自定义Analyzer
多字段特性
实现精确匹配
- 增加一个 keyword 字段
使用不同的analyzer
- 不同语言
- pinyin 字段的搜索
- 还支持为 搜索 和 索引 指定不同的 analyzer
Exact Values vs Full Text
Exact Value 包括数字 / 日期 / 具体一个字符串(例如 Apple Store) 精确值 不需要分词
- ES 中的 keyword
全文本,非结构化的文本数据 需要分词
- ES 中的 text
自定义分词
当 ES 自带的分词器无法满足时,可以自定义分词器。通过自己组合不同的组件实现
Character Filter
Tokenizer
Token Filter
通过自己组合上面不同的组件,可以实现出不同的分词器效果。
Character Filter
在 Tokenizer 之前对文本进行处理。可以配置多个进行不同的文本处理。会影响 Tokenizer 的 position 和 offset 信息
下面是一些自带的 Character Filter
- HTML strip 去除 html 标签
- Mapping 字符串替换
- Pattern replace 正则匹配替换
Tokenizer
将原始的文本按照一定的规则,切分为词
下面是一些ES内置的 Tokenizer
- whitespace
- standard
- uax_url_email
- pattern
- keyword
- path hierarchy
也可以用 JAVA 开发插件,实现自己的 Tokenizer
Token filter
将 Tokenizer 输出的单词 进行增加修改删除等操作
下面是ES 自带的
- Lowercase 小写
- stop 停止词
- synonym 近义词
这几个操作简单来说就是
- Character Filter 在分词前进行处理
- Tokenizer 分词
- Token Filter 分词后进行处理
自定义分词器
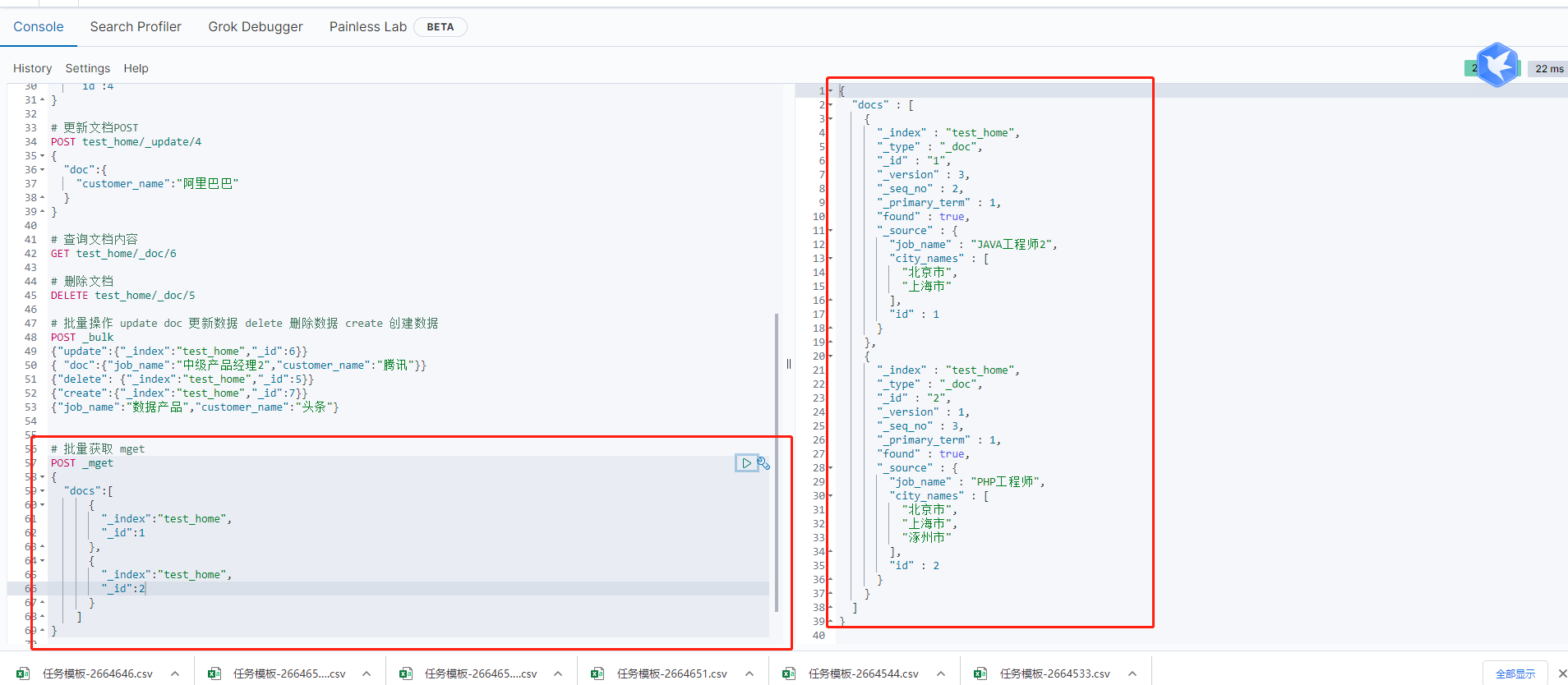
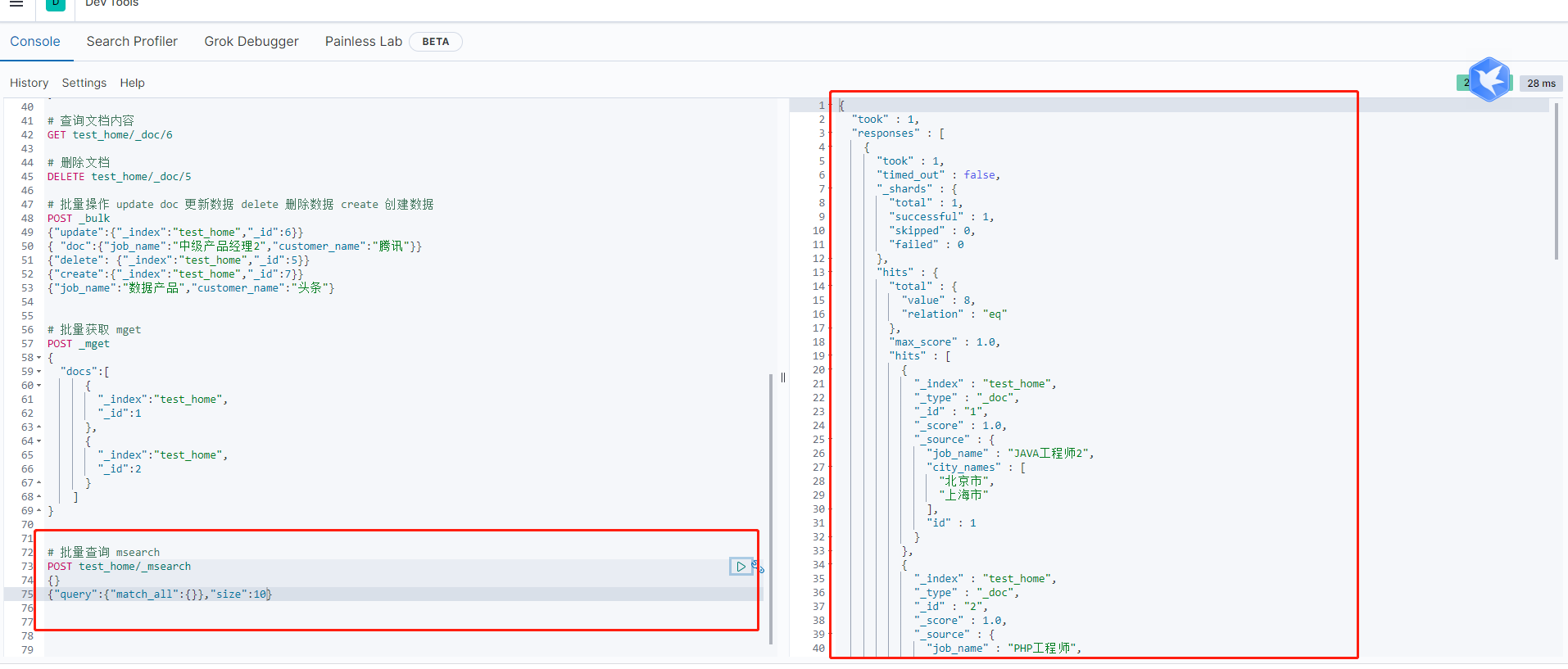
指令
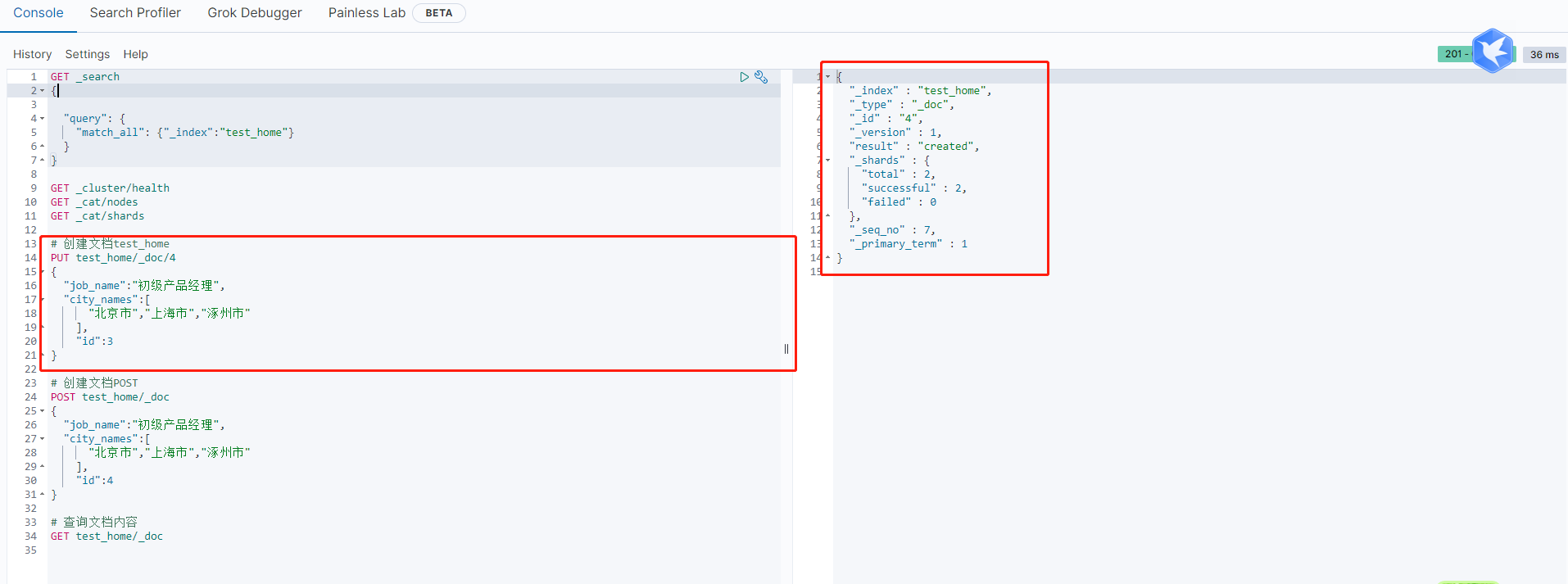
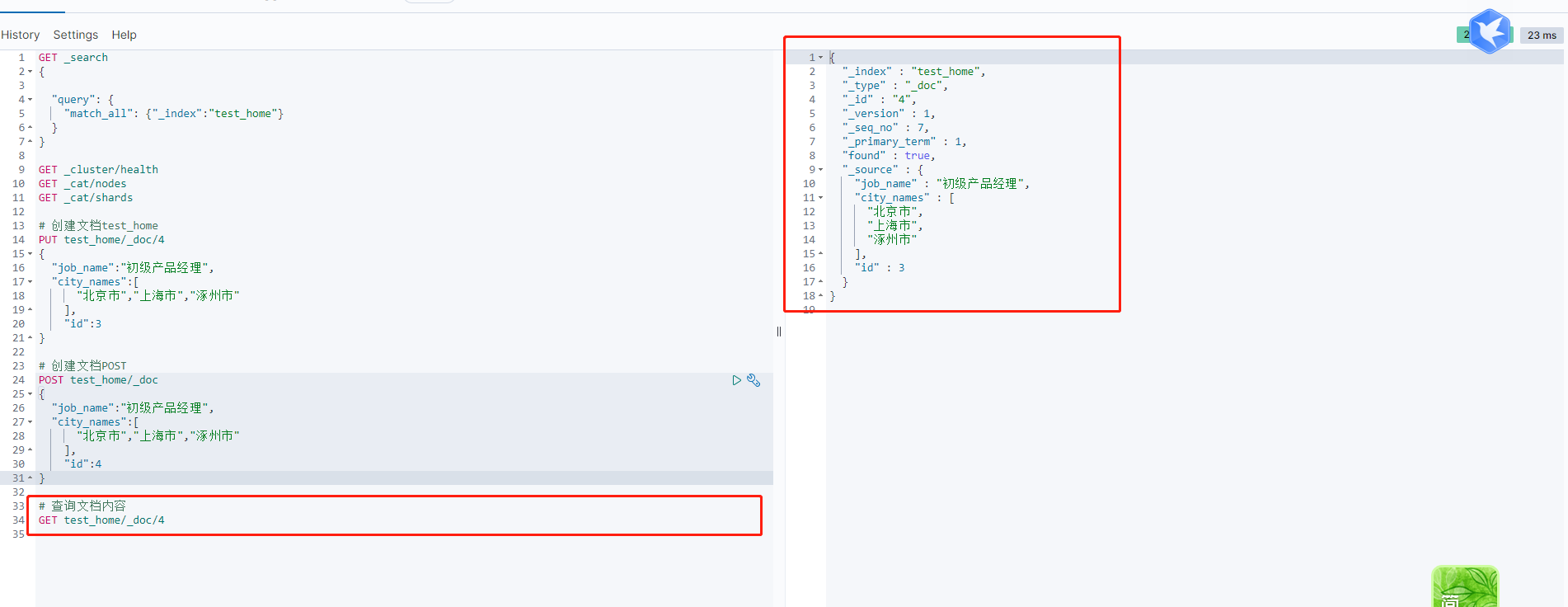
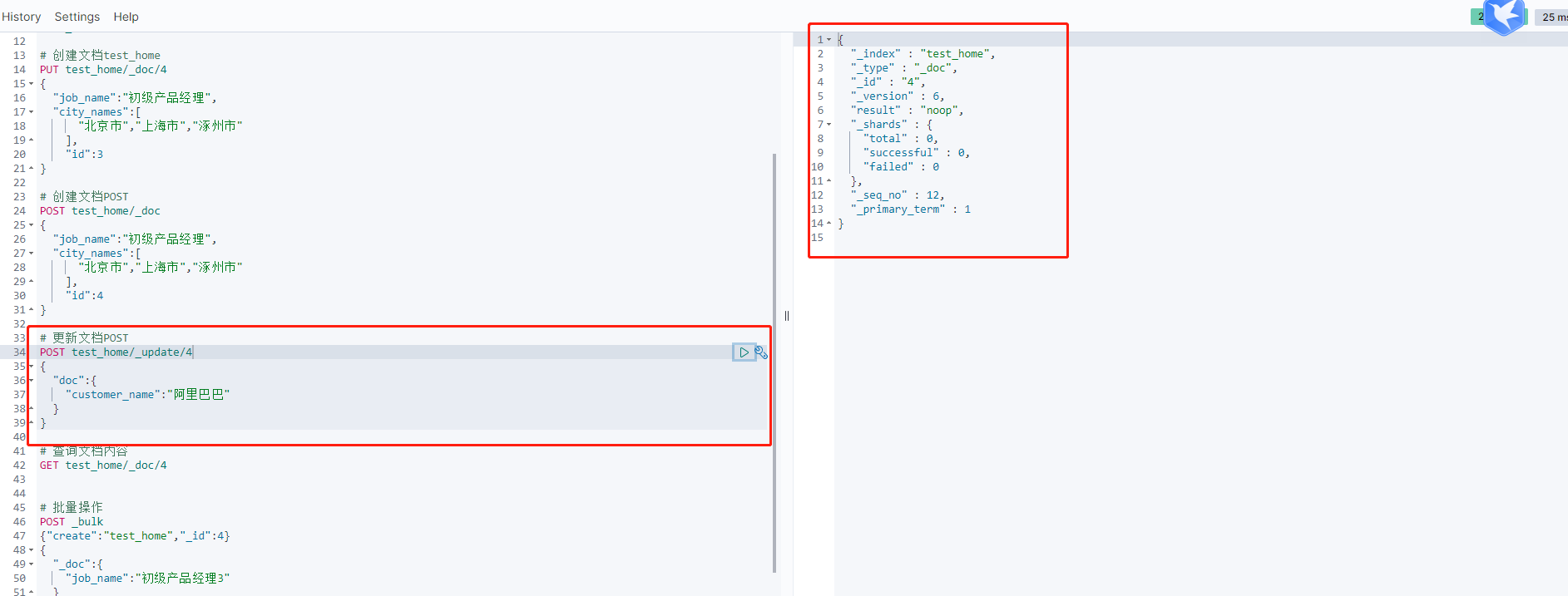
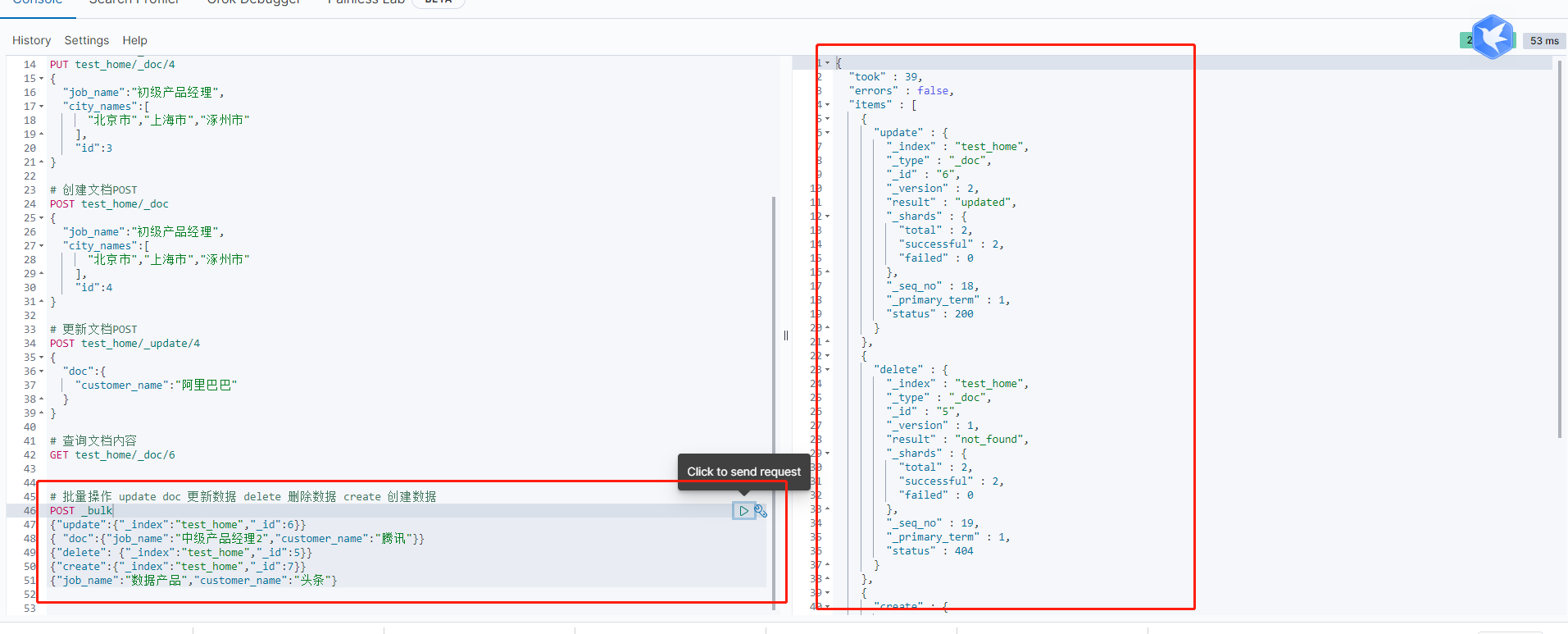
1 | PUT test_home |
极客时间 ES 学习笔记