1
从上面的代码可以看出来,接收端发送ack使用的是udt_send函数,这个函数是不可靠的。那么如果我们的ack或者nak损坏了怎么办。
这时候可以像处理损坏分组一样。我们校验ack是否受损,如果受损,那么我们重传分组。
可是重传分组就会造成接收方不知道这个分组我有没有收到过。所以我们需要增加分组序号。
对于停等协议来说,0和1就够用了。因为停等协议只有两个状态,发完会等待ack。
发送端
1 | //序号 |
接收端
1 | //序号 |
状态机
发送端有4个状态
- 等待调用0
- 等待ack0或者nak0
- 等待调用1
- 等待ack1或者nak1
接收端有2个状态
- 等待调用0
- 等待调用1
去掉nak分组的rdt2.2
从上面的代码可以看出来,发送端在接收到nak的时候和丢失ack或者nak的时候都是重传。
所以我们只需要判断ack就可以了。那么同样接收方只需要回传ack就可以了。
这样一来,代码更见简单了。
发送端
1 | //序号 |
接收端
1 | //序号 |
状态机
发送端有4个状态
- 等待调用0
- 等待ack0或者nak0
- 等待调用1
- 等待ack1或者nak1
接收端有2个状态
- 等待调用0
- 等待调用1
经具有比特差错的丢包信道的可靠数据传输rdt3.0
现在底层信道除了会出错,还会丢包了。
如果遇到丢包怎么办呢,也就是接收方接收不到数据了。这个时候也就回传不了ack。
那么可以在发送端加上超时机制。如果长时间没收到ack。那么就重传分组。
发送端
1 | //序号 |
接收端
无变化
状态机
发送端
流水线可靠数据传输协议
停等协议的缺点是性能受限。因为每次要等待上一个ack回来才能发送下一个报文。
而采用流水线就是不等待ack直接发送下一个报文。
这样会有下面的影响
- 必须增加序号范围,因为每个分组必须有序号
- 协议的发送方和接收方两端也许不得不缓存多个分组。
- 所需序号范围和对缓冲的要求取决于数据传输协议如何处理丢失,损坏及时延大的分组。解决流水线的差错恢复有两种基本方法:
- 回退N步(Go Back N)GBN
- 选择重传(Selective Repeat)SR